記事のディレクトリ
Windows仮想マシン構成のHadoopハイブ(B)
完全分散:Hadoopのデーモンは、クラスタ上で実行する
すべてのデーモンは少し小さいマシンの同じマシン上で実行されている消費するシングルノードクラスタ上で実行しているのHadoop:疑似分散。
Xftpは、Linuxにアップロードしたパッケージを使用するには
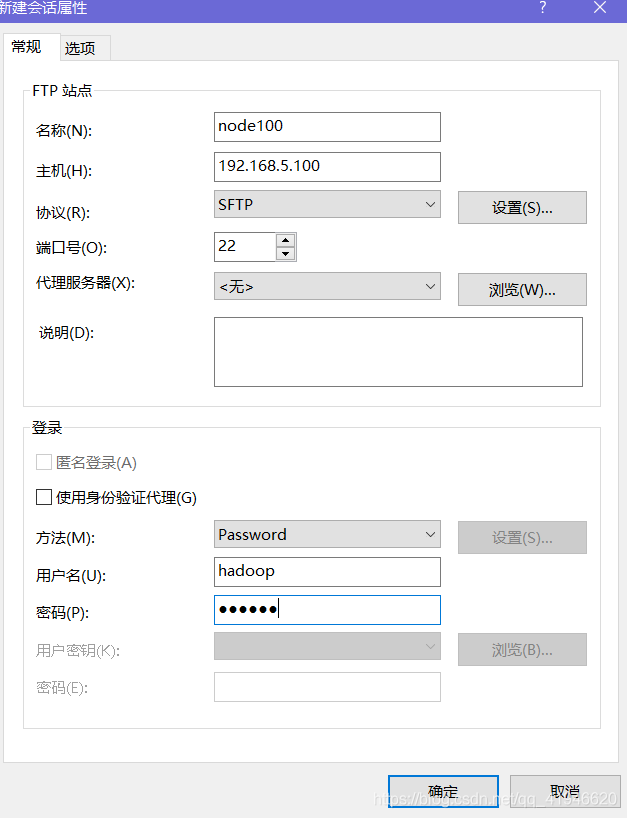
私たちは、Hadoopのを使用して、rootユーザーのログイン、ユーザログを使用していない、Hadoopのソフトウェアは次のディレクトリに転送されます。
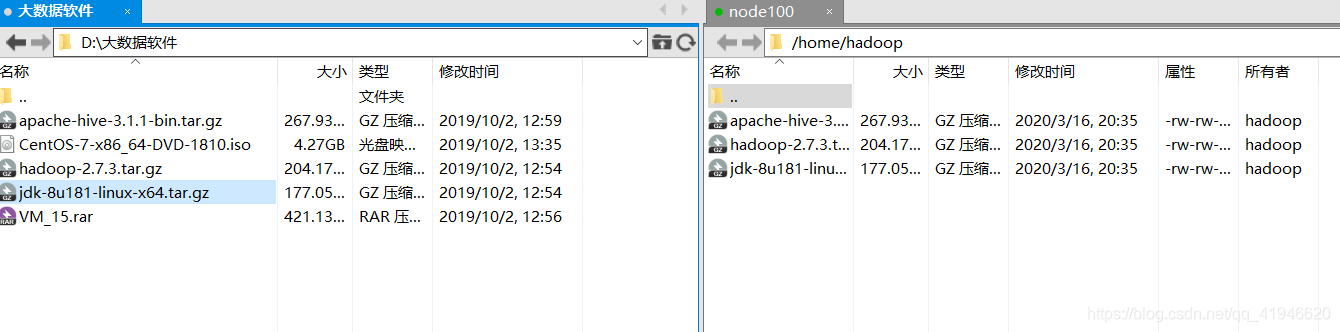
チェックをxshellにこれらのソフトウェアがあるかどうか:
密なログインの二つの自由準備
その後、クラスタは、疑似分散されていない場合、および複数のコピーは、例えば、3を保存すると、ファイルを保存し、その後、彼はあなたがファイルnode101をダウンロードしたい場合は、ダウンロード時間に異なるブロックからダウンロードされます。理由は、パスワードなしのログイン、あなたはパスワードを私は受け入れることができますパスワードを失ったすべての3つのノードを入力する必要がある場合に構成する、高密度のログインを回避しない場合。ダウンロードに入力する必要がありますが、異なるマシン上に3つのファイル10000個のブロック、ブロックならば、あなたがする必要がありますそんなにコードを入力して、私の心は非常にクラッシュされていません。
- ルートに切り替えます。
su - root - 2閉じるのselinux:
vim /etc/selinux/configプレスiモード、インサート、SELINUX=disabled
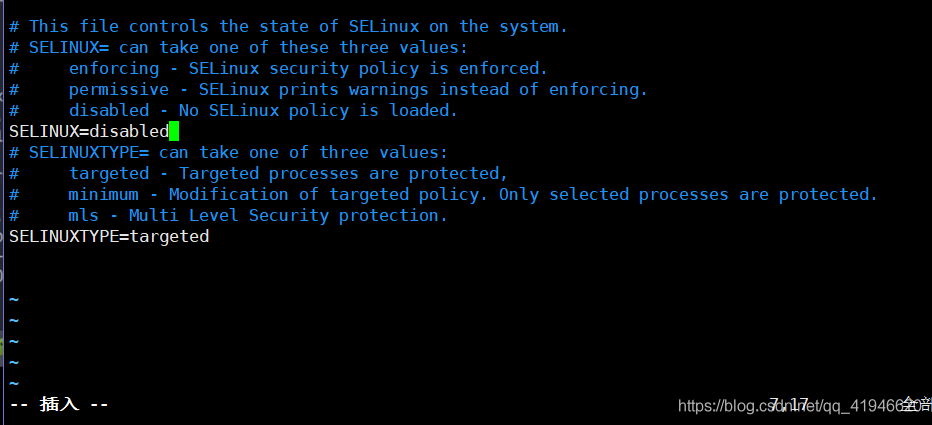
ESC :wq画面を保存して終了するにはクリアされます.clear
- に切り替える3のHadoopユーザー:
su - hadoop - Hadoopののホームディレクトリに4:
cd
Hadoopのホームディレクトリを入力した後、次のコマンドを入力します。
