A、expainプラン分析
第二には、インデックスを作成します
第三に、特定の最適化
1、最大
一般的な指標は、解決するために作成しました

2、数
(フィールド名)をカウントすると、カウント統計、COUNT(*)は、銀行はまた、空のヌルにカウントされる場合は、NOT NULLフィールドには、インデックスと同じ最大を作成し、統計に行きます
3、どのように、注文回避使用filesortレコードで注文します

1、最初のケース分析、インデックス化、次の順序で(名前、年齢、給与)
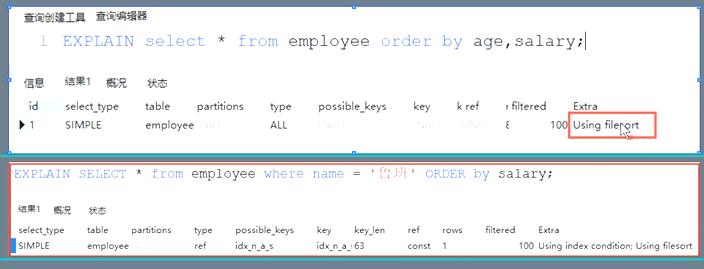
図2に示すように、第三のケース
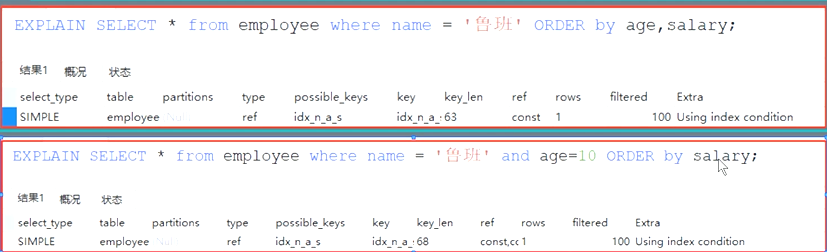
4、同順の規則に一時的に、コンプライアンスを使用して回避する方法グループ化によるグループ
5、リミット
6、存在で、小さなテーブル駆動大テーブル
5を操作、5000倍、最もリソースを消費する接続接続されている ために(INT I = 0 ; I < 5 ; I ++ ){ ため(INT I = 0 ; I < 5,000 ; I ++ ){ } }
select * from t1 where id in (select id from where t2) 执行顺序是,先t2,再t1,t2是小表,t1是多大表 for(t2){ for(t1){ } }
select * from t1 where exist (select 1 from where t2.id = t1.id) 执行顺序是,先t1,再t2,t2是小表,t1是多大表,所以这种就会t1大表驱动小表,不推荐 for(t1){ for(t2){ } }
7、索引失效的条件