例1.1の一般的な方法を探します
参考ブログ: https://www.cnblogs.com/wuchanming/p/6886020.html
1、シーケンシャルサーチ(線形検索)
1.最も基本的なクエリアルゴリズムは、確かに、比較法の各要素であるシーケンシャルサーチ(線形検索)であるが、この方法は、データ効率の大きな量が非常に低いです。
2. データ構造:注文または順不同キュー
3. 複雑: O(N)
2、バイナリ検索
、配列の中央要素1.、中間要素は、要素は単に、検索処理を終了する素数を見つけることである場合に
特定の要素は、アレイ内の中間要素は、中間要素のそれよりも大きいか小さいより大きいまたは小さい場合2の半分を[検索と比較根は同じ要素の途中から開始し始めます。
前記アレイは、いくつかの段階では空である場合、それが見つかりません表します。
4. データ構造:規則的な配列
5. 複雑: O(logN個)
3、バイナリ・ソートツリーが見つけるために
1)バイナリソートツリーがある特徴:
1.その左部分木が空でない場合、すべての値が木の左の子ノードがルートの値よりも小さいです。
2.空の右の部分木、根の値より全て大きいノードの右の部分木ではない場合。
3.その左と右のサブツリーもバイナリ・ソートツリーです。
2)どのように検索:
Bが空の木である場合、検索は失敗し、または:
xはデータのルートドメインのBの値に等しい場合、検索は成功し、そうでない場合:
値は、以下のルートノードxのBデータフィールドよりもあれば、次に左の部分木を検索します。そうでない場合:
右のサブツリーを検索します。
データ構造:バイナリ・ソートツリー
時間の複雑さ: O(log2Nの)
4、ハッシュハッシュ(ハッシュ・テーブル)
1.第一原理は、キー値、ハッシュ関数によってキーに基づいて、燃料経済性、測位データ要素位置に応じてハッシュテーブル(ハッシュ・テーブル)を作成することであり、ハッシュ関数。
2.データ構造:ハッシュテーブル
3.時間計算:ほとんどO(1)、どのくらいの競合に依存。
コンピュータのインデックスデータ構造の1.2原則は、関連が設けられています。
1、コンピュータのメインメモリと外部メモリの紹介
1. コンピュータシステムにおいては、典型的には、メモリの2つの種類、コンピュータのメインメモリ(RAM)及び外部メモリを含む(例えば、ハードディスク、CD、SSDなど)。
インデックスアルゴリズムとストレージ構造の設計2.、我々は考慮にストレージ機能の両方のタイプを取る必要があります。
前記メインメモリは、速度がデータに対して、高速で読み取るは、特に、それらの間の違いは後に詳述するメインメモリの速度、遅い数桁からよりメイン外部ディスクを読み取ります。
コンピュータのメインメモリに記憶されている4.すべて上記クエリアルゴリズムが想定話しているデータは、コンピュータのメインメモリは、データベース内の実際のデータは、外部メモリに格納され、一般的に小さいです。
2、どのようにインデックスのパフォーマンスを評価します
一般に1.、インデックス自体も大きい、それはすべてのメモリに格納することができないので、インデックスはしばしばディスクのインデックスファイルの形式で格納されます。
この場合には、プロセスは、数桁の消費へのメモリアクセス、I / Oアクセスに対して、指数ルックアップディスクI / Oの消費量を生成します。
3.したがって、最も重要な指標の指標としてのデータ構造のメリットの評価は、ディスクI / O操作の数のプロセスの複雑さで進行性の外観です。
4.言い換えれば、インデックスの構造組織は、アクセスのルックアッププロセスのディスクI / Oの数を最小限に抑えます。
3、原則として、メイン・メモリ・アクセス
注:この記事は、RAMの動作原理を説明するための非常にシンプルなアクセスモデルを抽象化、特定の違いを放棄します
ビューの抽象的な点1.、メインメモリは、記憶ユニット、各固定サイズのデータの記憶部は一連の構成行列です。
2.各メモリセルは、固有のアドレスを持ち、現代の複雑なルールのアドレッシングメインメモリは、1つの2次元のアドレスにそこに簡略化します。
3.一意に行アドレスおよび列アドレスを介して、記憶部に配置されます。
図モデルを示して4×4のメインメモリ:
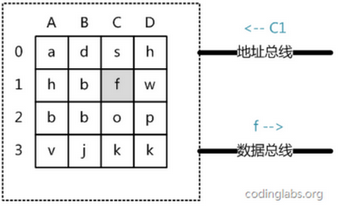
