【논문 읽기】글로벌 얼라인먼트 커널 기반 접근으로 집단 수준 감정 분석
요약
이 블로그는 2022년 IEEE에서 수집한 Analyzing group-level 감성 with global alignment kernel based approach 논문을 참고하여 이해와 기억을 심화시키기 위해 주요 내용을 정리하였습니다.
1. 소개 및 관련 업무
1) 집단감정
사회과학의 관점에서 연구자들은 거의 1세기 동안 소그룹의 구조와 성과를 이해하는 데 더 많은 기여를 했습니다[4], [5], [6], [7]. 주목할만한 것 중 하나는 그룹 감정을 정의하는 것입니다. Barsade와 Gibson은 [5]에서 집단 감정에 대한 공통된 정의를 내렸습니다. 즉, 집단 감정은 한 집단의 사람들의 분위기, 감정 및 성격 영향입니다. 또한 그룹 감정은 팀 프로세스 및 결과에도 영향을 미칠 수 있습니다[8]. 예를 들어, 긍정적인 감정의 증가는 더 큰 협력과 적은 그룹 갈등으로 이어집니다[9]. 결혼식에서 사진을 찍기 위해 포즈를 취하는 가족의 분위기를 감안할 때 자동화 시스템이 가족의 분위기를 인식할 것으로 기대된다.
최근 몇 년 동안 일부 연구자들은 그룹 수준의 원자가 및 각성 예측[10] 및 그룹 수준의 얼굴 표정 인식[11]과 같은 그룹 수준의 감정 인식 작업을 연구했습니다.
- [10]에서 Mou et al.은 이미지에 있는 사람들 그룹의 원자가와 각성을 예측하는 것을 목표로 합니다. 향후 컴퓨터 비전 분야에서 다양한 이점을 가져올 수 있습니다.
- 이미지의 정확한 예측을 기반으로 컴퓨터 비전 시스템은 사람들이 사진 앨범을 만들 후보 사진을 자동으로 선택할 수 있습니다[12].
- 이러한 종류의 시스템은 교육 분야의 사회과학자/연구자들이 협력 학습[13] 등에서 학생들의 상호 작용을 분석하는 데에도 도움이 될 수 있습니다.
특히 [10], [11], [14], [15]에 의해 동기가 부여되어, 우리는 주로 그룹 수준의 감정 인식에서 그룹 수준의 웰빙 강도 추정[15], 그룹 수준의 원자가 및 각성이라는 세 가지 작업에 중점 을 둡니다 . 예측 [10], 그룹 수준의 얼굴 표정 인식 [11].
그룹은 "감정적 실체 및 다양한 감정 표현의 풍부한 소스"로 언급되었습니다[5]. Kelly와 Barsade는 그룹/팀에 많은 감정적 영향이 존재한다고 지적했습니다[6].
[5]에서 Barsade와 Gibson이 논의한 초기 연구에서는 사회과학 연구자들이 그룹 정서를 생성하기 위해 "하향식 접근 방식"과 "상향식 접근 방식"의 쌍을 목표로 해야 한다고 강조했습니다. 하향식 접근 방식은 그룹이 나타내는 감정이 그룹 수준에서 표현되어 구성원 개인이 느끼는 것을 제안하는 반면, 상향식 접근 방식은 개별 그룹 구성원의 고유한 구성 효과를 강조합니다. [5]의 프레임워크를 기반으로 Kelly와 Barsade[6]는 집단 정서가 "상향식" 구성 요소(즉, 정서적 구성 효과)와 "하향식" 구성 요소(즉, 감정적 구성 효과)로 구성된다고 제안했습니다. 문맥) 구성. 즉, 집단감정은 집단구성원이 제시하는 개인수준의 정동요인과 집단의 정서적 경험을 형성하는 집단수준의 정동요인의 조합으로 발생한다.
2) 개론
이미지 또는 비디오에서 군중/팀 행동을 이해하는 것은 최근 컴퓨터 비전 커뮤니티에서 많은 관심을 받았습니다. 컴퓨터 비전 분야의 연구자들은 Barsade et al.[5]과 Kelly et al.[6]이 제안한 군중 감정 이론을 기반으로 이러한 방법을 설계했습니다. 컴퓨터 비전의 방법은 크게 상향식 전략 과 하향식 전략으로 분류할 수 있습니다. 상향식 분류는 에이전트의 속성을 사용하여 그룹 감정을 추론합니다. 반면 하향식 접근법은 그룹 구성원을 설명하기 위해 장면 영향 및 사람 위치와 같은 외적 속성을 고려합니다. 그러나 그룹 정서 분석에 상향식 또는 하향식 방법만 사용하면 이미지에서 유용하고 차별적인 정보가 일부 누락될 수 있습니다.