注:他のマシンにsshの平均対数意味、私は今node100午前、101にログオンするには、クラスタ内のログ、ログインすることができます別のコンピュータに相当するものを入力することもできます。
ssh-keygen -t rsa[4 Enterキーを押します入力した後も]
ssh node100[はい、ユーザのパスワード入力のHadoop]
ssh-copy-id node100[ユーザーのパスワードのHadoopを入力してください]
成功のためのチェック:ssh node100ログオンするためのパスワードを必要としません
/ opt /モジュールにパッケージを三抽出
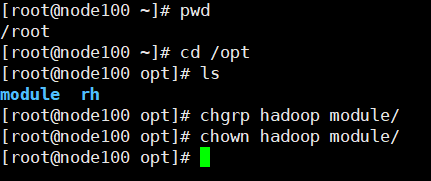
ルートに切り替えるには、optにモジュール内のフォルダーを作成します。
rootユーザーでのoptフォルダへの切り替えを:cd /opt/
モジュールのフォルダを作成します。mkdir module
Hadoopのに所有者とすべてのグループを変更します。
chgrp hadoop module/
chown hadoop module/
バックホームディレクトリが抽出開始します。
cd
tar -zxvf ./jdk-8u181-linux-x64.tar.gz -C /opt/module/
tar -zxvf ./hadoop-2.7.3.tar.gz -C /opt/module/
tar -zxvf ./apache-hive-3.1.1-bin.tar.gz -C /opt/module/
4つのエディションの環境変数:
cd ホームディレクトリに、これは隠しファイルです.bash_profileの
vim ~/.bash_profile

(小文字のOによると、カーソルの最後の行)は、ファイルの最後に追加され
JAVA_HOME = / OPT / Module1の/ jdk1.8.0_181
HADOOP_HOMEある= / OPT / Module1の/ Hadoopの-2.7.3
HIVE_HOME = / OPT / Module1の/アパッチ、ハイブビン- 3.1.1
PATH =
