勾配降下(勾配降下GD)は、単に一つの標的関数が連続反復調整パラメータを介して適切な標的を見つけるために、勾配情報を使用する方法を見つけるために最小化されます。この記事では、その原理と実装を紹介します。
勾配とは何ですか?
- 「部分的誘導体 - 」方向誘導体 - 「勾配誘導体:勾配の導入には、それは、4つの概念に分割することができます。
誘導体:関数は、時間領域で定義され、実数ドメインの値は、誘導体は正接関数曲線の傾きを表すことができます。
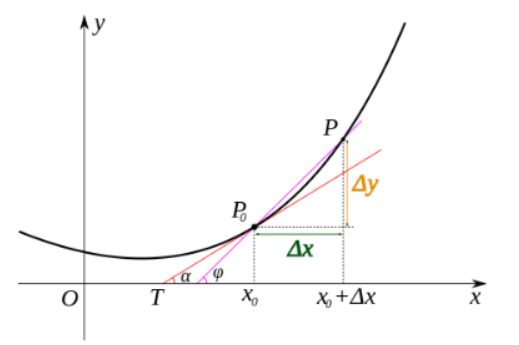
偏導関数:他の変数を一定に保ちながら偏導関数は、実際には、多変量多変量関数の関数の偏導関数は、一つの変数に関してその誘導体です。各点は、曲面上の接線の無数を持っているので、関数の導関数は非常に困難である述べます。偏導関数は、前記接線選択され、その傾きが決定されます。有意性は、幾何学的な点の接線傾き固定面です。
そのような固定されたバイナリ関数yとしての機能低下変動時間次元、のように単一のXが変化するので、研究へのxの関数として、1元に変化すること。
、x軸方向に沿って変化する関数値の速度定数であるY方向に関数を指し
x方向の関数を指すは、y軸方向に沿って機能変化率を変化させません

しかし、部分的な誘導体は、そう指向誘導体である、唯一のは、多価の機能の変化率軸方向の座標が、どの方向多変量関数の変化率を検討する多くの時間を表しているという欠点を有します。
指向誘導体:一定方向に誘導体、本質的にA点における接線の関数定義多数の傾きであり、それぞれが接線方向を示し、各方向はよくガイド番号です。
勾配:勾配は、ベクター、その最大、最速の変化の方向に指向性誘導体であり、この点での勾配の方向の関数、変化の最大レートです。
、最適化の反復を解決する機械学習における段階的なアプローチは、それほど頻繁に勾配ベクトルの方向に沿って勾配を使用して、勾配ベクトルは逆に沿って、今度は、関数function増加の最大値を見つけることが簡単に最速です場所、最速の勾配を減らす、簡単に最小を検索することができます。
勾配降下とは何ですか
一般的な例:各ポジションに行ったとき、あなたが山のどこかに立って、あなたがすぐにできるだけ山ダウンにしたいので、物事を一歩を踏み出すことにしました、あること、現在ある、勾配の負の方向に勾配の現在位置を解きます最も急峻行くダウンし、すべての道を行く、足はおそらく段階に来ているが、最低の地元の山。下図のように:

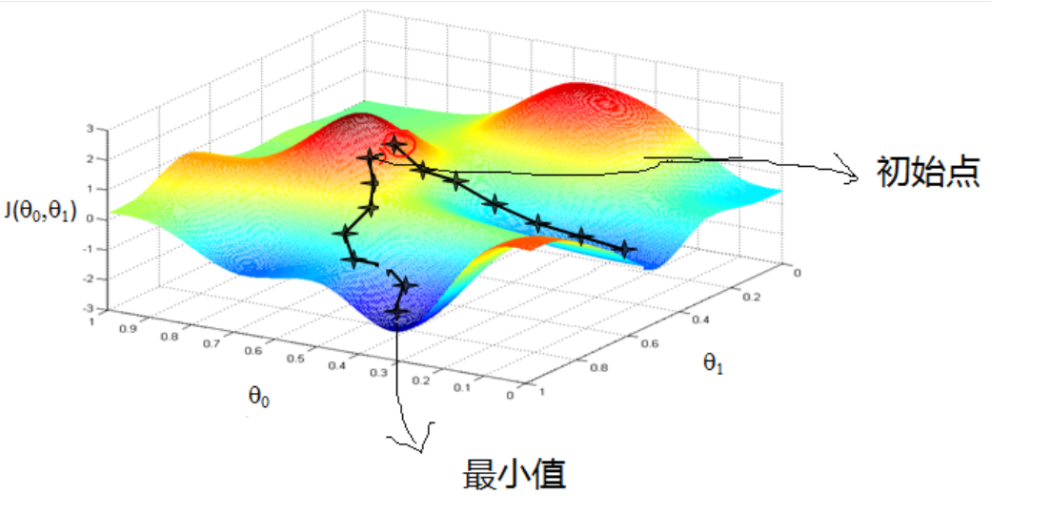