次のようにメインメモリアクセスプロセスである:
1)システムは、メイン・メモリ・アドレス信号を読み出した後、メインメモリアップロードするアドレスバス上に、メインメモリの読み出しアドレス信号が必要である場合
、次に、分析信号を、特定のメモリセルに位置しますこのストレージユニットの他の部分を読み取るためのデータバス上のデータ、。
2)同様のプロセスは、メインメモリを書き込むために、システムユニットは、アドレスに書き込まれるデータは、アドレスバスとデータバス上に配置され、メインメモリは、それに応じて、書き込み動作を2つのバスの内容を読み取ります。
3)ここで見ることができ、メインメモリアクセス時間は、機械的な動作が存在しないので、任意の効果「距離」時間に対する2つのアクセスデータを持たない、アクセス数のみ直線的です
例えば、最初のテイクA0 A0 A1を取り、その後、プリエンプティブD3消費を取る時間4)が同じです。
4、ディスクアクセスの原則
1.インデックスは、一般的にディスク上のファイルとして格納され、インデックス検索は、ディスクI / O操作が必要です。
ディスクI / O時間の消費量が巨大であるように、異なるメインメモリと2は、ディスクI / Oは、機械的な動きをとります。
ディスク上の前記読み出されたデータは、それがディスクからデータを読み出すことが望まれる場合、システムは、データディスクの論理アドレスとなり、機械的な動きです。
即ち、トラック、セクタに読み込ますべきデータを決定する、論理アドレスを物理アドレスに変換するために論理アドレス指定に応じて前記磁気ディスク制御回路。
5.セクタのデータを読むためには、磁気ヘッドがこのセクターの上に置くことが必要であり、これを達成するためには、磁気ヘッドは、プロセスが求め呼ばれ、対応するトラックに移動する必要があります。
前記シーク時間は、時間がかかると呼ばれ、ターゲットセクタヘッドに回転ディスクの回転は、時間のかかるプロセスは、回転時間と呼ばれ、最終的にデータを読み取るために送信されます。
7.このため、データを毎回読み出すために要する時間を分けることができる 時間を求め、回転待ち時間、送信時間 3つの部分。
1)一般主流ディスク5ミリ秒以下で、必要とされる時間を追跡指定求める磁気アームです。
2)私たちはしばしば、回転遅延を聞くようなディスク7200、ディスクの回転速度で、回転待ち時間は1/120/2 = 4.17msであり、120回秒を回すことができることを、毎分7200の回転で表すことができます。
3)通常ミリ秒の数十分の一に、最初の二つに対して時間は無視することができ、ディスクにディスクからデータを読み書きするための送信時間を指します。
8. I / O操作の巨大な問題
1)ディスク・アクセス時間、すなわち、ディスクIO時間は、約5、約+ 4.17 =て9msに等しい
)2かなり良いに聞こえるが、あなたは500 -MIPSマシンが毎秒5億の指示を行うことができます知っています
3)命令は、つまりIOで、電源の性質に依存しているので、時間を実行40万命令を実行することができます
4)データベースは明らかに頻繁に10万何百千万のデータは、それぞれ9ミリ、災害を。
5、ディスク先読み
そのため、効率を改善するために、ディスクI / Oを最小限に抑えるためには、この目的を達成するために、ディスクは、厳密たびにオンデマンドで読みますが、事前に読み込みますしばしばではありません。
でも、1バイトしかならば、ディスクは、データの長さは順次メモリに読み戻す、この位置から開始されます。
データを使用する場合、その付近のデータも、多くの場合、すぐに使用すること。そのためには有名な産地原則のコンピュータ科学の理論に基づいています。
長さは、一般に、ページ(ページ)が整数倍である先読みされています。
論理ページ・コンピュータ・メモリ管理のブロック、ハードウェアおよびオペレーティングシステムは、メインメモリに傾向があり、ディスクの記憶領域が同じサイズの連続したブロックに分割され
各メモリブロックは、(多くのオペレーティングシステムでは、ページ・サイズは、典型的には、4K得られる)、メインメモリと、ページ単位でディスク交換データと呼ばれます。
プログラムデータが読み込まれるが、メインメモリにない場合は、ページフォルト例外がトリガされ、その後、システムは、ディスクを読み取るために、ディスクに信号を送ります