HOME / binに:
HADOOP_HOME / binに:
HIVE_HOME / binに
輸出JAVA_HOME
輸出HADOOP_HOME
輸出HIVE_HOME
輸出PATHの

ESC:WQ
ファイブを有効にするには、ファイルの環境変数をリロードします
Hadoopのホームディレクトリで
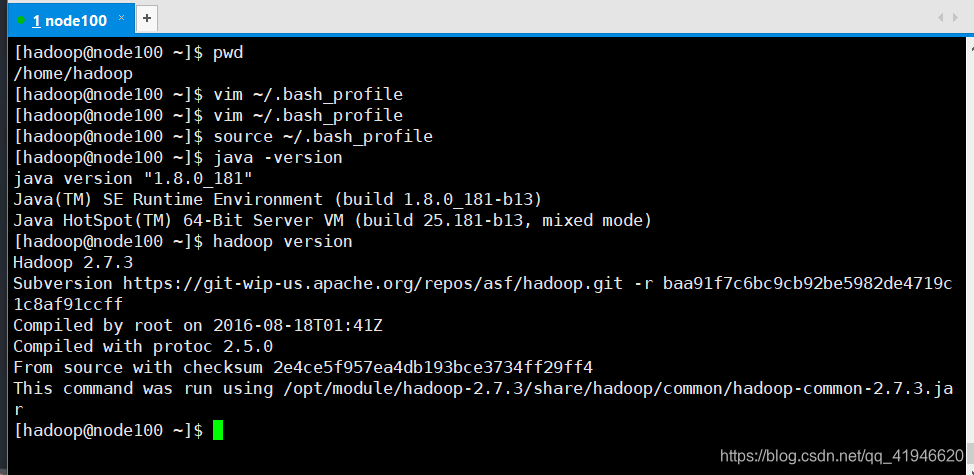
source ~/.bash_profile
正しい確認します:
java -version
hadoop version
シックス設定ファイルを変更するのHadoop:
Hadoopのユーザーに:
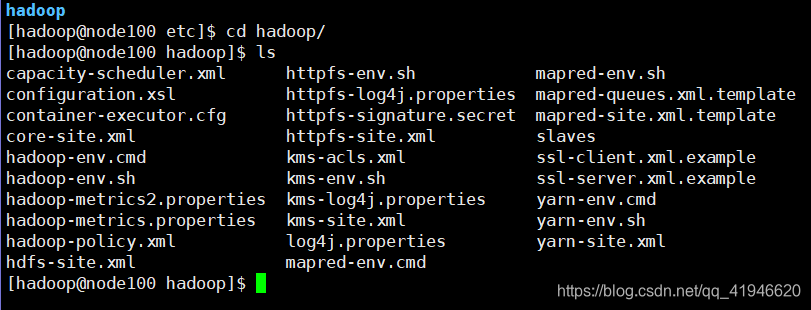
cd /opt/module/hadoop-2.7.3/etc/hadoop

。:ETCが、我々が見てみるなどに設定ファイルを保存することです

:行く、Hadoopのファイル
、私たちはそれらのいくつかを変更する必要がありますコピーして、次のコマンドを貼り付ける
./hadoop-env.sh 1.vim
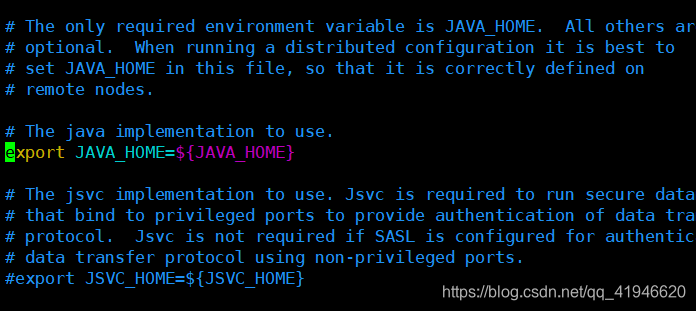
にカーソルを置きますがコードの変更(またはNotes)を次のように!注jdk1.8.0_181を対応するように、ファイル名のバージョンで抽出した後、
輸出JAVA_HOME =は/ opt /モジュール/ jdk1.8.0_181
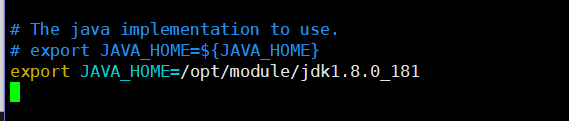
:WQ
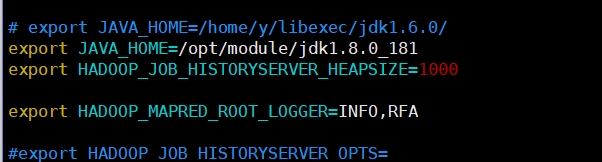
2.vim ./mapred-env.sh
輸出JAVA_HOME =は/ opt /モジュール/ jdk1.8.0_181
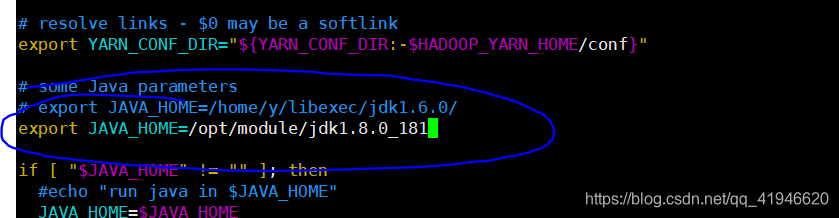
3.vim ./yarn-env.sh
輸出JAVA_HOME =は/ opt /モジュール/ jdk1.8.0_181
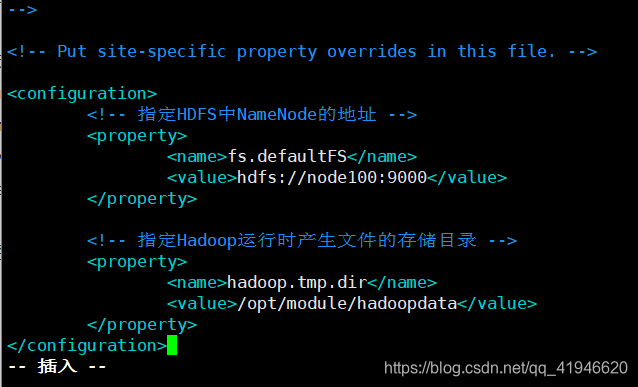