上記は、我々は、要約することができる:勾配降下法を得ることができる最大勾配上昇の方向に沿った勾配降下の方向における最小値を解決することであり、この方法は、傾斜上昇と呼ばれます。
あなたが見ることができるマップから:ターゲットの開始点が影響を受けると機能特性、勾配降下は、グローバル最適なソリューションは、それは部分的にしか最適なソリューションであってもよいですし、私は必ずしも見つからないグローバル最適なソリューションを得ることができたときに?この機能は、損失関数が凸関数であるとき、あなたはグローバルな最適解を見つけることができます損失に関連しています。
いくつかの重要な概念
上記勾配降下を解決するための原則によると、我々はに関連した勾配降下などいくつかの重要な概念を理解する必要があります。
ステップ(学習率):各ステップ勾配降下の前に目標ラインの長さ方向に、上記実施例と山ダウンは、ステップサイズは、現在の位置で下り坂最も脆弱な位置の最も急勾配に沿って歩いて、このステップバイステップの長さ。
関数仮定(機能仮説):で入力サンプルを適合させるために、教師あり学習、及び機能を想定すると、一般的にH(使用)関数が関数であると仮定し、線形回帰モデルのために、表す
\ [Y = W_0 + W_1X1 + W_2X2 +。 。.. + W_nX_n \]
損失関数(損失関数):共通J()モデルの品質を評価するために、通常、損失関数は、フィット感の程度を測定すること。対応するモデルパラメータが最適なパラメータである、最高のフィット感を意味損失関数を最小化。学習モデルは、機能の損失を持っている各マシンの目的は、学習が損失関数を最小化することで、
詳細なアルゴリズム
勾配降下アルゴリズムの具体的な実装は次のとおりです。
- そして、モデルの仮定損失関数の機能を決定します
- 関連備えた初期化パラメータ:パラメータを、そしてステップからアルゴリズムを終了します
- 損失関数の勾配の現在位置を決定します
- 現在の下降位置に起因する、段階勾配を乗算
- 以下のアルゴリズムが終了するよりも場合は、勾配降下アルゴリズムは終了距離以下の距離よりも全てのパラメータかどうかを決定し、そうでなければ次のステップ
- すべてのパラメータを更新し、更新ステップ1に進みます
問題
極小値とサドルポイント:すべての勾配降下最適化問題の一般的な二つの問題を体験してください。
ローカル最小
これは、最も一般的に多くの極小値の機能がある場合、勾配降下法に遭遇した問題であり、勾配降下法は、単に停止するそれらの局所的な最小値を見つけるには可能性があります。
それを避けるためにどのように?
