ディレクトリ
正規表現-この記事では、私は知識やプラットフォームに依存しないを説明します。
学生のために、この用語は、非常に奇妙なことかもしれないが、私は、学生が「登る」という言葉に非常に敏感になると考えています。
はい、知識のポイントを説明するため、この記事では、私たちが必要なシーン情報のうち、「上昇」に適用することができます。
まあ、騒ぎ、我々は今、それを説明するためにこのブログの記事の主な内容を始めます!
まず、私が何であるかを説明する正規表現:
定義:
定義:いわゆる正規表現手段:
単一の文字列マッチングは線や文字列の構文規則のシリーズを記述するために使用されます。それは実際にあるルール。
Javaの、正規表現の処理では方法のjava.util.regex Patternクラスインチ
だから、私は正規表現の紹介の後に正規表現の定義の理解で構成ルールを:
構成ルール:
A:文字:
X-文字x。例:「」文字Aを表し
\バックスラッシュ文字を。
\ nは改行(ラインフィード)( '\ u000A')
\ R&LTキャリッジリターン( '\ u000D')
------------------------- -------------------------------------------------- -
B:文字クラス:
[ABC] 、B又はC(シンプル)
[^ ABC]任意の文字に加えて、B又はC(負)
[A-ZA-z]はAからZ、Z又はA、2〜含む文字(範囲)
文字[0-9] 9に0を含みます
------------------------------ ----------------------------------------------
C:事前定義文字クラス:
任意の文字、そして、あなたはそれを表現する方法?。
\ dは数字:[0-9]
\ワード文字W:[-ZA-Z_0-9]は
これらのものを持っている必要があり、正規表現でのフォームの言葉に物事を作ります
\ Sは空白文字にマッチし
--------------------------------------------- --------------------------------
D:境界マッチャー:
行の先頭^
$行の末尾
\ bは単語境界は、
単語文字の場所ではありません。
-------------------------------------------------- --------------------------
E:貪欲数量:
?X- X-、またはそのような「」空の文字列ではないんですが、一度
X * X 1に等しい倍と考えられるよりも、ゼロ倍以上
X + X、一つ以上の
X {n}はX、正確にn回
X {N} X、少なくともn回
X {N、M} X、少なくともn個回以上、上限メートル倍
ここでは、コードとコメントを通じて再びI上記組成のルールを説明します:
regx="[a,b,c,d,e,1,2,3]"; //是列表中的某一个字符就行
regx="[a-z]"; //是小写字母就行
regx="[0-9]"; //是数字字符就行
regx="\\d"; // 这个等同于 [0-9]
regx="[A-Z]"; //是大写字母就行
regx="[a-zA-Z0-9]"; //是26个大小写字母 或者 数字之一就行
regx="\\w"; //等同于 [a-zA-Z_0-9]
regx="."; //. 匹配单个任意字符
regx="\\."; // \\ 转义符,这里的“\\.”表示只匹配“.”字符
regx = ".."; // 表示匹配两个任意字符
regx = "[^A-Z]"; //取反,不是大写字母就行
regx="|"; // |表示 或者关系
regx="\\|"; // 这里的 “\\.” 表示只匹配“|”字符
regx="&"; // &表示 与关系
regx="\\s"; //匹配空格
//量词 ? 一次或一次也没有 空串就是没有出现
regx="a?";
//* :零次或多次 一次也算多次
regx="[a-z]*";
//+ :一次或多次
regx="[0-9]+";
regx="\\w+";
//恰好几次
regx="[0-9]{5}"; //表示只匹配5个数字字符的字符串
//至少几次
regx="[a-z]{5,}"; //表示只匹配至少5个但只能全是小写字母字符的字符串
//一个范围 大于等于5 小于等于10
regx = "[a-z]{5,10}"; //表示只匹配 5~10个小写字母 组成的字符串まあ、今では「正規表現」の基本的な使用について学生に表示する例であったであろう:
今、私たちは尋ねる:ソース文字列の等号はすべて削除します
package com.youzg.about_regular_expression.test
public class DeleteEqualSign {
public static void main(String[] args) {
String str="aaaa=bbbb=cccc=dddd"; //aaaabbbbcccdddd;
String replace = str.replace("=", "");
System.out.println(replace);
}
}そこで、我々は結果を見て:
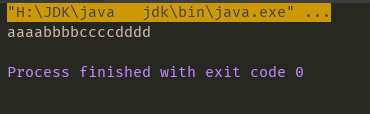
だから、この例を、私は学生が予備的な理解を持っている知識を持っていると信じています。
:次に、私はこれらのメソッドの使用のいくつかの例を通してそれを統合する学生をもたらすために来た
ユーザーが有効な電子メールを入力したかどうかを判断するために:要件
package com.youzg.about_regular_expression.test
import java.util.Scanner;
public class CheckE-mail {
public static void main(String[] args) {
String emailRegx="[a-zA-Z]\\w{5,17}@(163|sina|google)\\.(com|cn|net|org)";
