1.データ処理
1.まず、負荷データは、データの詳細を見る
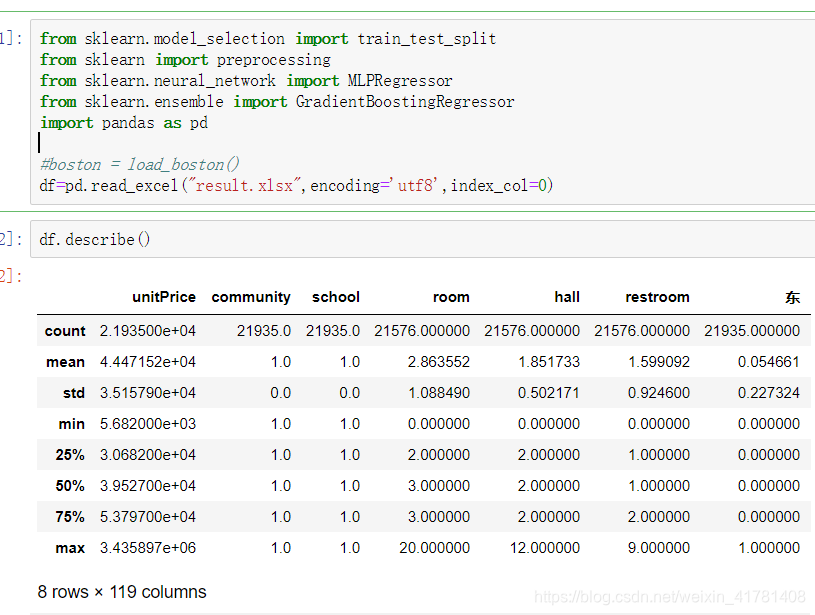
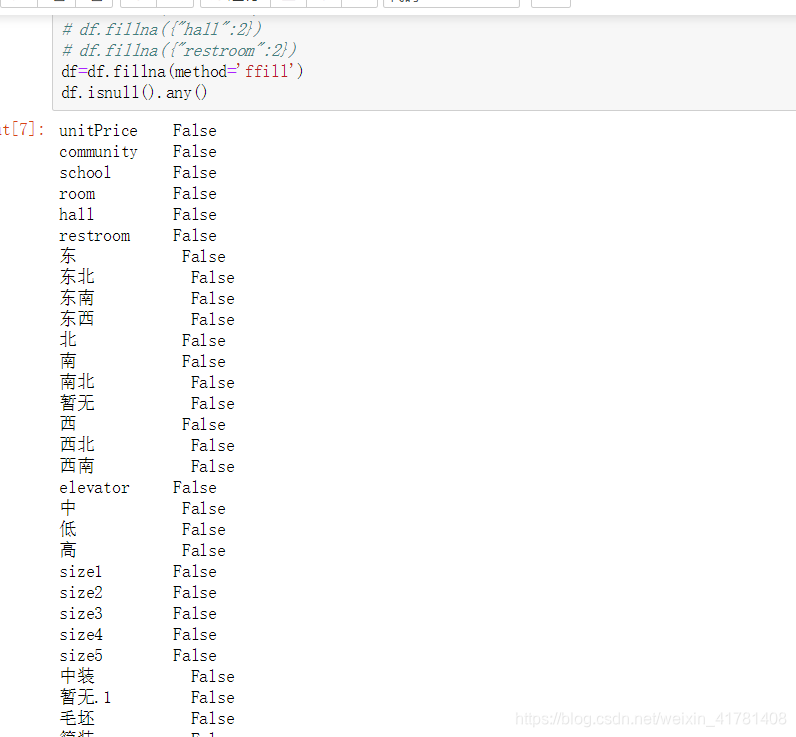
2.チェックデータ項目かどうか、およびNANを。