ディスクのデータが連続してページまたはメモリにロードされたページ、および異常なリターンを読むための開始位置を見つけるために、プログラムは実行を継続します。
5、Bツリー/ B +ツリー構造記憶
ここで1は最終的に分析する理由は、インデックスBを使用してデータベース - ストレージ構造の/ +ツリー。
2.上記のインデックスデータベースは、ディスクに格納され、我々は一般的インデックス構造のメリットを評価するために、ディスクI / O回数を使用しています。
3. Bツリー分析開始、Bツリー、最大明らかH-1を必要とアクセスノード(メモリ常駐ルート)を検索の定義に従います。
データベースシステムディスクの設計者の巧妙な使用は先読み原則4、ノードは、各ノードは一つだけI / Oを完全にロードすることができる必要がありそうという、ページのサイズに等しく設定されます。
この目的のために5、Bツリーは、次の方法を使用するにも実用的な実装です。
1)新しいノードに直接従って一つの物理ノード上で確実にページ・スペースを適用するたびにページに格納されて
割り当て、ページ整列されるコンピュータメモリに結合された2)、ノードは一度だけ実現されますI / O。
1.3のMyISAMインデックスは達成します
1、MyISAMテーブルインデックスは、導入を実現しました
1のMyISAMエンジンは、データフィールドに格納されたB +ツリーインデックス構造を使用して、リーフ・ノードは、データ・レコードのアドレスです。
2. MyISAMテーブルインデックスはB +ツリー検索インデックスに応じてアルゴリズム最初の検索アルゴリズムを検索します。
指定されたキーが存在する場合は3、そのデータフィールドの値が削除され、その後、アドレスデータフィールドの値は、対応するデータレコードを読み込みます。
4.のMyISAMインデックスモードもそうInnoDBがインデックスをクラスタ化区別するために呼ばれる理由は、「非クラスタ化」と呼ばれています。
2、MyISAMテーブルのインデックスの回路図
ここでは、表1に提供され、3の合計は、我々はのCol1主キーを想定し、主要指数は、模式的に図MyISAMテーブル(主キー)です。
2.これは、アドレスのみのデータレコードの保存のMyISAMインデックスファイルを見ることができます。

1.4 InnoDBのインデックスを達成
注:異なるMyISAMテーブルと、InnoDBはまた、B +ツリーインデックス構造として使用されるが、しかし、特定の実装方法。
1,1との間の差: InnoDBのデータファイル自体がインデックスファイルであります
上記知識、MyISAMのインデックスファイルとデータファイル1.は、データレコードに格納されたインデックスファイルのアドレスだけ分離されています。
2.ではInnoDBは、プレス・テーブル・データファイル自体はB + Treeインデックスに組織構造、ツリーのリーフノードデータフィールドは、完全なデータの記録を保持しています。
InnoDBのテーブルデータファイル自体が主インデックスであるように、3キーには、データテーブルの主キーインデックスです。
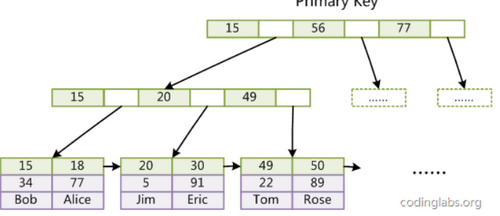
説明:
あなたは、リーフノードは、データの完全な記録、クラスタ化インデックスと呼ばれるこのインデックスが含まれて見ることができます。
データファイル自体Yaoan InnoDBの主キーの集約は、それが必要なのでInnoDBのテーブルは主キーを持たなければならない(できないMyISAMテーブル)
明示的に指定しない場合、システムが自動的に一意のデータレコードを識別することができ、主キーとしてMySQLの列を選択します
この列が存在しない場合、主キーとして隠されたフィールドを生成自動的にMySQLのInnoDBのテーブルは、フィールド長が6は長整数型をバイトです。
2,2の間の差: InnoDBの補助データフィールド格納主キーの記録アドレスに対応する代わりの指標値
1.言い換えれば、すべてのセカンダリインデックスのInnoDBは、プライマリキーのデータフィールドとして挙げられます。
比較基準としてASCII英文字でここ2。
3.この実装では、検索は非常に効率的であるクラスタ化インデックス、主キーを押しすることができますが、セカンダリインデックスの検索インデックスは二回取得する必要があります