極小値回避アルゴリズムの最初の実行、選択された最小の損失関数の初期値の異なる値で数回最も簡単な方法とすることができるように、実施例ダウン、我々は異なる初期値を参照し、最小値が得られるが、変化してもよいです。
鞍点
一方向のが、出発点からの最大のポイントの機能があり、目的関数の勾配は、この時点ではゼロであり、他の方向はの関数である:ハメ点がしばしば遭遇した数学的な意味サドルポイントがある現象の最適化問題です最小点。典型的な鞍点サドルポイント機能は、典型的には、関数f(x)= X ^ 3(0,0)、関数z = X ^ 2-y ^鞍点複数の(0,0,0)2(1 、1,0)、(2,2,0))。
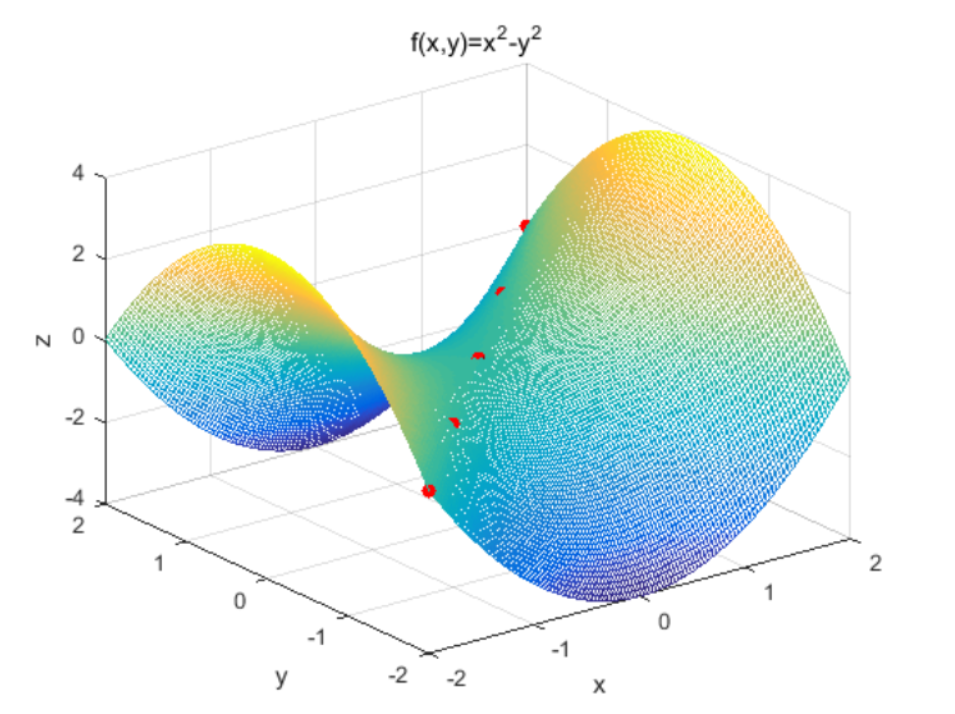
高度に非凸スペースで、時々最小値、失敗ではないが、勾配降下を作る鞍点の多数が、確かに収束するようです。
チューニング
必要に応じてチューニング含むアルゴリズムの実行ステップの観点から:
- ステップ:希望のステップサイズを選択して、実験を量るために、さまざまなシナリオ、長いステップは、より高速の繰り返し、最適なソリューションを欠場する可能性があり、ステップサイズは、アルゴリズムは非常に長い時間の終わりにはできません、小さすぎる、遅すぎるの繰り返しです。より最適な値を得るために数回実行する必要のステップのアルゴリズムはそう。
- 初期値:;損失関数が凸必ずしも最適解であれば、もちろん異なる初期値、最終的に得られる最小値が異なっていてもよいが、極小値を得ることができます。異なる初期値で数回は、選択した損失関数の初期値が最小化され、アルゴリズムを実行する必要があります。
一般的な勾配降下
バッチ勾配降下(バッチグラデーション降下BGD)
アルゴリズムは、上述した実際のバッチ勾配降下です。1つの損失関数としての全データセット数を横断し、各パラメータについて計算した勾配関数は、勾配を更新する:最初にすべてのデータ値の損失を計算し、次いで、勾配降下を行い、特定のステップです。この方法は遅く、オンライン学習をサポートしていないされて速度を計算し、すべてのパラメータと、全サンプルのデータセットは、容量を計算し、再計算されるべきで更新されます。
確率的勾配降下法(確率的勾配降下SGD)
単一の勾配を用いて近似されるようなサンプルの総量は、勾配を計算するために使用されていない、大幅に計算量、計算効率を減少させることができます。具体的な手順は次のとおりトレーニングセットのランダムサンプルからの各選択は、対応する損失が計算され、勾配、パラメータ更新反復。
このように、比較的大きいデータ・サイズが計算の複雑さを減らすことができ、確率センスの勾配から単一試料が全データセットの勾配の不偏推定値であるが、いくつかの不確実性があり、したがって、収束速度比低速のバッチ勾配降下。
小バッチ勾配降下(ミニバッチグラデーション降下)
妥協することにより、2つの方法、手段、上記の欠点を克服するために:バッチ、バッチ更新複数のパラメータにデータを一括してデータの各セットは、一緒になって、この勾配の方向が減少決定しますロットのバッチにおけるサンプル数が少ないデータセット全体よりも、量を計算することは大きくないので、それは、一方で、ランダム性を減少させる、簡単な偏差ではありません。
各利用複数のサンプルの勾配を推定する、従って不確実性を低減することは、収束速度、各反復は、バッチサイズ選択(バッチサイズ)と呼ばれている、請求サンプルの数を向上させます。
参考: