その理由をご紹介
- クエリ内のファイルやHDFS HBaseのテーブルの存在には、手動でコードのMapReduceの束を書くことである場合には
- 統計的なタスクのために、唯一入手できるのMapReduceプログラマが理解できる
時間がかかり、より多くのエネルギーが有効なありません解放されます
ハイブは何ですか
ハイブは、SQL文を使用して分析の均一な層、HDFSの行動の問い合わせに関するデータ、統計、分析に基づいている
ハイブは、ツールを倉庫Hadoopのデータに基づいて、データベース・テーブルにデータファイルの構造をマッピングすることができ、 SQLクエリ機能を提供します。
ハイブは、SQLデータベースの外観を有するが、シナリオは完全に異なっている、ハイブは、データウェアハウスである大規模なオフライン統計分析、アプリケーションにのみ適しています。
ハイブは、SQL解析エンジン、SQL文がMR仕事に変換し、その後のHadoopプラットフォーム上で実行されている、急速な発展を達成
1)データ記憶装置にハイブHDFS処理
2)ハイブを達成するための基礎となるデータの解析は、MapReduceのです
3)プログラムの実施は、糸上で実行されています
4)ハイブのコンテンツが書き込み少ない読まれ、データの書き換えや削除をサポートしていません。
5)ハイブテーブルはちょうど定義テーブル、すなわち、テーブルメタデータのような、純粋に論理的なテーブルです。Hadoopのは、基本的にデータストレージの分離の目的を達成するためのディレクトリ/ファイルのメタデータであります
6)ハイブは、特に3つのプロパティを指定するために、ユーザによって指定されたデータ形式で定義されていない:
-カラム分離スペースを、「」\ T '
-行区切り文字『\ N-』
-ファイルデータを読み取る方法
ハイブの長所と短所
利点:
1、スケーラビリティ、スケールクラスタ共有の方法によってスケール拡張圧スケール:コアサーバのCPU i7-6700k 4 8サイズ、ハイブクラスターは、サービスの一般的なスケールを再起動せずに自由に拡張することができスレッド、8つのコア16スレッド、メモリ64G => 128G
2、延性、カスタム関数のためのハイブサポート、ユーザーが自分のニーズに応じて、独自の機能を実装することができます
3、優れた耐障害性、問題のノードがあっても、SQL文がまだ実行を完了することができます保証することができます
短所:
。1、ハイブは、レコードレベルのCRUD操作をサポートしていないが、ユーザがファイルにクエリ結果によって新しいテーブルまたはクエリを作成することができる(現在選択されたレコードレベルのサポートインサートのハイブ-2.3.2バージョン)
2は、ハイブクエリの待ち時間が非常に深刻なされ、起動プロセスのMapReduceジョブが長い時間のために消費するので、それはインタラクティブなクエリシステムで使用することはできません。(遅いチェック)
3、ハイブは、取引CRUDサポートしていません(彼らは、それは主に処理する2レベルのデータであるOLAP(オンライン分析処理)の代わりに、OLTP(オンライントランザクション処理)のために使用されていないため、CRUDませんが)。
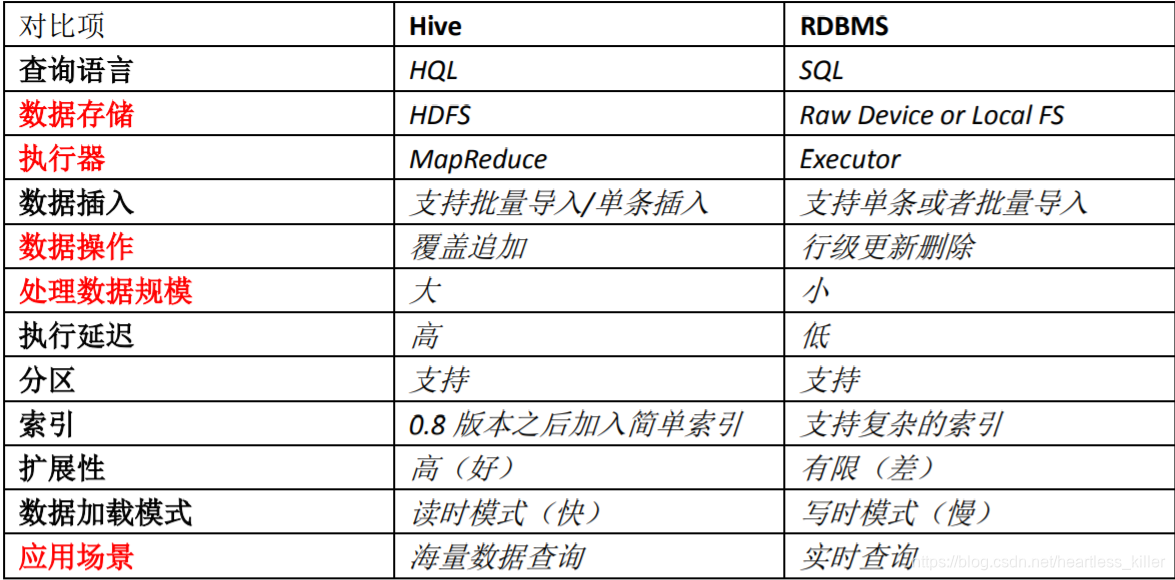
コントラストハイブとRDBMS
 要約:
要約:
