Pythonプログラミングjupyterノートブックに基づい-----使用sklearnライブラリ、インポートデータファイルのアナログ線形回帰分析
- まず、実行jupyterノートブック、構築された環境のpython
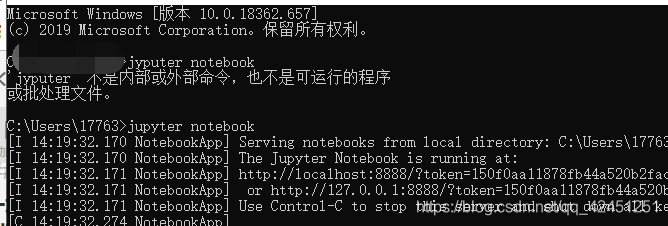
- 1. Windowsのターミナルコマンドライン、タイプ== jupyterノート==、次のように私たちのjupyterツールを開きます。
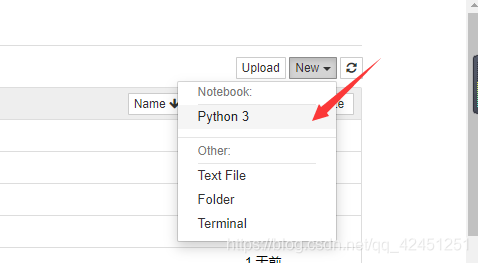
- 次のように、WebページのPythonのファイルjupyterを作成します。2.:
- 3、あなたは今、それ内のコードのjupyter行で我々のコードを入力することができます!
- 第二に、csvファイル以下、例えば、書き込みPythonコードへの私たちの最小二乗法の段階ブレークダウン
- 1は、私たちは基本的なライブラリをインポートする必要があります
- 2は、我々は== mytest.csvデータファイルをインポートする==
- 私たちのx、yの代入サンプリングのための3、
- 図4に示すように、以下では、YはAX + Bと== == == Bは=見つけ、sklearnライブラリを処理するデータを使用することである==
- 5、当社のプリント線形回帰式の出力が得られ
- 6、図に示す曲線をフィッティング==散乱==による。
- 三、Pythonライブラリを使用sklearnすべてのソースの分析回帰式
- 四、==シフト+私たちのコードを実行します==入力します
最後のブログは、我々は最小二乗法の線形回帰分析を使用し、この方法は、我々が調査し、高校の線形回帰の我々の理解の基礎であり、この方法によれば、回帰係数と切片を解決することは可能ですが、大学生など私たちのために、より簡単な方法が明確にあり、コード自分自身を記述することなく、それはサードパーティのライブラリをインポートするだけで必要okです、このブログ、林6月の高齢者がどのように使用することに、知っている私たちがかかりますsklearnライブラリの線形回帰を分析するために、
まず、実行jupyterノートブック、構築された環境のpython
1. Windowsターミナルコマンドライン、入力します。jupyterノート以下のように、私たちのjupyterツールを開きます。
次のように、WebページのPythonのファイルjupyterを作成します。2.:
3、あなたは今、それ内のコードのjupyter行で我々のコードを入力することができます!
第二に、csvファイル以下、例えば、書き込みPythonコードへの私たちの最小二乗法の段階ブレークダウン

次のようにドキュメントを読み取ります。
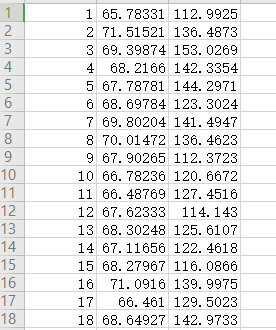
高さの回帰直線的重量X、Y用のファイルを
1は、私たちは基本的なライブラリをインポートする必要があります
from sklearn import linear_model #表示,可以调用sklearn中的linear_model模块进行线性回归。
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
2、我々はデータファイルをインポートしますmytest.csv
data = np.loadtxt(open("D:mytest.csv","rb"),delimiter=",",skiprows=0)
data1=data[0:20]
DATA1 ==上方=データは[午後12時20分] ==我々は、行20の前にファイルのデータをインポートすることを意味するが、類推によって、ここ200,2000ラインデータを導入し、以下のように変更することができる
)1、データライン200に導入
data1=data[0:200]
2)行2000を導入
data1=data[0:2000]
私たちのx、yの代入サンプリングのための3、
x=[example[1] for example in data1]
y=[example[2] for example in data1]
X = np.asarray(x).reshape(-1, 1)
Y = np.asarray(y).reshape(-1, 1)
:1)、上記、X、Y 1は、下記に示すように、第2行は、X、Yに割り当てられている、インポートされたデータの最初の列を表し
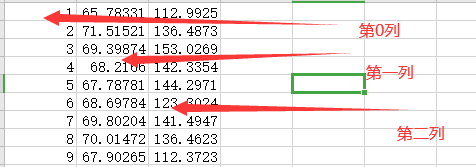
2上)X、Yこれは、データリスト用にインストールされています配列array便利なsklearnライブラリーデータ分析
4、次はでY = AX + Bを見つけ、sklearnライブラリデータ処理の使用でありますAとB
model = linear_model.LinearRegression()
model.fit(X,Y)
b=model.intercept_[0] #截距
a=model.coef_[0]#线性模型的系数
a1=a[0]
上記のデータ処理がsklearnが書き込まれ、管理するために、サードパーティのライブラリを、私たちを必要としない、我々は直接OKで使用されています
5、当社のプリント線形回帰式の出力が得られ
print("y=",a1,"x+",b)
6、によって散布図に示す曲線を当てはめます。
y1 = a1*X + b
plt.scatter(X,Y)
plt.plot(x,y1,c='r')
これらは、単純な線形回帰式の利用sklearnライブラリです、このプロセスは比較的単純で、基本的なサードパーティのライブラリを使用することは極めて困難で、インポートするファイルを解決して、割り当てることで、あります!
