EDITORIAL概要:
1. ONにinnodb_file_per_tableを推奨パラメータセットので、テーブルをdrop tableコマンドを介して、単一のファイルとして格納されていることを、システムがファイルを削除します。そして、それが削除されたテーブル、スペースが回復されていない場合でも、共有テーブルスペース内にある場合
2.テーブル全体を削除するには、表領域を再利用するためにdrop tableコマンドを使用することができます。
ラベルされた再利用可能な3.deleteスペースrecoveryコマンドだけでなく、
4.削除レコードとデータ・ページは、スペースを再利用することができますが、レコードは、特定の範囲、および無制限のデータページ内で再利用することができます。
5. CRUDボイドは、データテーブルを再構築することによって修復されることがあります。(5.5および以前のバージョンは、オンラインで行うことができない、5.6は後に、それはブロックせずに[オンライン]書き込みデータを再構築することができますが、安全のために、オンラインGH-OSTをお勧めします)
関係6.Onlineとのインプレース:DDLプロセスがオンラインであれば、それはのインプレースでなければなりません。(例えばフルテキストインデックスとインデックス・スペースの追加など)は必ずしも反対ではありません
7.最後に、テーブルおよびALTERテーブルをテーブル差を再構築する3つの方法を分析し、最適化テーブルスポーク
あなたはあまりにも多くの空間データベースを取り込むことにより発生した、テーブルのデータが半分に削除されますが、テーブルファイルのサイズがまだ問題が変更されていないことがわかりましたか?
この記事では、この問題を解決する方法を参照するには、データベースのテーブルスペースの回復について話しています。
私たちは、最も広く使用されているMySQLのInnoDBエンジンのために議論します。
:InnoDBのテーブル、すなわち二つの部分から成り、テーブル構造定義およびデータ。
MySQLの8.0以前のバージョンでは、テーブル構造は、.frmファイルのサフィックスに存在しています。そして、MySQL 8.0のバージョンは、システムデータテーブルにテーブル構造を定義することができました。テーブル構造はスペースが小さいによって占め定義しているので、私たちは、今日議論されているメインテーブルデータです。
テーブルデータは表スペースが存在して共有することができ、また、別のファイルであってもよいです。この動作は、パラメータによって引き起こされるinnodb_file_per_tableを コントロール:
このパラメータはOFFに設定されている1、すなわち一緒にデータ辞書と、表スペース・共有システムにおけるデータテーブルことを示しています。
このパラメータはONに設定されている2は、それぞれのInnoDBテーブルデータの.ibdの拡張子を持つファイルに格納されていることを示しています。
MySQLの5.6.6バージョンを起動すると、デフォルト値がONになっているのです。(かかわらずのMySQLのバージョンの推奨、この値はONに設定されます)
、のでテーブルは簡単に別のファイル管理として格納されている drop tableコマンドによって、システムは、ファイルを削除します。そして、それは共有テーブルスペース内にある場合、テーブルを削除した場合でも、スペースは回復されません。
以下の議論は展開まで、このセットに基づいています。
上述したように、テーブル全体を削除するには、再利用表スペースにdrop tableコマンドを使用することができます。
しかし、シーンがよりデリートデータ消去の行である、あなたは最初に問題を抱えている:テーブル内のデータは削除されますが、表スペースが回復されていません。
データ削除処理
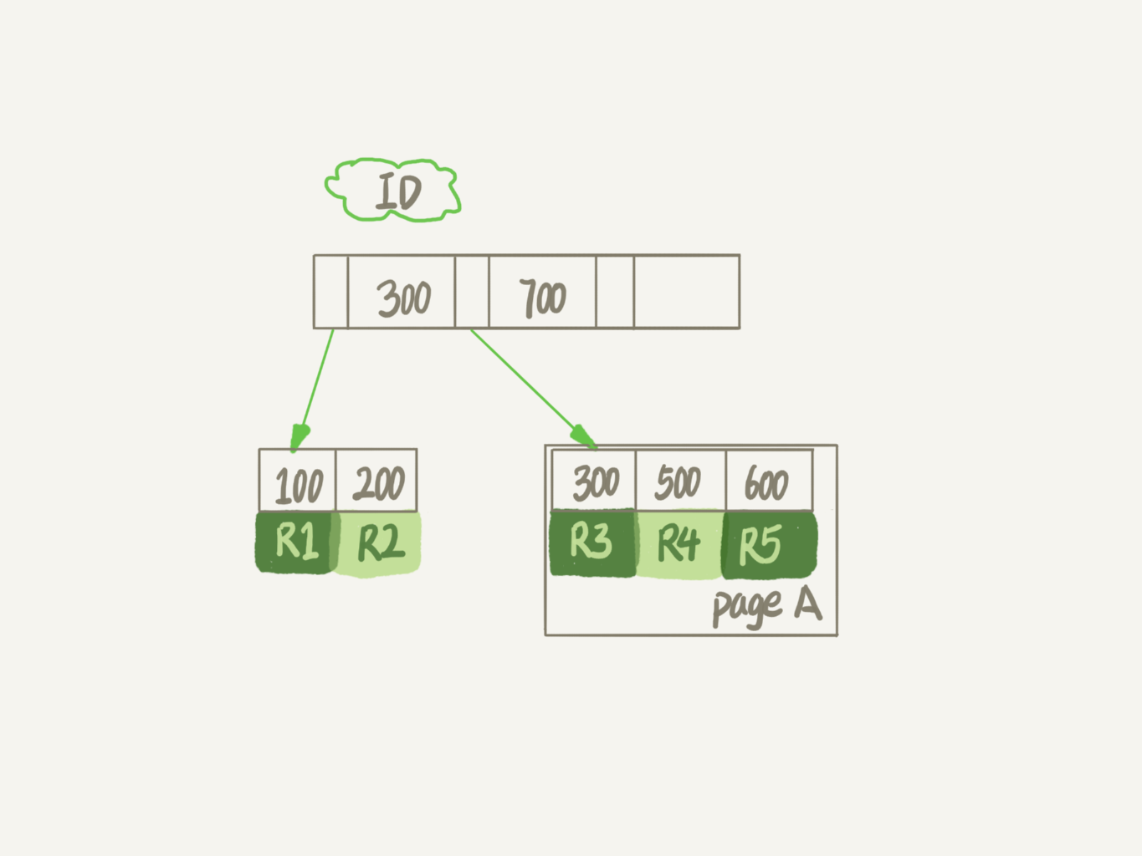
あなたはこのレコードR4、InnoDBエンジンを削除したいときだけR4は、このレコード削除のマークが付けられます。IDを挿入した後300と600との間に再び記録されている場合、この位置は、多重化されてもよいです。ただし、ディスク・ファイルのサイズとは、縮小することはありません。
InnoDBのデータは、我々があれば、ページ単位で格納されたデータ・ページ上のすべてのレコードを削除し、データのページ全体を再使用することができます。
しかし、多重化されたデータ・ページの記録と多重化は異なっています。
、限られた範囲の条件を準拠したデータを記録する多重化。このレコードが削除された後、IDがライン400内に挿入された場合R4、上記の例では、多重化されてもよいです。IDが挿入されている場合は、ライン800で、それは再利用できません。
ページ全体は、後の任意の位置に多重化することができるB +ツリーから離陸します。
データ利用の隣接する2つのページが非常に小さい場合、このシステムは、データの他のページが再利用可能としてマークされ、1ページのデータの2つのページに収まります。
我々は、すべてのデータページを削除するには、deleteコマンドを使用して、データのテーブル全体を置けばさらに、再利用可能としてマークされます。しかし、ディスク上に、ファイルが縮小されていません。
明白な、deleteコマンドは、「再利用可能」のマークが付けられのみ、レコードの位置、またはデータ・ページですが、ディスク・ファイルのサイズは変更されません。
言い換えれば、削除コマンドによって、表領域を再利用することはできません。スペースが使用されていない間、これらは見た目のように、再利用することができ、「穴。」
実際には、データのみとなり、空洞を引き起こすデータを挿入することができます削除されません。
データはインデックスに従って昇順に挿入された場合、インデックスはコンパクトです。データがランダムに挿入されている場合でも、それはデータ・ページ分割インデックスを引き起こす可能性があります。
上記の数値は、フルページAを前提とし、その後、私は行を挿入する必要があり、何が起こるのだろうか?
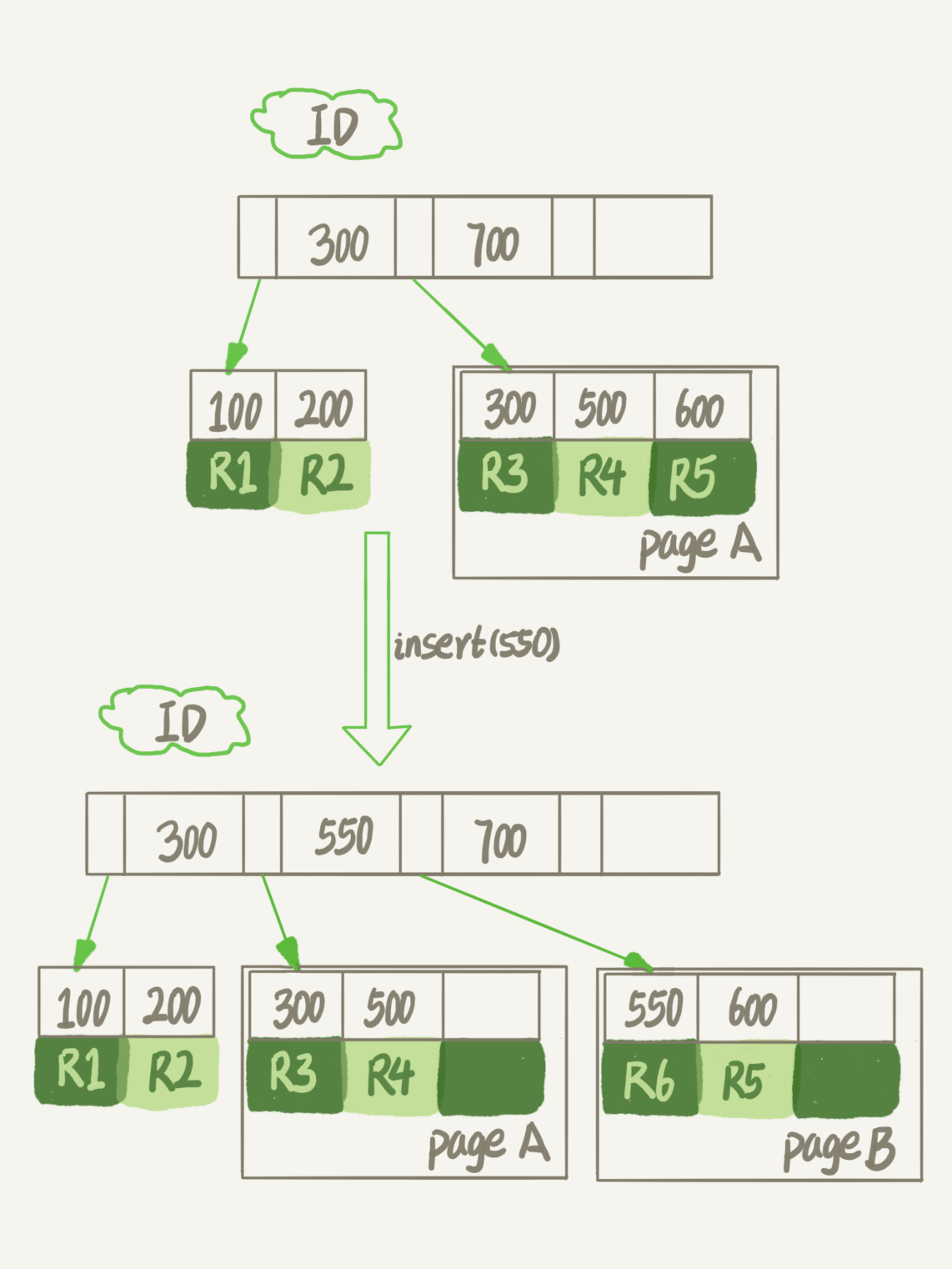
あなたはので、フルページAの場合、挿入データIDが550で、それはもはや、データを保存するために新しいページページBのために適用しなければならないことを見ることはできません。
分割されたページの完了後、ページAは、中空の左端に(注:実際には、位置は、一つのレコードが空である以上であってもよいです)。
また、インデックスの更新値は、として理解することができる古い値を削除し、その後、新しい挿入した値を。当然のことながら、これは空の原因です。
だから、テーブルを変更するには、追加および削除の多くの後、それは空があるかもしれないです。
復興テーブル
あなたは今、テーブルAを持っている場合、あなたはそれをどのように行うことができ、存在する空のテーブルを除去するために、行われるスペースのニーズを縮小?
あなたは、表A、表Bと同じ構造、および昇順に主キーIDを作成することができ、データはライン毎に読み出され、表A表Bに挿入します
新しいテーブルための主キーインデックステーブルA、テーブルBの穴は、それが存在しないように、テーブルBです。明らかに、主キーインデックステーブルBよりコンパクトに、また、より高い使用率データページ。操作は表BにAを交換し、完了した後、我々は、表B、表A表Bからの輸入データとして一時テーブルを置く場合は、実際には、表Aスペースの縮小となります。
あなたはできるテーブルAエンジン=のInnoDB変更するテーブルを再構築するためのコマンドを。MySQLの5.5バージョンの前に、私たちが説明してきたプロセスが違いに似ていて、このコマンドを実行し、独自に作成する必要はありませんだけで、一時テーブルBである、MySQLは自動的に古いテーブルを削除し、データ交換のテーブル名をダンプします。

図3
もちろん、ほとんどの時間ステップは、一時テーブルにデータを挿入するプロセスである過ごす過程で、表Aに書き込まれる新しいデータがある場合、それはデータの損失を引き起こします。
このように、全体のプロセスDDL、表Aを更新することはできません。言い換えれば、これはDDL Onlineのではありません。
でオンラインDDLのMySQL 5.6のバージョンが最初に導入された最適化された業務プロセスの。
オンラインDDL、テーブル再構成処理の導入後:
一時ファイル、すべてのデータ・ページのスキャンテーブルの主キーを作成します。1.。
ページ・テーブルA B +ツリーを生成2.記録データが一時ファイルに格納されています。
3.ログ・ファイル(行ログ)に記録されたAのすべての操作を一時ファイルを生成する処理は、対応する数字はSTATE2状態です。
4.一時ファイルが生成され、操作ログファイルアプリケーション内の一時ファイルには、表A同じデータファイルの論理的なデータを得るために、対応する図は、STATE3の状態です。
表A一時ファイルの交換用データファイル。
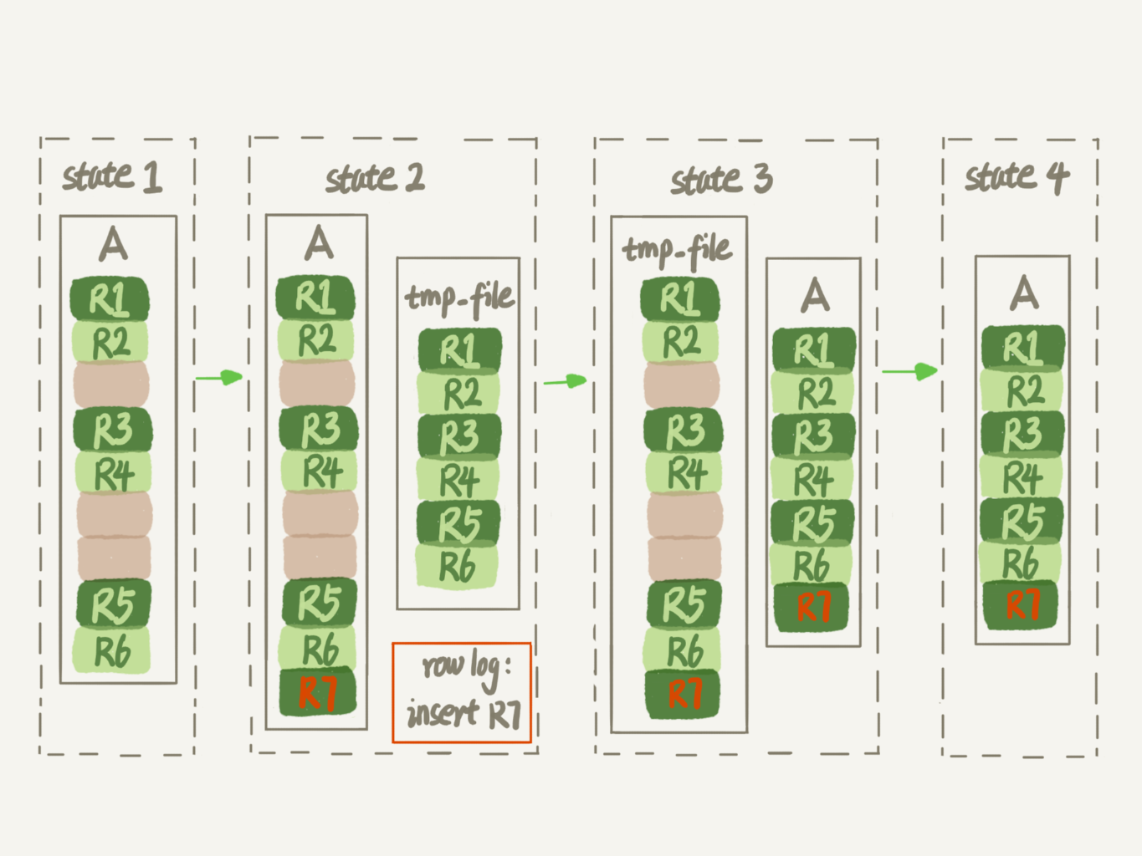
図4
記録再生操作ログファイルには、この機能、復興テーブルのプログラムが存在する、表Aは、操作への追加や削除を許可しないので、以前のバージョン5.5の手順とは異なり、見ることができますことは、それです。これは、オンラインDDLの名前の源です。
いくつかは、あなたがオンラインDDLを呼び出すことができますので、DDL MDLの書き込みロックの前にそれをもたらすことです、求めることができますか?