ハイブは、SQLデータベースの外観を有するが、シナリオは完全に異なっている、ハイブは、データウェアハウスである大規模なオフライン統計分析、アプリケーションにのみ適しています。
従来のリレーショナルデータの特徴と比較
-
異なるハイブファイルとリレーショナル・データベース・ストレージ・システムは、HDFS(Hadoopの分散ファイルシステム)ののHadoopを使用してハイブ
リレーショナルデータベースサーバ・ファイル・システムに対してローカルです。 -
計算モデルは、MapReduceのを使用してハイブ、およびリレーショナルデータベースモデルは、独自のデザインの計算です。
-
リレーショナルデータベースは、ビジネスのリアルタイムクエリのために設計されており、ハイブは、大規模なデータ設計をマイニングデータを行うことです、貧しいされています
-
ハイブは、簡単にこれはHadoopの継承され、そのストレージ容量と演算能力を展開し、これよりもはるかに悪いリレーショナルデータベースハイブ。
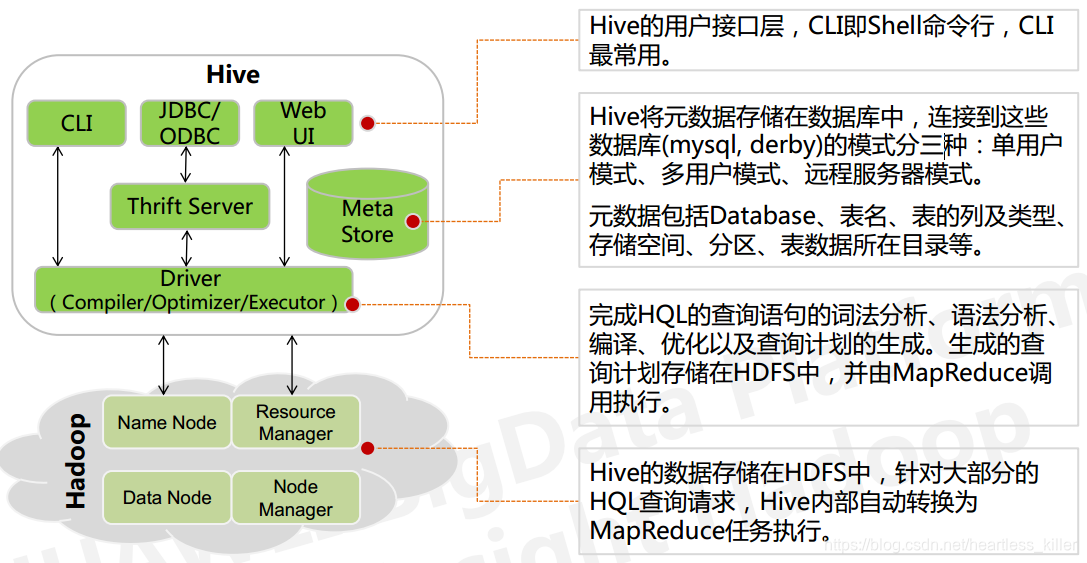
ハイブアーキテクチャ
ハイブデータ編成
1、データベース、テーブル、ビュー、およびパーティションテーブルデータを含むハイブメモリ構造。データベース、テーブル、パーティションなど、HDFS上のディレクトリに対応します。HDFSに対応するディレクトリ内のファイルに対応するテーブルデータ。
読み出しモードはハイブ(スキーマに読む)であるので、図2に示すように、すべてのデータが、データ・ストレージ・フォーマットを特化、HDFSハイブに格納されていない、TextFileの、SequenceFile、rcfileのまたはカスタムフォーマットをサポート
テーブルを作成するとき3、唯一のハイブデータと列区切り線区切りを伝える必要があり、ハイブあなたはデータを解析することができます
-
ハイブ既定の列区切り文字:制御文字はCtrl + A、\のX01ハイブ
-
ハイブデフォルトの行区切り:改行\ nは
4、ハイブのモデルは、以下のデータが含まれています。
- データベース:HDFSで$ {hive.metastore.warehouse.dir}フォルダディレクトリのパフォーマンス
- 表:HDFS内のフォルダの下に、データベースディレクトリのパフォーマンス
- 外部テーブル:テーブルは同様であるが、これは任意のデータ記憶場所のディレクトリパスを指定することができるHDFS
- パーティション:HDFS内のテーブルディレクトリの下にパフォーマンスのサブディレクトリ
- HDFSで複数のファイルのパフォーマンスは、フィールドの値に基づいて、同じハッシュハッシュ・テーブル・ディレクトリまたはディレクトリパーティションの下で実施された後:バケット
- ビュー:従来のデータベースと同様に、読み取り専用で、基本に基づいてテーブルを作成します
RDBMSに格納されている5、ハイブメタデータは、メタデータを除く他のすべてのデータは、HDFSに格納されています。デフォルトでは、ハイブは、簡単なテストのためにのみ適した唯一のセッション接続を可能にする、組み込みDerbyデータベースに格納されたメタデータ。実際の生産環境、NAは、マルチユーザーセッションをサポートするために、あなたはメタデータベースとしてMySQLを使用して、別のメタデータベースを必要とする、MySQLの内部ハイブは良いサポートを提供します。
