단계 차분 이진 검색 및 선형 탐색의 수를 비교하여,이 단계의 이진수를 찾는 발견 된 훨씬 더 빠른 선형 O (N)의 비율을 찾기 위해, O (N 로그)이다.
객관적 알고리즘의 시간 복잡도를 측정 할 수있는 큰 O 표기법 공구는 비교 알고리즘이다.
빅 O는 일반적으로 사용되는 알고리즘과 비교 될 수 빅 O가 느린 다른 사람보다 자신의 알고리즘에 의해 발견, 당신은 한 걸음 뒤로 물러나하고,이를 최적화하는 빠른 종류의 큰 O.로를 설정하는 방법에 대해 생각해야
항상 개선의 여지가 있지만, 더 고려 사항이 아니지만 인코딩을 결정하는 것은 여전히 좋은 전에.
알고리즘, 알고리즘에 일부 변형의 큰 O 성능을 측정하는 성능 때문에한다.
알고리즘을 정렬하는 것은 주제 널리 연구 컴퓨터 과학이다. 오름차순으로 숫자의 무질서한 배열을 구성하는 방법 : 몇 년 동안 지속,이 문제에 초점을 맞추고있다 알고리즘의 수십 개발?
버블 정렬 아주 기본적인 정렬 알고리즘, 다음 단계입니다.
어레이의 두 인접하는 요소들 (1) 포인트 크기를 비교 (배열의 첫 번째 두 개의 요소로부터).
그들은 잘못된 순서 인 경우 (2)의 교환 위치로 (즉, 왼쪽 오른쪽보다 큰 값).
순서가 이미 올바른 경우,이 단계는 아무것도 할 것이라고.
(3) 셀의 오른쪽에 두 개의 포인터.
반복 단계 (1) 및 (2) 단계와, 포인터 배열의 끝에 도달 할 때까지.
모든 방법을 통해까지 교환 할 필요없이 (3) 단계 (4)를 반복 (1), 그 다음 정렬 어레이 A를 사용한다.
여기서 반복 (1) 내지 (3)의 알고리즘의 주요 단계는 전체 어레이의 올바른 순서까지 실행 "사이클"된다 공정 사이클이다.
당신이에 [4, 2, 7, 1, 3] 정렬한다고 가정. 지금 우리의 목표는 오름차순으로 배열에 같은 요소를 생산하는 것입니다 무질서된다.
1주기를 시작합니다.
도 어레이 아래 시작.

단계 1 : 우선, 비교 2, 4. 로 자신의 순서가 잘못 알 수있다.

2 단계 : 자신의 위치를 교환합니다.
단계 3 : 4 및도 7의 비교.
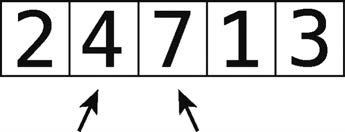
그들의 주문 좋아, 그래서 무엇을 교환하지 않습니다.
단계 4 : 7 및 비교 1.
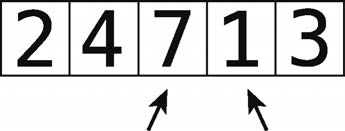
5 단계 : 순서 오류 후 교환.
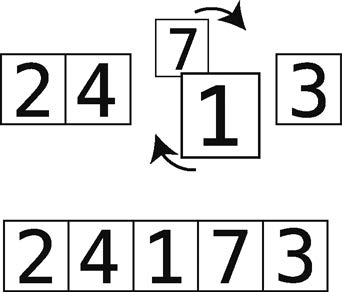
단계 6 : 7 및 비교 3.
7 단계 : 순서 오류 후 교환.
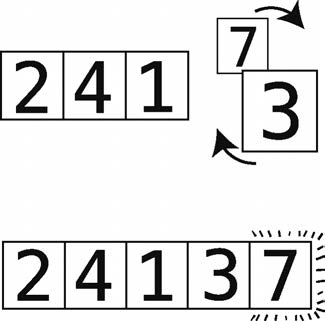
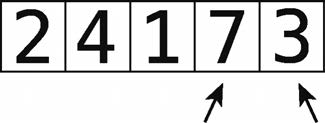
그 오른쪽에 큰 변화 요소왔다 그래서 지금은 오른쪽 7은 올바른 위치에있다. 상기 격자 점선.
올바른 위치에 가장 큰 "위험"입니다 값의 매 사이클 후,하지 정렬이 정확히 이유 버블 정렬이라는 알고리즘이다.
그냥 때문에 더 많이주기를 계속해야하므로, 스왑을 수행하는 여러 번 그주기.
8 단계 : 2와 4에서 시작.
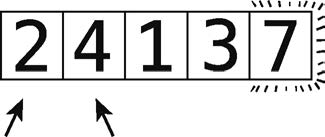
그들은 그래서 다음 단계 순서에 줄 지어있다.
9 단계 : (4) (1)의 비교.
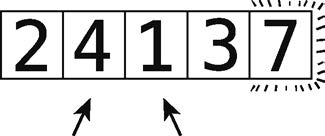
그들이 잘못된 순서로, 그리고 스위칭 : 10 단계.
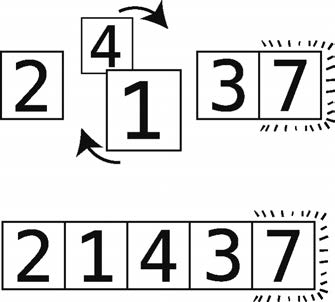
단계 11 : 4 및 비교 3.

12 단계 : 잘못된 순서로 교환.
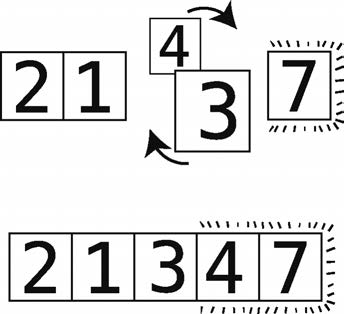
필요가 4와 7을 비교할하기 때문에 7 있기 때문에, 줄을 마지막으로 환생했다. 또한, 넷, 정확한 위치에이주기의 끝을 옮겼다. 이주기의 한 교환보다 더 많은 작업을 수행했기 때문에, 그래서 당신은 사이클을 계속해야합니다.
하자 3 환생.
단계 13 : 1 및 2의 비교.
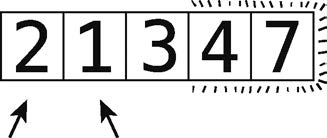
14 단계 : 잘못된 순서로 교환.
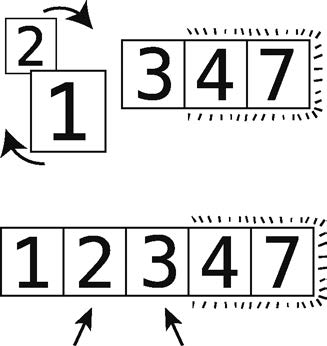
15 단계 : 2와 3의 비교.

스왑이없는 올바른 순서.
그런 다음 올바른 위치 A에 3도 "위험". 때문에 더 스왑을 수행하는 두 번 이상이주기, 그것은 것입니다.
그래서 네 번째 사이클을 시작했다.
단계 16 : 1 및 2의 비교.

스왑이없는 올바른 순서. 그리고 나머지 요소는 분류하고,주기의 끝된다.
환생의 어떤 교류가 없다해서, 우리는 전체 배열이 분류되어 볼 수 있습니다.

파이썬 거품 정렬로 작성 :
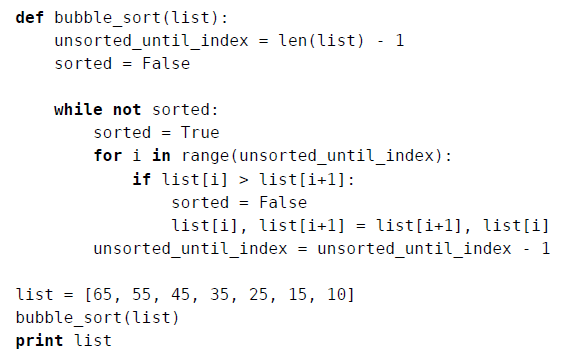
unsorted_until_index = LEN (목록) - 1
변수 unsorted_until_index은 "인덱스를 통해 행하기 전에 데이터가 순서하지 않았다."고 말했다 이 변수는 배열의 마지막 인덱스가 할당되어 있도록 전체 배열은, 순서를 통해 시작 행 아니다.
정렬 = 거짓
이 또한 변수는 배열이 완벽하게 정렬되어 있는지 여부를 기록하는 데 사용됩니다 소트. 물론 처음 가운데는 거짓이어야한다.
while not sorted:
sorted = True
接着是一个while 循环,除非数组排好了序,不然它不会停下来。然后,我们先将sorted初步设置为True。当发生任何交换时,我们会将其改为False。如果在一次轮回里没有做过交换,那么sorted 就确定为True,我们知道数组已排好序了。
for i in range(unsorted_until_index):
if list[i] > list[i+1]:
sorted = False
list[i], list[i+1] = list[i+1], list[i]
在while 循环里,还有一个for 循环会迭代未排序元素的索引值。此循环中,我们会比较相邻的元素,如果有顺序错误,就会进行交换,并将sorted 改为False。
unsorted_until_index = unsorted_until_index - 1
到了这一行,就意味着一次轮回结束了,同时该次轮回中冒泡到右侧的值处于正确位置。因为unsorted_until_index 所指的位置已放上了正确的元素,所以减1,以便下一次轮回能略过该位置。
一次while 循环就是一次轮回,循环会持续直至sorted 确定为True。