確かに、ブート時の取得のMDLの書き込みロックする必要がありますが、ロックのALTER文では、あなたが実際に書き込み、読み取りロックに縮退にデータをコピーする前に。
なぜそれが退化する必要がありますか?オンライン達成するために、MDLは、CRUD操作をブロックしないロックをお読みください。
あなたはそれをアンロックしていないのはなぜ?自分を守るために、DDL同時に行うこのテーブルの上に他のスレッドを禁止します。
大きなテーブルの場合は、オンラインDDLは、このステップの実行中にCRUD操作を受け入れることができ、一時テーブルにデータをコピーする最も時間のかかるプロセスです。
だから、全体のプロセスのDDLに比べ、ロック時間が非常に短いです。ビジネスのために、それはオンラインとみなすことができます。
上述した再構成法は、データテーブルをスキャンして元の一時ファイルを構築します。大きなテーブルの場合、この操作は非常にCPUとIOリソースを消費しています。したがって、オンラインサービスであれば、慎重に制御するための時間を動作させます。あなたが運転の安全性を比較したい場合は、私はあなたがGitHubのオープンソースGH-OSTを使用することをお勧めします。
オンライン和インプレース
図3において、我々は、表Aのデータはtmp_table判明格納位置と呼ばれています。これは、一時テーブルのサーバー層に作成されています。
図4では、データのうち、表Aの再構築は、「tmp_file」内側にある、この一時ファイルは、内部のInnoDBを作成されます。
DDL全体のプロセスは、社内でのInnoDB行われます。サーバ層のため、「インプレース」名前の元で一時テーブル、「その場で」動作に移動するデータがありません。
Q:1TBのテーブルがある場合、DDLはそれのインプレースを行うことができない、ディスク1.2TBの中で、今ですか?
答えはノーです。そのため、tmp_fileも一時的なスペースを取ります。
この文ALTER TABLEトンエンジンのテーブルを再構築する= InnoDBは、実際には、含意は次のとおりです。
ALTER テーブル Tエンジン= InnoDBは、ALGORITHM =インプレース。
表のインプレース対応するコピーが道であると、使用方法は次のとおりです。
ALTER テーブル Tエンジン= InnoDBは、ALGORITHM =コピー。
あなたはアルゴリズムを使用=コピーすると、コピープロセスは、図3に対応した動作で、必須のテーブルを示しています。
しかし、あなたはまだオンラインでのインプレースが意味あることはない、と感じて?
まあ、それは正確に、しかし復興テーブル内のこのロジックはそれだろう正確です。
例えば、私はInnoDBテーブルにつもりならば、フィールドのフルテキストインデックスを追加し、文言は次のようになります。
ALTER テーブル Tの追加 FULLTEXT(FIELD_NAME)。
このプロセスは、インプレースですが、非オンラインのCRUD操作をブロックします。
あなたは、これら二つの間の関係は、論理的、そして、のように要約することができますされているものを言う場合:
1. DDLオンラインプロセスそれがあれば、それはのインプレースでなければなりません。
2. DDLのインプレースで必ずしもターンでは、オンラインおそらくそこではありません。MySQLの8.0のように、このような場合は、フルテキストインデックス(FULLTEXTインデックス)と空間インデックス(空間インデックス)を追加します。
差の最適化テーブル、テーブルを再構築するテーブルと、ALTERテーブル3つの方法で分析します
デフォルトは、図3のフロー4上でスタートのMySQLバージョン5.6、ALTERテーブルtエンジン= InnoDBの(即ち再作成)1.。
2.analyzeテーブルtが実際にテーブルを再構築していないが、インデックス情報テーブルは再集計、データを変更しない、プロセスは、MDLがロックを読んで追加します。
3.optimizeテーブルT +再作成分析に等しいです。