6、表、外部表、パーティションテーブルとテーブルのバケットにハイブ内側テーブル
内部および外部表の違い:
- 内部テーブルを削除し、テーブルのメタデータとデータを削除
- テーブル内部テーブルを作成します
- 外部表にデータをインポートして、データが外部のデータテーブルはそのことではないことを意味し、独自のカタログ、下のデータウェアハウスに移動されていない
独自の管理します!
- 外部表を削除し、削除メタデータ、削除しないでデータを行います
- 外部表の場所「hdfs_path」外部表の作成(ファイルである必要があります)
- 、ハイブだけ削除する場合、外部テーブルが削除された
メタデータの外部表は、データが削除されません!
内部表および外部表は、選択するために使用しました:
ほとんどの場合、それらの間の差は明らかではなかった、ハイブ内のすべての処理されたデータならば、内部テーブルを選択する傾向があるが、ハイブおよびその他のツールは、同じデータセットに対して処理する場合は、外部表がより適切です。
HDFS上の初期データに格納された外部のテーブルにアクセスし、その後内部テーブル共存にハイブのデータにより変換
外部表を使用すると、異なるデータセットスキーマのための複数のシーンです
これは、HDFSに格納されたデータだけが、新しい抽象化を提供し、実際にハイブ、外側テーブルとの間の差と内側テーブルから見た、選択された比較を使用することができます。むしろHDFSに保存されたデータを管理するよりも。だから、関係なく、あなたはディレクトリテーブルハイブに格納されたデータに操作を追加または削除することができ、内部テーブルまたは外部表を作成していません。
パーティションテーブルの
パーティションテーブルの本質は次のとおりです、データ・ファイルのディレクトリパーティションのサブディレクトリにテーブルを作成するので、クエリの時に、MRプログラムは、データパーティションのサブディレクトリのために処理されてもよいことに、読み込まれたデータの範囲を狭めます。
例えば、歴史のウェブサイトを閲覧することは歴史がテーブルを格納するために構築する必要があります閲覧、毎日生産、しかし、時には、私たちはその日のの歴史を分析する必要があるかもしれません
あなたが毎日、パーティションテーブルについては、この表を構築することができ、時間をデータリードのパーティション特徴;
もちろん、日々のパーティションのディレクトリは、ディレクトリ名(パーティションフィールド)があるはずです
パーティションテーブルとサブテーブルバレル差:
ハイブデータテーブルには、いくつかのフィールドの操作、詳細なデータ管理に応じて分割することができ、それはいくつかのクエリが速くできるようにすることができます。一方、表およびパーティションはさらにバケット、同様の原理HashPartitionerサブバレルテーブル原理およびMapReduceのプログラミングに分けることができます。
パーティションとサブ管理データの絞り込みの両方浴槽が、パーティションテーブルを区別するために手動で追加されたハイブモードを読み取るため、データがパーティションチェックモードに追加されていない、データパケットバケットテーブルは、特定のバケットに応じて分割されます複数のファイルのハッシュハッシュフォームフィールドなので、データの精度が非常に高いです