집단감성분석의 기존 문제점을 해결하기 위해 최근 상향식과 하향식 방법을 결합한 집단감성분석의 하이브리드 모델 방식이 제안되었다 . 이들은 그룹 표현 모델 [12], [15], [18]과 멀티모달 프레임워크 [10], [11], [19], [20], [21], [22], [20]의 두 가지로 나뉩니다 . 삼].
① 그룹 표현 모델은 그룹 수준 이미지 1의 여러 얼굴을 그래프 구조로 인코딩합니다. 여기에는 글로벌 및 로컬 사회적 자산의 모델링 방법이 포함됩니다.
- 그래프 기반 얼굴 속성 및 장면 [24].
- 초기 그룹 표현 모델은 [12], [15]에 등장했습니다. 예를 들어, Dhall 등은 그룹 수준의 행복 강도 추정을 위해 평균, 가중 및 잠재 디리클레 분포에 기반한 그룹 표현 모델의 세 가지 모델을 활용했습니다. 특히 하향식 구성요소로 사건과 집단 환경의 영향을 포함하고, 상향식 구성요소로 집단 구성원 속성(즉, 자발적인 표정, 의복, 연령, 성별)과 함께 집단 구성원을 포함한다.
- [18] 성능 향상을 위해 그룹 수준의 행복 강도 추정을 위한 또 다른 그룹 표현 모델을 제안했습니다. 그들은 하향식 구성 요소로 전체 속성(예: 이웃 그룹 구성원의 영향)을 참조하고, 로컬 속성(예: 개인의 특성)을 상향식 구성 요소로 참조합니다.
그러나 인구 표현 모델은 그래프 구성으로 인해 계산적으로 비효율적이며 얼굴 설명자의 노이즈로 인해 안정적으로 실행될 수 없습니다.
- 예를 들어, [15]에서 잠재 Dirichlet 할당을 기반으로 하는 모집단 표현 모델은 k-평균에서 클러스터 수의 선택에 크게 영향을 받습니다. 즉, k-평균의 클러스터 수가 많으면 기능이 매우 희소해지고 클러스터 수가 적으면 식별 정보가 손실됩니다.
- [18]에서 그래프 구성은 지원 벡터 회귀에 대한 잘못된 예측 문제로 어려움을 겪고 있습니다.
또한 모집단 표현 모델은 잠재 디리클레 분포와 같은 통계적 모델을 통해 이미지 간의 거리를 직접 측정할 수 없습니다.
② 멀티모달 프레임워크는 이미지의 상향식과 하향식 구성 요소를 결합한 그룹 수준의 감정 인식 방법입니다.
-
예를 들어, [11]에서 얼굴 동작 단위와 얼굴 특징은 상향식 구성 요소로 간주되는 반면 장면 특징은 하향식 구성 요소로 간주됩니다.
-
[25]에서 Tan 등은 그룹 수준의 감정을 인식하기 위해 예외 아키텍처를 사용하고 이미지 컨텍스트와 얼굴 특징을 융합합니다. 유사한 작품이 [19], [20], [21]에도 나타납니다.
-
또 다른 흥미로운 다중 모드 연구[10]는 얼굴과 신체 정보를 결합하여 사람들 그룹의 원자가와 각성을 예측합니다. [10]과 같은 다중 모드 프레임워크에 대한 일부 연구는 고정된 수의 얼굴과 몸을 기반으로 그룹 수준의 감정 인식을 위한 조건을 설정하고 특정 그룹에 대한 실험을 수행하는 것을 선호합니다.
-
또한 [11]에서 제안한 특징 부호화 방법은 클러스터링 방법을 이용하여 어휘를 구성하고 각 이미지를 어휘의 빈도 히스토그램으로 표현한다. 이 중간 단계는 분류 단계에서 약간의 오류를 일으킬 수 있습니다. 또한 이러한 방법은 클러스터링 방법의 매개변수 설계에 크게 영향을 받습니다.
인구 표현 모델 및 다중 모드 프레임워크에 대한 경험적 분석은 다양한 작업에 대한 적응성이 부족함을 보여줍니다.