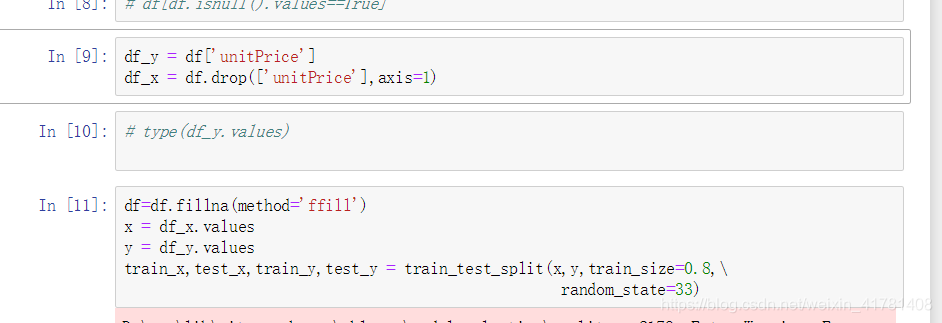
アイテムの三組は空埋めるために
トレーニングとテストデータに4つのデータ
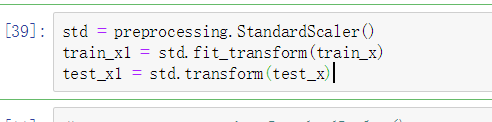
5.データの正規化
2.モデルが予測
MLP -回帰モデル

統合リターン
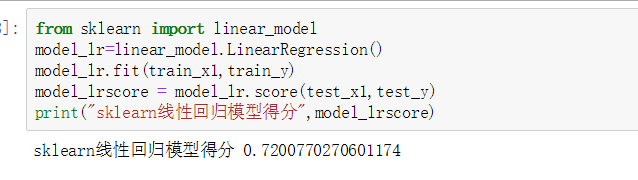
線形回帰
SVM回帰

KNN回帰

ツリー回帰

ツリー回帰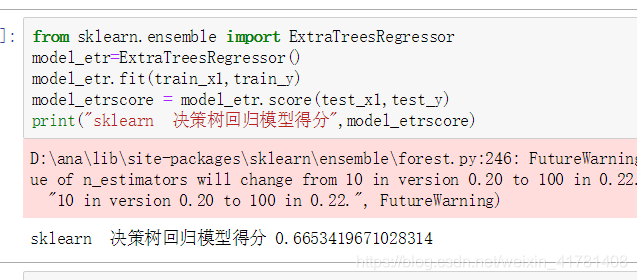
ランダムフォレスト回帰

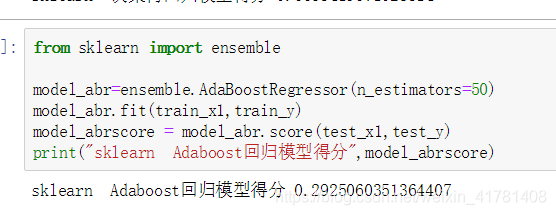
アダブーストリターン
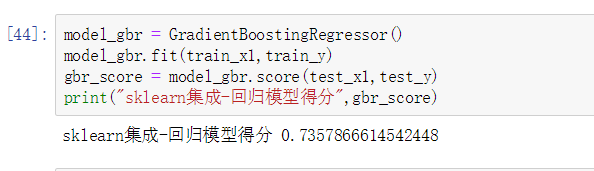
gbrtリターン
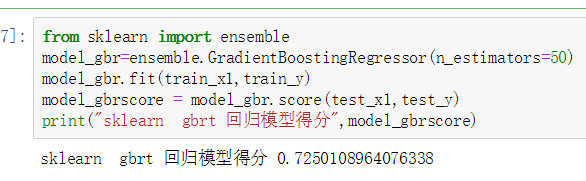
袋詰め復帰