三、Pythonライブラリを使用sklearnすべてのソースの分析回帰式
from sklearn import linear_model #表示,可以调用sklearn中的linear_model模块进行线性回归。
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
data = np.loadtxt(open("D:mytest.csv","rb"),delimiter=",",skiprows=0)
data1=data[0:20]
x=[example[1] for example in data1]
y=[example[2] for example in data1]
X = np.asarray(x).reshape(-1, 1)
Y = np.asarray(y).reshape(-1, 1)
model = linear_model.LinearRegression()
model.fit(X,Y)
b=model.intercept_[0] #截距
a=model.coef_[0]#线性模型的系数
a1=a[0]
print("y=",a1,"x+",b)
y1 = a1*X + b
plt.scatter(X,Y)
plt.plot(x,y1,c='r')
IV。Shift + Enter私たちのコードを実行します。
図1に示すように、結果を以下に示します:
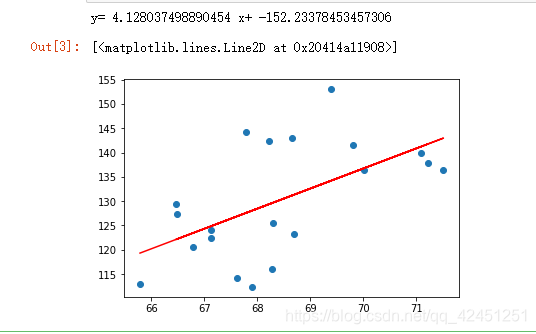
図2は、それを見ることができ、上部線形回帰式20のX(重量)値によってPythonコードをフィッティング我々の議論は、我々は、同じデータ、20の同じ値によってWPSをExcel、および下に示したように、我々は、データベースの比較結果をsklearn:
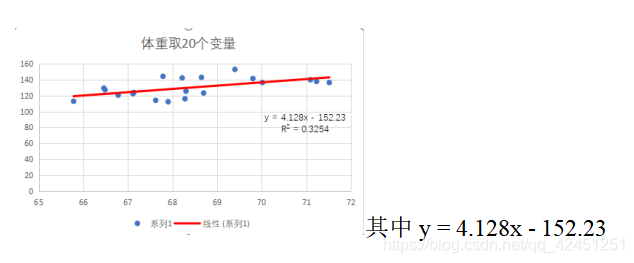
図から分かるように、線形回帰フィットのうちのpython、我々はほぼ同じ、フィット線形回帰式をエクセル、問題は、我々のコードは非常に完璧で、あなたが見ることができる、重要な数字です!
3、変数X 200および線形回帰式の2000年からの値に、私たちは何をする割り当てられたyのxに変更を加えることができます!
1)×200値
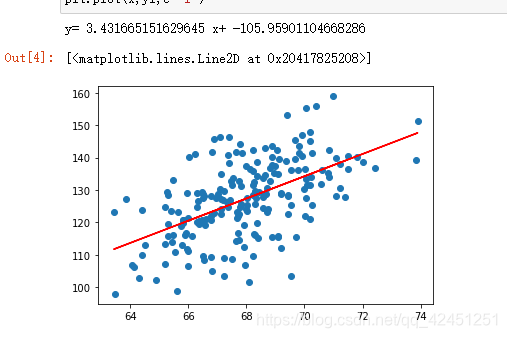
コントラストエクセル:
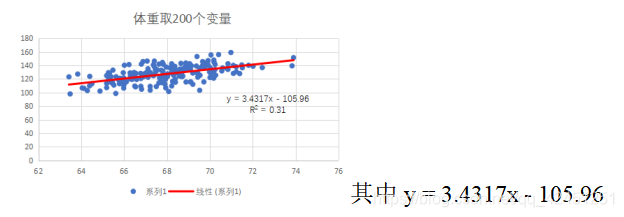
2)、2000年のxの値
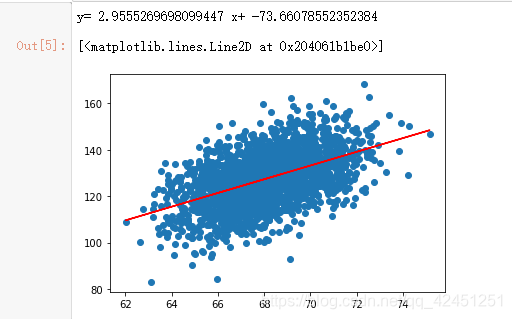
コントラストエクセル:

私たちはこのブログで持っているすべてです、私はこのブログを通じて、私たちはより良いサードパーティのライブラリを使用する方法を理解することができますことを願っていますsklearn線形回帰式を求めてああ!
問題は、ほとんどの友人に遭遇したゲストブックああコメント、先輩はあなたに答えるために忍耐を与えます!
陳月に年と1日をプログラミング^ _ ^