- 예를 들어, 연속적인 조건부 임의 필드가 있는 군중 표현 모델[18]은 원래 군중의 행복 강도를 추정하도록 설계되었기 때문에 감정 범주를 분류하는 데 적합하지 않습니다.
- 또한 조정 가능한 매개 변수가 많기 때문에 계산량이 상대적으로 많습니다. 예를 들어, 다중 모드 프레임워크[26]에는 PCA의 차원, 커널 수 및 패싯 수라는 세 가지 중요한 매개 변수가 포함되어 있습니다.
따라서 다양한 작업의 그룹 수준 감정 인식을 위해 최근접 이웃 분류기 또는 지원 벡터 머신과 같은 모든 분류기에 유연하고 적응적으로 내장될 수 있는 이미지 간의 거리를 직접 계산할 수 있는 효율적이고 효과적인 방법이 있습니까? . 이 문제는 그룹 수준 감정 인식에서 상대적으로 탐구되지 않은 새로운 주제인 이미지 사이의 거리를 계산하기 위한 거리 메트릭을 공식화하는 방법으로 이어집니다(그림 1 참조). 수학적으로 두 이미지는 Σ a = { x 1 , ... , xn } Σ_a = \{x_1,...,x_n\}에스ㄱ={ 엑스1,... ,엑스엔}和Σ b = {y 1 , . . . , ym } Σ_b = \{y_1,...,y_m\}에스ㄴ={ y1,... ,와이엠} , 우리의 목표는 거리 메트릭 함수F ( Σ a ; Σ b ) F(Σ_a;Σ_b)에프 ( 에스ㄱ;에스ㄴ) 이미지 사이의 거리를 더 잘 설명합니다.
3) 저자의 생각
그룹 표현 모델 및 다중 모드 프레임워크와 달리 우리는 이미지 사이의 거리 메트릭 함수 F를 기반으로 하는 새로운 방법 에 초점을 맞추므로 이미지 사이의 거리를 직접 측정하고 이 거리 메트릭을 모든 분류기에 적용할 수 있습니다 . 그림 1에서 볼 수 있듯이 두 이미지 사이의 얼굴 수는 항상 일치하지 않습니다. 즉, 두 이미지는 서로 다른 수의 얼굴을 포함합니다. 유클리드 거리와 같은 거리 측정을 직접 사용하여 두 이미지 Σ a Σ_a 사이의 거리를 측정합니다.에스ㄱ和Σb Σ_b에스ㄴ매우 어렵다.
최근 몇 년 동안 동적 프로그래밍 기반 시계열 커널 세트는 음성, 생물 정보학 및 텍스트 처리와 같은 영역에서 커널을 구성하는 데 사용되었습니다. 이러한 시계열 커널은 두 가지 주요 문제를 해결할 수 있습니다: (1) 시계열은 가변 길이일 수 있습니다.
동작 인식[29,30]과 음악 검색[31]을 위해 동적 시간 워핑[27,28]과 같은 시계열 커널 방법이 연구되었습니다. 그러나 이 거리는 양의 정부호 커널로 쉽게 변환할 수 없으며, 이는 교육 단계에서 커널 머신에 대한 중요한 요구 사항입니다. 시계열 커널의 양의 정부호 문제를 해결하기 위해 Cuturi 등은 **GAK(Global Alignment Kernel)** 방법을 제안하여 음성인식[32]과 필기인식[33]에 적용하였다. 전역 정렬 커널은 시간 정보를 정렬하기 위해 동적 얼굴 표정 인식에 사용되었으며 얼굴 표정 인식에서 그 효과를 입증했습니다[34,35]. 결과는 다른 시계열 커널 방법과 비교할 때 전역 정렬 커널 방법이 가변 길이 시계열을 더 잘 측정할 수 있고 시계열의 인접한 상태 간의 로컬 종속성을 캡처할 수 있음을 보여줍니다.