4.vim ./core-site.xml
最初の行の中間と最後から二番目のラインの逆数、キーを押しO中

<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node100:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoopdata</value>
</property>
コピー&ペーストするだけでなく、自分のマシン名に応じて変更するNode100の真ん中に空白のコピー、:
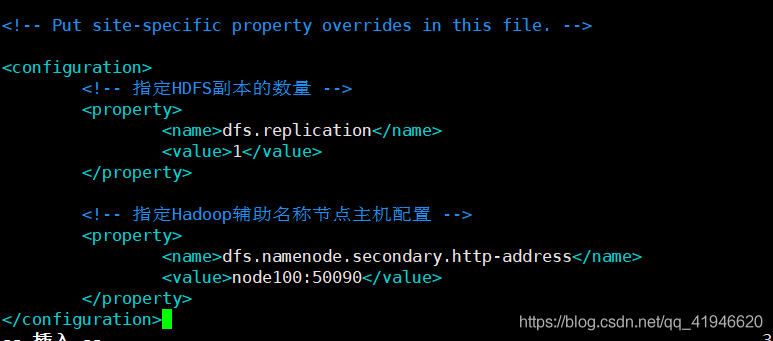
5.vim ./hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node100:50090</value>
</property>
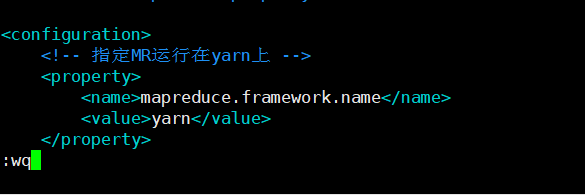
6.cp ./mapred-site.xml.template ./mapred-site.xml
過去に最初のコピー、[編集]コピー後のファイル

のvim ./mapred-site.xml(Z iが指定された場所にある特定のノートを押す必要があります編集)
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
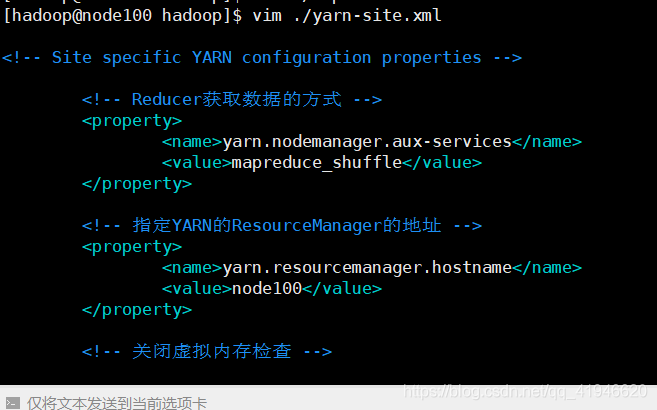
7.vim ./yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node100</value>
</property>
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
8.vim ./slaves
NODE100に、ローカルホスト(小文字は通常モードDD)削除
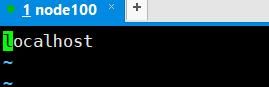
NODE100
九、Hadoopクラスタの書式設定
注:このコマンドは、フォーマットが問題になり、再度フォーマットすることができます!