3.モデル統合
K倍クロスバリデーションを使用すると、
いくつかの好適なプロセスモデルを使用し
データ結果の結果を使用します
import warnings
warnings.filterwarnings("ignore")
from sklearn import preprocessing
from sklearn.neural_network import MLPRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn import ensemble
import pandas as pd
import math
from sklearn.model_selection import KFold
df = pd.read_excel("xxx.xlsx",encoding='utf8',index_col=0)
df=df.fillna(method='ffill')
data = df.values.astype('float')
x = data[:,1:]
y = data[:,0]
for i in range(len(y)):
y[i] = math.log(y[i])
kf = KFold(n_splits=5,shuffle=True)
for train_index,test_index in kf.split(x):
train_x = x[train_index]
test_x = x[test_index]
train_y = y[train_index]
test_y = y[test_index]
ss_x = preprocessing.StandardScaler()
train_x = ss_x.fit_transform(train_x)
test_x = ss_x.transform(test_x)
ss_y = preprocessing.StandardScaler()
train_y = ss_y.fit_transform(train_y.reshape(-1,1))
test_y = ss_y.transform(test_y.reshape(-1,1))
model_mlp = MLPRegressor(solver='lbfgs',hidden_layer_sizes=(20,20,20),random_state=1)
model_mlp.fit(train_x,train_y.ravel())
mlp_score = model_mlp.score(test_x,test_y.ravel())
print("sklearn多层感知器-回归模型得分",mlp_score)
model_gbr = GradientBoostingRegressor(learning_rate=0.1)
model_gbr.fit(train_x,train_y.ravel())
gbr_score = model_gbr.score(test_x,test_y.ravel())
print("sklearn集成-回归模型得分",gbr_score)
model_br=ensemble.BaggingRegressor()
model_br.fit(train_x,train_y)
model_brscore = model_br.score(test_x,test_y)
print("sklearn bagging 回归模型得分",model_brscore)
model_rfr=ensemble.RandomForestRegressor(n_estimators=20)
model_rfr.fit(train_x,train_y)
model_rfrscore = model_rfr.score(test_x,test_y)
print("sklearn 随机森林回归模型得分",model_rfrscore)
model_br=ensemble.BaggingRegressor()
model_br.fit(train_x,train_y)
model_brscore = model_br.score(test_x,test_y)
print("sklearn bagging 回归模型得分",model_brscore)
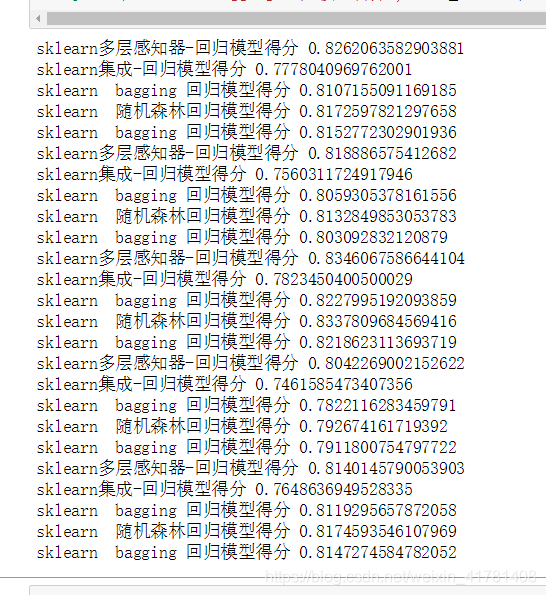
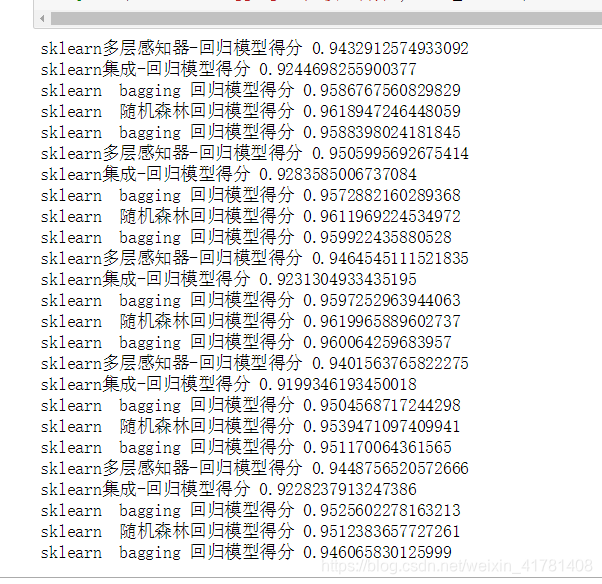
処理されたデータ耐用年数のスコアを使用して
参考ます。https://www.jianshu.com/p/f92d9ac14692