まず、主キーのインデックスを取得して、取得したレコードを取得するために、主キーにプライマリ・インデックスを使用してサポート検索。
3、なぜ主キーとして長いフィールドの使用を推奨していません
1.既知の例では、インデックスはInnoDBの後に達成、あまりにも長い間、主キーフィールドとして推奨されない理由は簡単です
2.すべてのセカンダリインデックスはメインインデックスへの参照であるため、長いメインインデックスがセカンダリインデックスが大きくなりすぎるようになります。
別の例として3、InnoDB内の主キーなどの非単調なフィールドではない良いアイデアのInnoDBデータファイル自体はB +木であるので、
4.非単調な主キーは、B +ツリーの分割と頻繁に調整の性質を維持するために、非常に非効率的なデータファイルの新しいレコードの挿入の原因となりますし、主キーとして自己増力フィールドの使用は良い選択です。
1.5利用規定インデックス
図1に示すように、ジョイントインデックス(複合インデックス)
1.共同指数は、一般的な指標だけで一つのフィールドに比べて、実際には非常に簡単です、あなたは共同インデックスindexの複数のフィールドを作成することができます
2.それは、B、例えば、我々は(a、b、c)をフィールド上関節インデックスを作成、インデックスレコードは最初のフィールドAによってソートされ、また、非常に単純な原理であり、次いで、ソートフィールドは、次にCフィールドである従います
3.実際には、辞書の関節インデックスのわずかな外観は、最初のチェックの最初の文字に応じて、同じであり、第2の文字に応じてチェック
4.チェックするか、最初の文字のみが、2番目の調査から始まるアルファベットの最初の文字をスキップすることはできません。これは、最も左のプレフィックス原理として知られています。
関節指数をすることを特徴とします。
1)最初のフィールドは、順序付けされなければならない
フィールド値が第1の時間に等しいとき2のすべての値に対してA = Bを注文したとき、第2のフィールドは、次の表のように、順序付けされた)2 、というように、同じBの価値すべてのフィールドが構成Cを命じている場合



「」「最も左接頭原則」「」 #### 1、次のクエリは、インデックスを使用することができます '「」 = 1テーブルSELECT * FROM。 = 1表およびb = 2 SELECT * FROM。 = 1表及びB = 2、C = 3 SELECT * FROM。 ()、(a、b)は、(a、b、c)は、あなたが最も左接頭辞一致するインデックスの順序を利用することができますに応じて3件の問い合わせ上記の。 「」」 #### 2、クエリがある場合: '' " = 1およびc = 3テーブルSELECT * FROM;のみインデックスAを使用。 「」」 #### 3、ようにインデックスを使用しません 「」 ' 左端の接頭辞ので使用しない、インデックスにユーザクエリので、テーブルからここで、B = 2、C = 3 *選択。 「」」
2、プリフィックス索引
1.プリフィックス索引列全体が索引キー、現在のプレフィックス長として列の接頭辞に置き換えられ、あなたはとても完全な列インデックスのいずれかに選択的に接頭辞インデックス近くを行うことができます
インデックスキーがインデックスファイルを維持するのサイズとコストを削減するために短縮されているため、同時に2。
3.一般的には次のように接頭辞インデックスを使用することができます。
1)文字列(VARCHAR、文字、テキスト、等)、又はフルフロントマッチフィールドの一致のために必要。すなわち=「XXX」または「XXX%」等
2)は、文字列自体が比較的長く、そして最初の数文字が同じでない開始してもよいです。(例:受信者のアドレス、外国人の名前)
4. MySQLの接頭辞インデックスは効果的にインデックスファイルのサイズ、増加速度の指標を減らすことができます。
プリフィックス索引もその欠点があります:MySQLのプリフィックス索引は、ORDER BYまたはGROUP BYで使用することができない、また彼らがカバーするインデックス(カバリングインデックス)として使用することができます。
3、インデックスの最適化戦略