node100このマシン上で実行:HDFS名前ノード-format
良いフォーマット後Hadoopクラスタを有効または無効にすることができます
テン、起動/シャットダウンHadoopクラスタの
このマシン上で起動、実行node100:start-all.sh
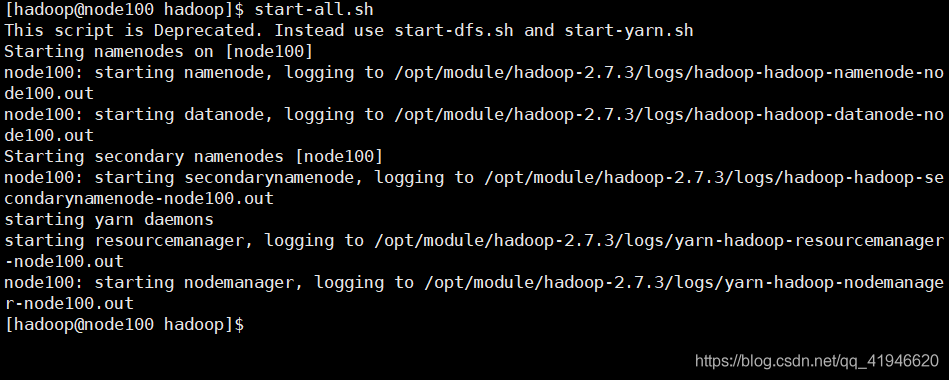
JPS:操作が正常かどうかを確認
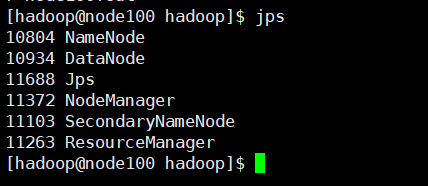
1つ以上のはあまり機能しません、6つのプロセスの合計を
クローズド実行するnode100このマシンの場合:stop-all.sh
XIは、クラスタ検証します
- 通常のページかどうかを確認してください:お使いのコンピュータのブラウザに以下のアドレスを入力してください:IPアドレスは、端末ifconfigコマンドで見つけることができます
192.168.5.100:50070
192.168.5.100:8088
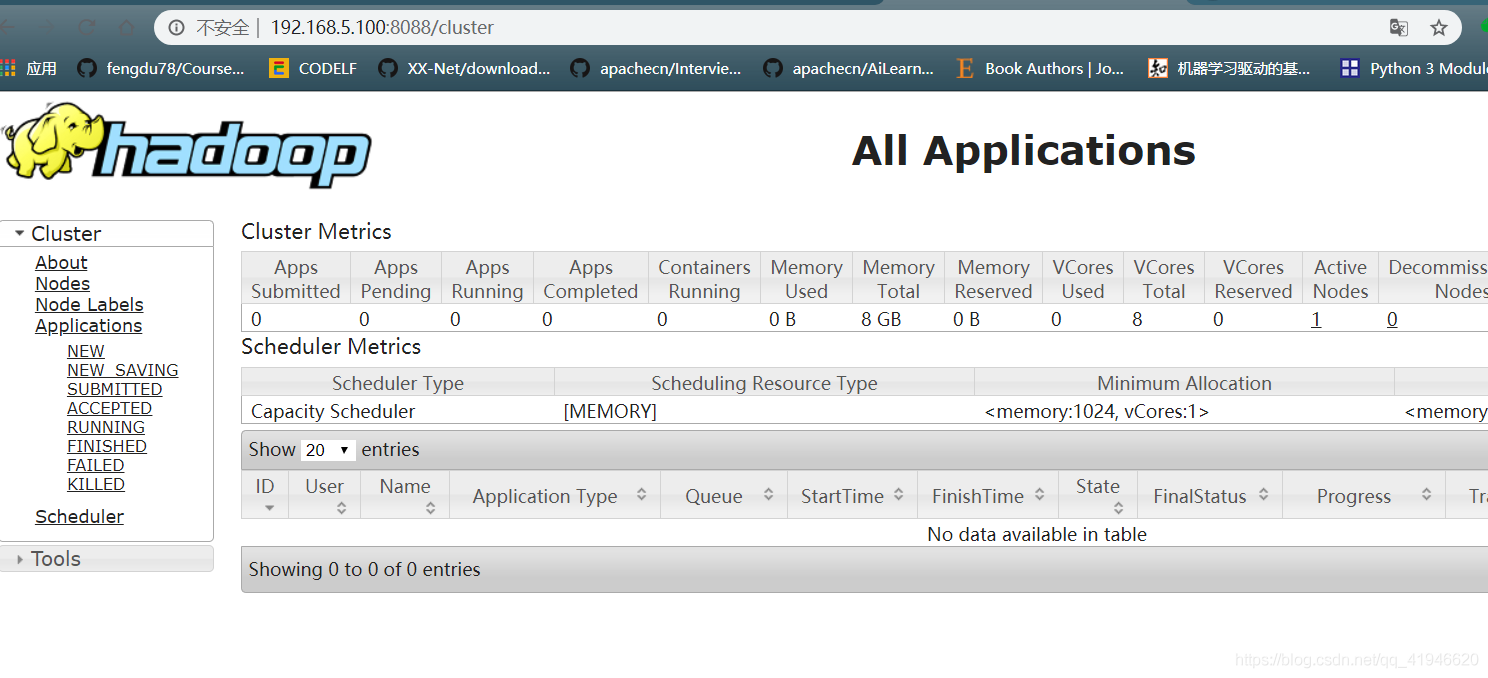
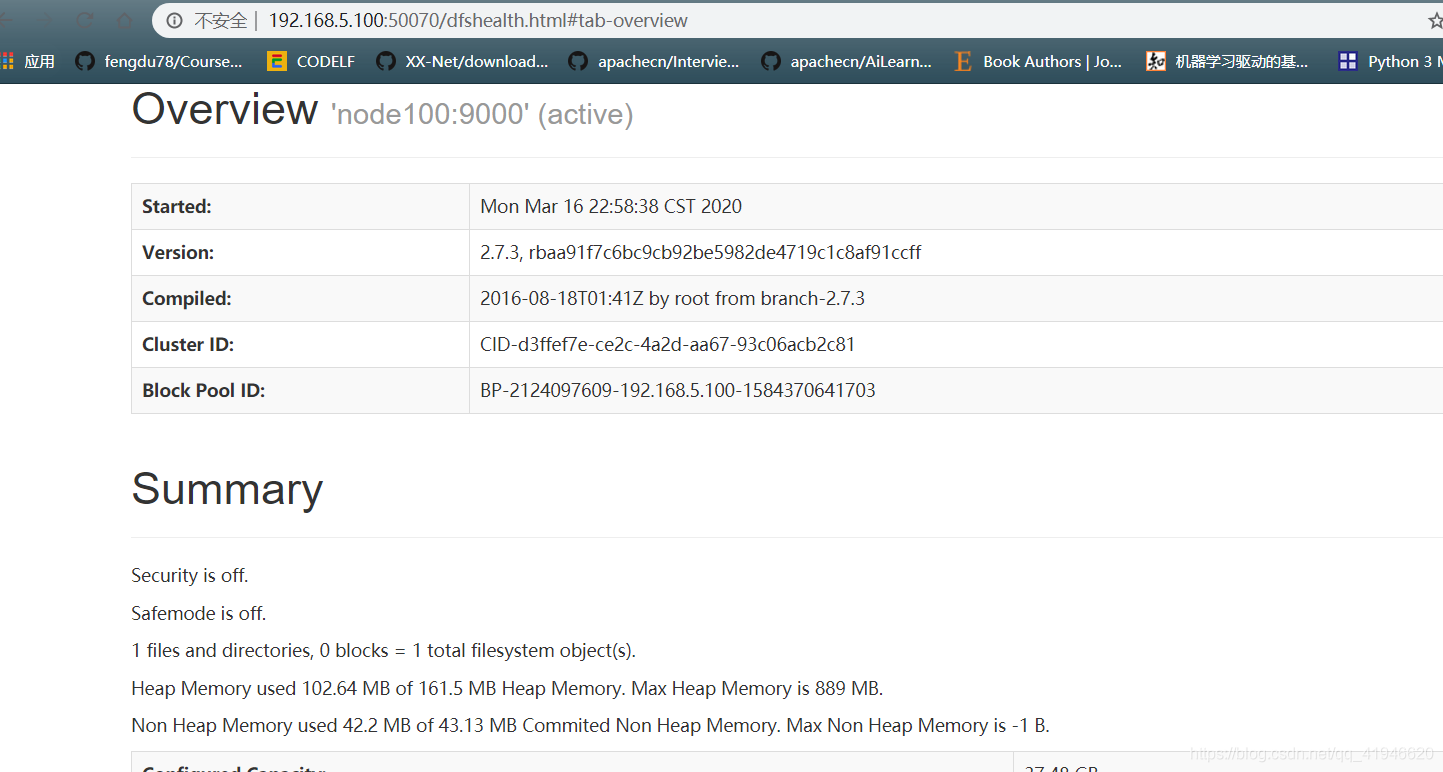
