첫째, 데이타베이스 고유의 문
데이터베이스를 작성하십시오
DATABASE의 CREATE 임팔라에서 새 데이터베이스를 만들 문을.
NOT은 데이터베이스 _있는 경우 DATABASE를 만들;
여기에서, IF NOT이 존재하는 선택적 절입니다. 우리는 같은 이름이없는 경우이 절을 사용하는 경우 데이터베이스를 기존의 때, 지정된 이름의 데이터베이스를 생성합니다.

임팔라 임팔라 기본 사용자가 수행하는 작업은 불충분 한 권한 문제, 해결책을보고됩니다
하나 : 지정된 폴더에 부여 된 HDFS 권한
하둡 FS -chmod -R 777 HDFS : // 노드 1 : 9000 / 사용자 / 하이브
2 : 거짓 HDFS-site.xml 파일에 대한 권한을 설정하는 haoop 구성 파일

두 가지 방법이 될 수 있습니다.

기본값은 여러 창고의 폴더 경로 하이브에 새 데이터베이스 이름을 만듭니다
/user/hive/warehouse/ittest.db
데이터베이스를 만들 때 당신은 또한 HDFS 경로를 지정할 수 있습니다. 경로의 참고 권한.
하둡 FS -mkdir -p / 입 / 임
하둡 FS -chmod -R 777 / 입 / 임

| 행 형식은 '\ t'위치로 종료 필드를 구분 외부 테이블 T3 (INT 번호, 이름 문자열 연령 int)를 작성 '/ 입 / 임 / 외부'; |
2, 데이터베이스를 삭제
임팔라의 DROP 데이타베이스 문은 임팔라에서 데이터베이스를 삭제합니다. 데이터베이스를 삭제하기 전에, 모든 테이블에서 제거하는 것이 좋습니다.
당신이 모두 삭제를 사용하는 경우, 임팔라는 지정된 데이터베이스 테이블을 삭제하기 전에 제거됩니다.
DROP 데이터베이스 샘플 캐스케이드 ;


둘째, 테이블 별 문
하나는 만들기 표 문을
TABLE CREATE 문에서 원하는 데이터베이스가 임팔라에서 사용하는 새 테이블을 만들 수 있습니다. 테이블 이름을 지정하고 그 열 및 열 데이터 유형을 정의 할 필요가있다.
임팔라 데이터 유형을 지원하는 하이브 1, 같은 SQL 타입 Java 형 지지체에 첨가한다.
| NOT은 database_name.table_name을 존재하는 경우 (테이블을 생성 컬럼 1의 DATA_TYPE, 2 열의 DATA_TYPE, 3 열을 DATA_TYPE, ......... columnN의 DATA_TYPE ); |
CREATE TABLE IF NOT은 my_db.student (이름 STRING, 연령 INT, 연락처 INT)를 EXISTS;
![]()
하이브과 일치하는 테이블의 데이터 저장 경로 기본 건설. 또한 테이블의 건설시 위치를 통해 특정 경로를 지정할 수 있습니다, 관심을 지불 할 필요가 인권 문제를 HDFS.

2, INSERT의 문
: 임팔라 INSERT 문은이 개 조항이 INTO 및 덮어 쓰기 . 새로운 데이터 레코드에 삽입 덮는 기존 레코드를 덮어.
| TABLE_NAME에 삽입 (1 열, 2 열, 3 열, ... columnN) 값 (값, 값 2, VALUE3 ... 값 N); TABLE_NAME 값 (값 1, 값, 값 2)으로 삽입; |
여기서, 1 열은 2 열은 ... columnN 당신이 테이블에 데이터를 삽입 할 열 이름입니다. 값은 또한 열 이름을 지정하지 않고 추가 될 수 있지만, 테이블 값의 열 순서와 동일한 순서를 보장한다.
예를 들면 :
테이블 직원 (ID INT, 이름 STRING, 연령 INT, 주소 STRING, 급여 BIGINT)을 생성;
종업원 값으로 인서트 (1 '라 메쉬', 32 '바드', 20000);
종업원 값으로 인서트 (2 'Khilan', 25 ', 델리, 15000);
종업원 값으로 삽입 (3 'Kaushik이'23 '코타'30000);
직원 값에 삽입 (4, 'Chaitali', 25, '뭄바이', 35000);
종업원 값에 삽입 (5 'Hardik', 27 '보팔'40000);
종업원 값에 삽입 (6 '코멀', 22 ', MP', 32000);

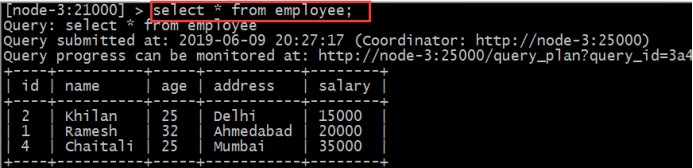
덮어 쓰기 사이에서 커버 절 오버레이 테이블 의 모든 레코드 . 테이블에서 기록이 영구적으로 삭제 덮여.
덮어 쓰기 직원 값을 삽입 (1, '램', 26 일 '비 샤카 파트 남', 37000);

3, SELECT 문
임팔라 은 SELECT 문은 하나 개 이상의 데이터베이스 테이블에서 데이터를 추출하는 데 사용됩니다. 이 쿼리는 테이블로 데이터를 반환합니다.
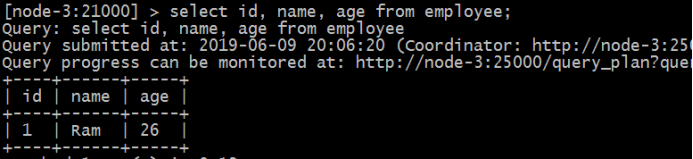
4, DESCRIBE 문
임팔라는 설명 문은 테이블의 설명을 제공하는 데 사용됩니다. 이 문장의 결과는 이름과 데이터 유형 컬럼으로 테이블에 대한 정보가 포함되어 있습니다.
TABLE_NAME을 설명;