説明: MySQLの最適化は、構造最適化(スキームの最適化)とクエリの最適化(クエリの最適化)に分かれています。
#1、左端の接頭原理に一致する、上記 #2、主キーが外部キーが索引付けされなければならない #、順序は、グループ、オンすることにより3、列によってインデックスに現れる #4は、高い区別を選択するための指標としての列は、判別式は、カウント(異なるCOL)/カウントである( *)、 フィールドの比率は繰返さない示し、 #長い文字列の接頭辞インデックスを用いて、5 「」 ' #6、インデックス、トレードオフインデックスとDMLとの関係、DMLが挿入され、削除されたデータ操作の数を作成するにはあまりありません。 これは、インデックスの目的は、クエリの効率を改善することである、問題の重さが、あまりにも指標の確立すべきです、 我々は、テーブルのデータを変更したので、挿入、削除データ・レートに影響を与えるだろう、インデックスも再構築するために調整する必要があります 「」」 「」 ' #7、クエリが好きなため、 『%』ではない前面に。 SELECT * FROMhoudunwangWHEREunameLIKE 'バッキング%' - インデックスを取ります SELECT * FROMhoudunwangWHEREunameLIKE「%%裏には」 - インデックスを取ることはありません 「」」 「」 ' クエリの条件がインデックスを使用することはできませんデータ型と一致しない場合#8、 インデックスを使用せずにデジタルコンパレータ文字列。 TABLEA(ACHAR(10))を作成します。 SELECT * FROMaWHEREa = "1" EXPLAIN - 走索引 WHERE = 1 SELECT * FROM EXPLAIN - インデックスを取ることはありません インデックスを使用しないように正規表現の理由は、それが十分に理解されるべきで、SQLでなぜ正規表現のキーワードを参照してくださいすることは困難です 「」」
インデックス付きの原則: 1.最も左前方一致の原則、非常に重要な原則は、mysqlのは、常にそれが範囲クエリに遭遇するまで右に照合されます(>、< 、BETWEEN、など)は、試合を停止するには そのようなAとして = 1 及び B = 2 及び C> 3 及び D = 4 インデキシング確立(A、B、C、Dの場合 ) のシーケンスは、Dは、以下のインデックス以上であります (A、B、D、C)指標の確立を使用することができる場合、A、B、Dの順序を調整することができます。 = 2、例えば、順序外であってもよい。A = 1 及び B = 2 及び C = 3 設立(A、B、C)が任意の順序で索引付けすることができ、 MySQLのクエリオプティマイザは、インデックスがの形で識別することができます最適化するのに役立ちます 指標として、高感度の列を選択するための3、判別式は、COUNT(DISTINCT COL)/ COUNT(*され、フィールドの割合は省略する)を示し 以下の割合が大きいが、我々はレコード数をスキャンし、唯一のキーの区別が1度であり、いくつかの状態は、男女差別がビッグデータの先頭が0でフィールドがあり、 誰かが求めることができることを、パーセンテージでの経験、それは何ですか?別のシーンを使用して、この値は、決定することは困難です 我々は、0.1以上、すなわち、記録された10回の走査の平均であることが要求されている一般的なフィールドに参加する必要があります 4.評価指標欄に参加し、カラムには、このようなFROM_UNIXTIME(CREATE_TIME)=「2014年5月29日には、「クリーン」のまま、」インデックスに使用することはできません その理由は単純で、B + 、比較するために機能するフィールド値がテーブルのツリーデータに格納されますが、検索では、あなたはすべての要素を使用する必要があります 明らかにそれはあまりにも多くの費用がかかります。したがって、文はCREATE_TIMEのように記述されるべき = UNIX_TIMESTAMP(「2014年5月29日」)。 拡張されたインデックスを試してみてください。5.、新しいインデックスを作成しないでください。たとえば、表の(a、b)のインデックスを追加するために今すぐインデックスを持っている、そしてあなただけが元のインデックスを変更する必要があります