ページが表示されない場合は、ファイアウォールをオフにされていない可能性があります:
ファイアウォールをオフターン:rootユーザーに切り替え、
systemctl STOP firewalld.service
systemctl無効firewalld.service
十二、Hadoopのの語数の
タスクバーについての実行、Hadoopののホームディレクトリにファイルを作成
1.vim word.txt
書き込み:
こんにちは、Pythonの
ハローのJava
こんにちはScalaの
ハロー世界が
北京に購入可能です
:WQ保存
2.wordcountテストは、
クラスタ上のフォルダを作成:
HadoopのFS -mkdir /テストを
ファイルシステムにアクセスするためのファイルシステムブラウズで
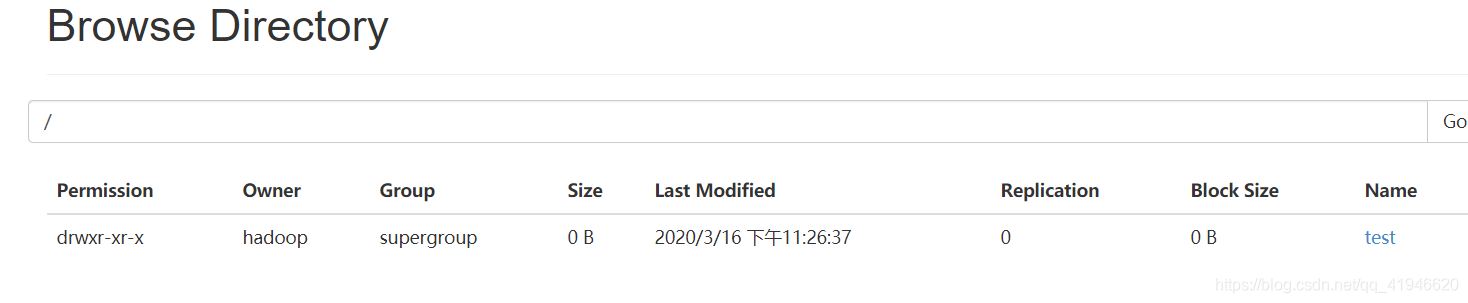
以前に作成した世界を、TXTは、(ホームディレクトリの実行)でのテストにコピー
HadoopのFS -put ./word。 TXT /テスト


の実行(各単語は、ファイル統計に表示された回数):