Scanner sc = new Scanner(System.in);
String inputString = sc.nextLine();
boolean matches1 = inputString.matches(emailRegx);
System.out.println(matches1);
}
}さて、結果での外観をしてみましょう:

要件:ソートにデジタル与えられた文字列
package com.youzg.about_regular_expression.test
import java.util.Arrays;
public class SortString {
public static void main(String[] args) {
/*
*
* * 分析:
* a: 定义目标字符串"91 27 46 38 50"
* b: 对这个字符串进行切割,得到的就是一个字符串数组
* c: 把b中的字符串数组转换成int类型的数组
* (1): 定义一个int类型的数组,数组的长度就是字符串数组长度
* (2): 遍历字符串数组,获取每一个元素.将其转换成int类型的数据
* (3): 把int类型的数据添加到int类型的数组的指定位置
* d: 排序
* e: 创建一个StringBuilder对象,用来记录拼接的结果
* f: 遍历int类型的数组, 将其每一个元素添加到StringBuilder对象中
* g: 就是把StringBuilder转换成String
* h: 输出
*
*
* */
String str = "91 27 46 38 50000 50 5 9 9000";
String[] strings = str.split("\\s+");
int[] ints = new int[strings.length];
for (int i = 0; i < strings.length; i++) {
ints[i]=Integer.parseInt(strings[i]);
}
//排序
Arrays.sort(ints);
//遍历 int 数组 凭借成字符串
StringBuilder sb = new StringBuilder();
for (int i = 0; i < ints.length; i++) {
sb.append(ints[i]).append(" ");
}
String string = sb.toString().trim();
System.out.println(string);
}
}レッツは、次の結果を見て:
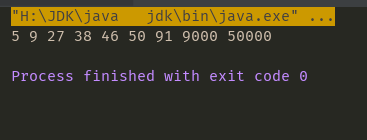
まあ、今、私は正規表現を導入する必要が非常に強力です- 機能を置き換え:
正規表現関数を置き換えます。
この知識は、私が例で示さなければならない:
要件:デジタル与えられた文字列が削除されます
package com.youzg.about_regular_expression.test
public class RemoveDigit {
public static void main(String[] args) {
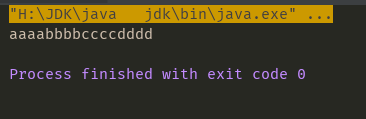
String str2 = "aaaa=1111125522bbbb55444444cccc6665444444dddd";
//根据正则表达式去替换
String s = str2.replaceAll("[0-9]+", "");
System.out.println(s);
}
}
だから、3例以上で、私は表現の基本的な方法は、すでに精通している定期的な使用のための学生を信じて、そして今、私は最後の正規表現についての知識を説明するためだ-正規表現の取得機能
正規表現の取得機能:
正規表現の導入前に、この機能では、私は、パターンとMatcherの2つのクラスを最初に導入しています:
順序が明確に使用されるような知識のこれらの二つのカテゴリーでは、我々はあまりにも多く、限り知っている必要はありません。
一般的な呼び出しシーケンス彼らは以下のとおりです。
Pattern p = Pattern.compile(正则表达式);
Matcher m = p.matcher(待检测表达式);
boolean b = m.matches();だから、今、それがどのように正規表現の取得機能示すための一例であり、
必要条件:文字列で指定して抽出されたピックを出力し、サブ三文字は:
package com.youzg.about_regular_expression.test
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetTheActivePart {
public static void main(String[] args) {
//需求:获取下面这个字符串中由三个字符组成的单词
String str="da jia ting wo shuo, jin tian yao xia yu, bu shang wan zi xi, gao xing bu?";
//1.三个字符组成的单词 的正则 [a-z]{3}
//2.模式器和匹配器配合起来,可以根据正则获取出符合正则的字符串
//获取模式器
Pattern p = Pattern.compile("\\b[a-z]{3}\\b");
//获取匹配器
Matcher matcher = p.matcher(str);
while (matcher.find()){
String group = matcher.group();
System.out.println(group);
}
}
}結果は次の通りです:
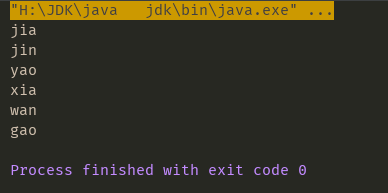
正規表現の取得機能と同様に、フロントエンドの知識は、我々は我々が知りたい情報のうち、「登る」することができますので、それもあります。