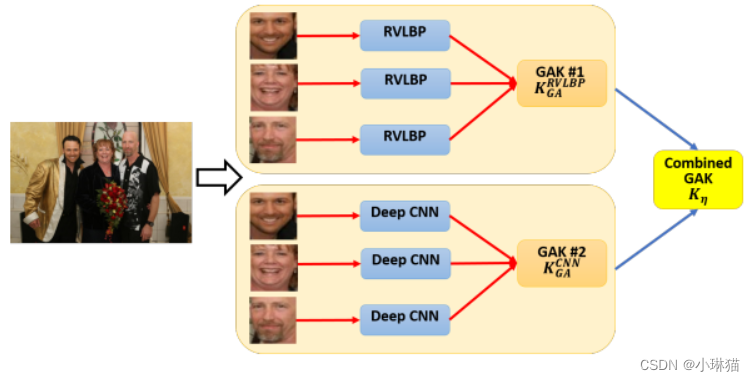
따라서 우리는 두 이미지 사이의 거리를 직접 측정하기 위해 전역적으로 정렬된 커널 기반 방법을 제안한다. 먼저 이미지의 얼굴을 컬렉션으로 간주합니다. 다음으로 전역 정렬 커널을 사용하여 두 세트 Σ a Σ_a를 측정합니다.에스ㄱ和Σb Σ_b에스ㄴ사이의 거리 . 예를 들어, 그림 1의 위 이미지에 표시된 것처럼 이 이미지를 9개의 얼굴을 포함하는 얼굴 시퀀스로 간주할 수 있습니다. 그런 다음 두 이미지 사이의 거리를 측정하는 것은 두 이미지 시퀀스 사이의 정렬로 명시적으로 표현될 수 있습니다 .
그룹 수준의 감정 인식을 위한 전역 정렬 커널을 만들기 전에 전역 정렬 커널이 이미지에서 얼굴의 무질서 문제를 발견했습니다 . 예를 들어, 그림 1에 표시된 것처럼 세 이미지의 문자는 서로 다른 공간 위치를 가지고 있습니다. 이미지에 어떻게 적합하고 좋은 얼굴 설정을 하느냐가 문제다. 그 목적은 안면 장애의 영향을 줄이고 전체 정렬의 효율성을 향상시키는 것입니다. [34], [35]에서 그들은 얼굴 표정 시퀀스 간의 유사성을 측정하기 위해 전역 정렬 커널을 사용했습니다.
실험에 사용된 표정 영상은 중립에서 정점까지를 관찰할 수 있다. 즉, 이 영상들은 표현력에서 동일한 현상을 공유합니다. 이 현상은 동적 시간 워핑과 같은 시계열 커널이 두 얼굴 표정 시퀀스 간의 최적 정렬 경로를 찾는 것을 간단하고 간단하게 만듭니다.
따라서 우리는 전역 정렬 커널의 우수한 차별적 거리 메트릭 기능을 더욱 향상시키기 위해 두 이미지 사이에 일관된 얼굴 세트를 구성하는 방법을 설계합니다. 전역 정렬 커널은 두 얼굴 세트의 시작 노드에서 최적의 검색 경로를 찾습니다 . 좋은 얼굴 세트는 두 이미지 사이의 거리를 더 잘 계산하는 데 도움이 될 수 있습니다. 한편으로 우리는 집단 수준에서의 감정적 행동이 사람들이 질서 있게 행동하는 경로에 제약을 받는다고 가정합니다. 한편, 얼굴 표정 인식에 만연한 핵심 문제는 조명 부족, 머리 자세 변경 등과 같은 가혹한 환경에 의해 얼굴이 영향을 받을 수 있다는 점입니다. 일반적으로 이미지의 얼굴을 설명하기 위해 여러 강력한 기능 설명자를 탐색할 수 있지만 다차원 기능에 대한 여러 기능 세트 간의 거리를 계산하는 것은 쉽지 않습니다. 여기에서 우리는 까다로운 환경에 대한 얼굴 표정 표현의 견고성을 향상시키기 위해 저수준 및 고수준 기능을 개발하고 이를 두 개의 개별 전역 정렬 커널에 공급합니다 . 다음으로 다중 커널 학습이 널리 사용되고 많은 영역에서 좋은 성능을 달성했기 때문에 다중 커널 학습 방법을 사용하여 그룹 수준 감정 인식을 위해 전역적으로 정렬된 두 개의 커널을 결합할 것을 제안합니다[36,37].

4) 기여
- 이미지 사이에 효율적인 얼굴 집합을 구성하기 위해 전역 가중치 정렬 방식을 제안하고 전역 정렬 커널에 대한 중요성을 추가로 평가합니다.
- 두 이미지 사이의 거리를 측정하기 위한 전역 정렬 커널 및 전역 가중치 순위 체계를 제안하고 그룹 수준 감정 인식을 위한 지원 벡터 머신에 포함
- 다중 커널 학습 방법을 사용하여 두 개의 전역 정렬 커널의 최적 가중치를 두 가지 특징에 따라 별도로 학습하고, 지각된 그룹 수준 정서를 추론하기 위해 전역 정렬 커널을 결합한 지원 벡터 머신을 제안합니다.