のHadoop JAR /opt/module/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar WORDCOUNT /テスト/ word.txt /出力
検証(結果現れる):
HadoopのFS -cat /出力/ 00000-R&LT Part-
サーティーン、ハイブのインストール
ハイブ--version
インストールを開始:
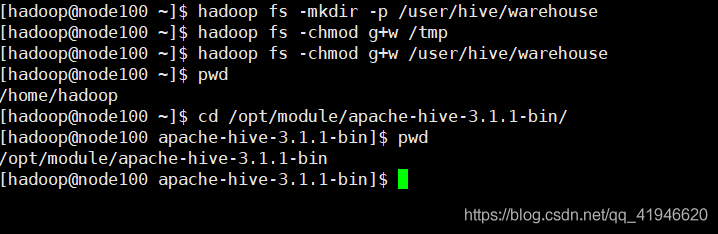
HDFS上のハイブのデータ格納ディレクトリを作成します。
ただ、タスクを実行するための時間にすでに見ていた、HadoopのFS -mkdirを/ tmp#tmpのディレクトリがすでに存在していている
HadoopのFS -mkdir - P /ユーザー/ハイブ/倉庫
#の所与の許可
HadoopのFSはG + W / tmpの-chmod
HadoopのFSはG + W /ユーザー/ハイブ/倉庫を-chmod
ハイブソフトウェアのディレクトリに初期化コマンドを実行
ハイブディレクトリにします。cd /opt/module/apache-hive-3.1.1-bin/
ビン/ SchemaTool -dbTypeダービー-initSchema
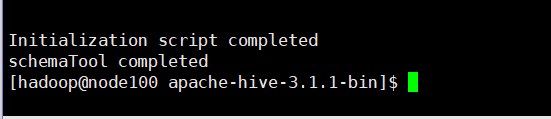
