기본형
类型 |
의미 | 바이트 | 최소값 | 최대값 |
sbyte(c#) |
부호 있는 8비트 정수 | 1 | -128 | 127 |
byte(c#) |
부호 없는 8비트 정수 | 1 | 0 | 255 |
short |
부호 있는 16비트 정수 | 2 | -32768 | 32767 |
ushort |
16비트 부호 없는 정수 | 2 | 0 | 65535 |
int |
부호 있는 32비트 정수 | 4 | -2147483648 | 2147483647 |
uint |
부호 없는 32비트 정수 | 4 | 0 | 4294967295 |
long |
부호 있는 64비트 정수 | 8(64비트)/4(32비트) | -9223372036854775808 | 9223372036854775807 |
ulong |
부호 없는 64비트 정수 | 8 | 0 | 18446744073709551615 |
| 십진법(C#) | 128개의 정확한 10진수 값, 28-29개의 유효 숫자 | -7.9 x 10^28 | 7.9 x 10^28 | |
| 더블 | 64비트 배정밀도 부동 소수점 | 8 | 5.0 x 10^-324 | 1.7 x 10^308 |
| 뜨다 | 32비트 단정밀도 부동 소수점 | 4 | -3.4 x 10^38 | 3.4 x 10^38 |
| 숯 | 16비트 유니코드 문자 | 2(C#)/1(C++) | ||
| 부울 | 부울 값 | 1 |
특별한 유형
- 문자열은 32바이트를 차지합니다.
- 포인터는 32비트 시스템에서 4바이트, 64비트 시스템에서 8바이트를 차지합니다.
메모리 정렬
CPU는 구조나 클래스를 저장할 때 메모리 정렬을 수행합니다.
메모리 정렬의 원리: 각 데이터를 min의 정수 배수(현재 데이터 크기, 시스템 정렬 값)에 순서대로 배치합니다. 시스템 정렬 값은 기본적으로 32비트의 경우 4, 64비트의 경우 8이며, 직접 재정의할 수도 있습니다.
다음은 시스템이 32비트라고 가정한 예입니다.
struct asd3{
char a;
char b;
short c;
int d;
};//8字节
struct asd4{
char a;
short b;
char c
int d;
};//12字节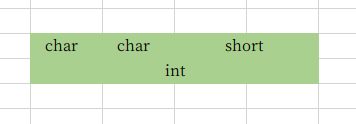

asd3 정렬 프로세스:
데이터 크기는 1이고 0위에 놓입니다.
b의 데이터 크기는 1이고, 1은 그것의 정수배로서 처음에 위치한다.
c의 데이터 크기는 2이고 2는 그것의 정수배이며 두 번째 위치에 있습니다.
d의 데이터 크기는 4이며 4번째 비트에 배치됩니다.
asd4 정렬 프로세스:
데이터 크기는 1이고 0위에 놓입니다.
b 데이터 크기는 2이고, 1은 정수 배수가 아니며, 2는 정수 배수이므로 두 번째 위치에 두십시오.
c의 데이터 크기는 1이고 4는 그것의 정수배로 4번째 자리에 위치한다.
d의 데이터 크기는 4, 5, 6, 7이 그것의 정수배가 아니고 8번째 비트에 위치한다.
struct asd1{
char a;
int b;
short c;
double d;
};//20个字节
asd1 정렬 프로세스:
데이터 크기는 1이고 0위에 놓입니다.
b의 데이터 크기는 4, 1, 2, 3이 그것의 정수배가 아니며 4번째에 위치합니다.
c의 데이터 크기는 2이고 8은 그것의 정수배이며 8번째 비트에 위치합니다.
d의 데이터 크기는 8로 4의 정수배가 아닌 시스템 정렬값 4 , 10, 11보다 크고 12번째 비트에 위치한다.
메모리 정렬의 중요성은 너무 많은 메모리를 낭비하지 않고 데이터 액세스 및 읽기의 효율성을 최대한 향상시키는 것입니다.
학급 크기
먼저 클래스의 크기는 일반 데이터 멤버, 가상 함수, 상속 관계와 관련이 있으며 일반 멤버 함수, 정적 멤버 함수, 정적 데이터 멤버, 정적 상수 데이터 멤버와는 아무런 관련이 없습니다.
상속이 있는 경우 기본 클래스의 크기를 먼저 메모리에 추가하고, 가상 함수가 있는 경우 가상 함수 포인터의 크기를 먼저 계산하며 가상 함수가 아무리 많아도 포인터로만 계산됩니다(기본 클래스 포함) 마지막으로 데이터 멤버 자체의 크기입니다. 위의 계산은 모두 메모리 정렬 원칙을 따릅니다.
특히 빈 클래스 자체는 1바이트를 차지하며, 상속받은 경우에는 0바이트로 계산한다.
class A
{
};
class B
{
char ch;
virtual void func0() { }
};
class C
{
char ch1;
char ch2;
virtual void func() { }
virtual void func1() { }
};
class D: public A, public C
{
int d;
virtual void func() { }
virtual void func1() { }
};
class E: public B, public C
{
int e;
virtual void func0() { }
virtual void func1() { }
};
int main(void)
{
cout<<"A="<<sizeof(A)<<endl; //result=1
cout<<"B="<<sizeof(B)<<endl; //result=16
cout<<"C="<<sizeof(C)<<endl; //result=16
cout<<"D="<<sizeof(D)<<endl; //result=24
cout<<"E="<<sizeof(E)<<endl; //result=40
return 0;
} 1. A는 빈 클래스이므로 크기는 1입니다.
2. B의 크기는 char 데이터 멤버의 크기 + vptr 포인터의 크기입니다. 바이트 정렬로 인해 크기는 8+8=16
3입니다. C의 크기는 두 char 데이터 멤버의 크기 + vptr 포인터의 크기입니다. 바이트 정렬로 인해 크기는 8+8=16
4. D는 다중 상속 파생 클래스 D는 데이터 멤버를 가지므로 빈 클래스 A를 상속할 때 빈 클래스 A의 1바이트 크기는 포함되지 않는다. 그리고 D는 C를 상속합니다. 이 경우 D는 vptr 포인터만 필요하므로 크기는 데이터 멤버에 포인터 크기를 더한 값입니다. 바이트 정렬로 인해 크기는 16+8=24입니다.
5.E는 가상 함수 적용 범위를 포함하는 다중 상속 파생 클래스입니다. 이 경우 크기는 기본 클래스 크기에 로컬 데이터를 더한 값으로 계산됩니다. 바이트 정렬을 고려하면 결과는 16+16+8=40입니다.