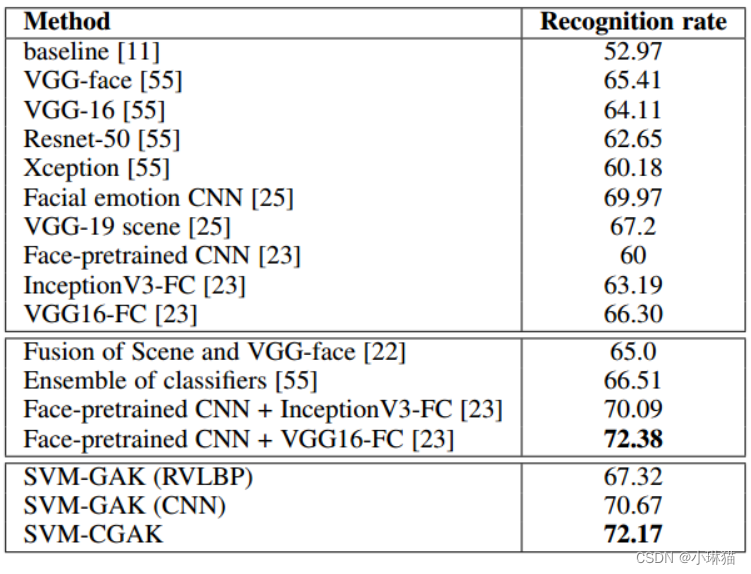
- 3개의 "in the wild" 데이터베이스에 대한 포괄적인 실험은 제안된 방법이 그룹 수준 감정 인식의 세 가지 다른 작업(그룹 수준 웰빙 강도 추정, 그룹 수준 원자가 및 각성 예측 및 그룹 수준의 표정 인식.
5) 질문
데이터 문제: 비디오 부족, 인간 주석, 광범위한 범주
2. 방법
1) 그룹 크기의 가변성은 그룹 감정 인식을 위한 커널 함수 K를 구성하기 어렵고 그룹 크기 고정 전략은 그룹 감정 인식의 적용을 심각하게 제한합니다. 저자는 이것을 "그룹 크기 가변성 문제"라고 합니다.
- Dhall 등은 [11]에서 Bag-of-VisualWords를 사용하여 이미지 특징을 단어로 처리하고 여러 얼굴의 히스토그램을 축적하여 이미지의 특징을 나타냅니다. 그러나 결과 기능은 매우 희소합니다.
- [26]에서 Huang 등은 이미지의 특징을 나타내기 위해 얼굴 패치의 히스토그램을 인코딩하는 정보 집계 방법을 제안했습니다. 이 방법은 이미지의 특징을 희소하지 않게 만들 수 있지만 주성분 분석을 위한 블록 수 및 차원 감소와 같이 수동으로 조정해야 하는 매개변수가 많다는 단점이 있습니다.

2) 전역 정렬 커널과 결합된 지원 벡터 머신
①전체 가중치 정렬: 상대 얼굴 크기, 상대 거리
②거리 측정의 구조
전역 정렬 커널은 두 면 세트 사이의 최적 검색 경로 π를 찾은 다음 최적 경로에 상대적인 거리를 계산합니다. 전역 정렬 커널은 동일한 클래스의 이미지를 서로 가깝게 만들고 서로 다른 클래스의 이미지를 서로 멀리 만들 수 있습니다. 이는 전역적으로 정렬된 커널이 식별 정보를 보존할 수 있음을 의미합니다. 전체적으로 정렬된 커널은 지원 벡터 시스템에 대한 차별적인 정보를 제공할 수 있습니다. 그룹 크기가 다른 두 이미지 사이의 거리를 계산할 때 전역 정렬 커널이 유연하다는 것도 알 수 있습니다.

③ 통합 전역 정렬 커널 기반 벡터 머신 SVM-GAK 지원
- 얼굴에서 RVLBP 및 심층 CNN 기능을 추출하지 마십시오.
- 각각 RVLBP 및 깊은 CNN 기능을 KRVLBP GA 및 KCNN GA로 나타내는 두 개의 전역 정렬 커널을 생성합니다.
- 조합 전략을 사용한 두 개의 코어 융합
3. 실험
가프 2.0