初期化の成功は、ハイブのインストールディレクトリにダービーを生成します後.logのログファイルとデータベースのメタデータはmetastore_db
ハイブ開始:apachディレクトリで入力しますbin/hive(このカタログで起動する必要があります)
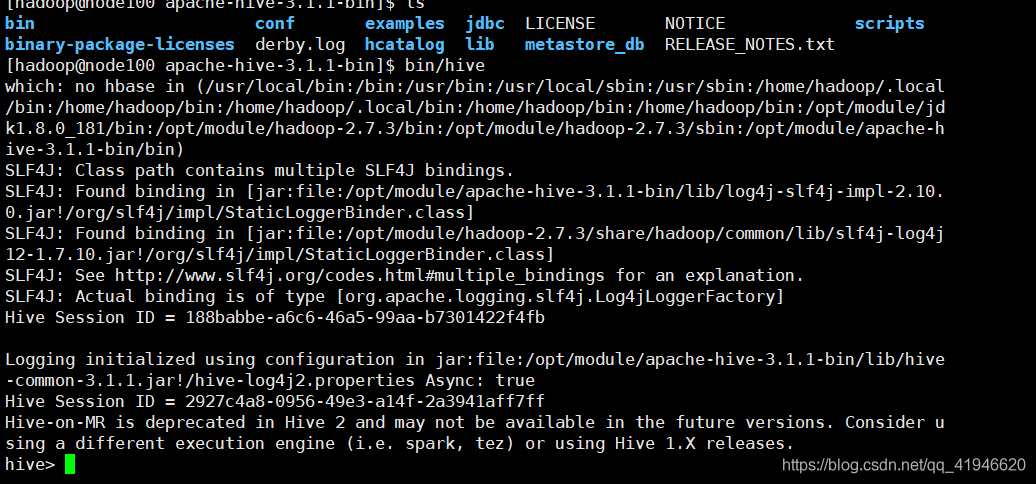
データベースを表示します。showデータベースを、
検証が成功し、他のコマンドを実行していない:出口は終了します。
注:(時々、あなたのクラスタに促すメッセージが表示されますセーフモードであるので、あなたがセーフモードでこの文を実行する場合は、)のままのHadoop Hadoopのdfsadmin -safemodeセーフモードを残します
MapReduceは、従来のバッチ指向タスク処理フレームです。新しい処理エンジンなどのTEZは、よりほぼリアルタイムの照会アクセスに傾きました。糸の出現により、HDFSはますます、このようなバルクアクセス、アクセス、およびリアルタイムのインタラクティブなアクセスなどのデータ・アクセス・パターンの多くを可能にするマルチテナント環境になってきています。