또한, 당신은 또한 하이브 조회 테이블 메타 데이터 정보 문을 사용할 수 있습니다.
포맷 TABLE_NAME을 DESC;

5, ALTER 테이블
의 임팔라 바꿔 테이블 주어진 테이블의 메이크업 변화에 대한 문. 이 문장, 우리는, 삭제를 추가하거나 테이블의 기존 열을 수정할 수 있습니다, 당신은 그 이름을 바꿀 수 있습니다.
테이블의 이름을 바꿉니다
ALTER 표 [old_db_name.] old_table_name 의 이름을 바꾸려면
[new_db_name.] new_table_name
테이블 컬럼에 추가 :
ALTER TABLE 이름 추가 COLUMNS (col_spec [col_spec ...])
테이블에서 열을 제거합니다
ALTER 테이블 이름 DROP [COLUMN] COLUMN_NAME
이름을 변경하고 컬럼의 종류 :
ALTER TABLE 이름 변경 COLUMN_NAME의 NEW_NAME의하는 new_type

6, 삭제, 잘라 내기 테이블
임팔라 드롭 임팔라 기존 테이블을 제거하기 위해 표 문을. 이 문은 HDFS 내부의 파일 삭제는 테이블의 기초가됩니다.
참고 : 테이블을 삭제 한 후, 테이블에서 사용할 수있는 모든 정보가 영원히 손실되기 때문에이 명령을 사용할 때는주의해야합니다.
DROP 테이블 database_name.table_name;

임팔라 자르기는 표 문은 기존 테이블에서 모든 레코드를 삭제합니다. 예약 된 테이블 구조.
또한 전체 목록을 삭제하려면 DROP TABLE 명령을 사용할 수 있지만, 그것은 당신이 어떤 데이터를 저장하려는 경우, 당신은이 테이블을 다시 만들어야합니다, 데이터베이스에서 테이블의 전체 구조를 삭제합니다.
잘라야 테이블 _;

7, 보기보기
보기 만 임팔라는 데이터베이스에 저장 연관된 이름을 가진 쿼리 언어 문을. 그것은 테이블의 형태로 미리 정의 된 SQL 쿼리의 조합을 기반으로합니다.
테이블 또는 선택된 행을 포함 할 수있는 모든 행을 볼 수 있습니다.
보기 만들기 IF NOT은 선택 문으로 VIEW_NAME 존재
뷰보기, 쿼리보기보기 만들기
VIEW IF NOT이 선택 이름, 직원의 연령 AS employee_view EXISTS CREATE;
수정보기
Select 문에 대한 ALTER VIEW의 database_name.view_name
삭제보기
DROP VIEW의 database_name.view_name;

8, 주문 조항에 의해
임팔라 ORDER BY에 오름차순 또는 하나 이상의에 따라 종류의 데이터를 내림차순으로 절 열. 기본적으로 일부 데이터베이스 쿼리는 오름차순으로 발생합니다.
COL_NAME에 의해 TABLE_NAME의 ORDER SELECT * FROM
[ASC | DESC] [NULLS FIRST | NULLS LAST]
데이터 목록은 각각 오름차순 또는 행 키워드 ASC 또는 DESC 내림차순 될 수 있습니다.
우리는 NULLS FIRST를 사용하는 경우, 테이블의 모든 값은 널 상부 행에 배치되어, 우리는 NULLS LAST를 사용하는 경우, 배치되는 마지막 행 NULL 값을 포함한다.

9 그룹 BY 절
임팔라 는 GROUP BY SELECT 문의 절 협력에 사용되는 동일한 데이터 그룹으로 배치되어있다.
TABLE_NAME 그룹 BY의 컬럼 이름에서 데이터를 선택;
10, HAVING 절
임팔라 갖는 절은 필터 결과가 최종 결과에 그 조건을 표시하는 그룹을 지정할 수 있습니다.
일반적으로, GROUP BY 절과 절을 갖는 그것은 GROUP BY 절에 의해 생성 된 세트 조건에 배치됩니다.
11 한계 오프셋
임팔라는 제한하는 결과 세트에 행 절의 수는 필요한 수에 제한됩니다, 즉, 쿼리 결과 세트는 더 지정된 제한을 기록 이상 포함되어 있지 않습니다.
일반적으로, 0부터 시작하는 행의 선택 쿼리를 결과 집합. 은 Using 오프셋 절을 , 우리는 출력을 고려해서 결정할 수 있습니다.

12 절과
쿼리가 너무 복잡하면, 우리는 복잡한 부분에 대한 별명을 정의하고 쿼리에 포함 절을 그들에게 임팔라를 사용할 수 있습니다.
뿐만 아니라 X (1 선택), Y (2 선택) (X, Y의 조합으로부터 선택 *)와;
예를 들어 : 절 사용은 나이가 25 명 직원과 고객의 기록을 표시합니다.
같은 T1과 (고객 SELECT * FROM 곳 연령> 25)
같은 T2 (직원에서 선택 * 어디 연령> 25)
(T1 조합에서 * T2에서 선택 * 해당);
13 구별
임 구별 연산자 중복 값을 제거함으로써 상기 고유 값들을 획득하는데 사용된다.
테이블 _ 구별 열을 ... 선택;
