記事のディレクトリ
I.はじめに
SQL文について学ぶ、3つの段階があります。
第一段階:SQL文を理解するためには、ビジネスニーズに基づいてCRUD機能を達成することができ、
2段目:、効率的なインデックスを作成する方法を、どのように防ぐために、データベースのパフォーマンスのボトルネックを分析locateデータベースを最適化する方法を知ることができ、SQLをデータベースインデックスの原則の基本的な原理を理解します移植;
第三段階:、アーキテクチャへのデータセキュリティを傾向がある、マスター、別個の読み取りおよび書き込み、データセキュリティ、バックアップジョブから分散データベース、ライブラリサブサブテーブルを、達成することが可能であり、合理的な設計のデータベーステーブル構造とすることができます。
この記事では、後者の二つのステージがブログの作者後に与えられます、検索機能を変更するために追加および削除のビジネスニーズを満たすために、ステージ、柔軟な使用のSQL文を記述します。この論文は、「挿入データ、削除データ、更新データ」を含む二つの部分に分割され、「クエリデータ。」
第二に、データの挿入、削除データ、更新データ
2.1データの挿入
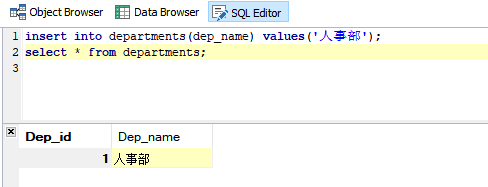
要件:挿入データ
SQL文:
insert into departments(dep_name) values('人事部');
select * from departments;
結果:
削除データへ2.2
要件:削除シリアルナンバー2従業員情報
SQL文:
delete from employees where emp_id = 2;
select * from employees;
結果:

需要:3000未満の従業員情報の削除賃金
SQL文:
delete from employees where wage < 3000;
select * from employees;
結果:

需要:空の従業員情報テーブル
SQL文:
truncate table employees;
select * from employees;
結果:

2.3アップデートデータ
要件:すべての従業員の賃金プラス$ 10
SQL文:
update employees set wage=wage+10;
select * from employees;
結果:

各従業員の省職員の給与プラス50元:需要
SQL文:
update employees set wage=wage+50 where dep_id=1;
select * from employees;
結果:

第三に、クエリデータ(全文強調)
3.1元のテーブル
データベースのバックグラウンド動作では、クエリは、変更のほとんどは、ここからだけでは説明し、関与している、最も一般的です。以下のように、二つのテーブルの従業員、部署を与えるには:
部門テーブル:

従業員のテーブル:

導入3.2 Selectステートメント
Mysql表中查询数据使用select语句来完成,select语句从数据库中查询满足条件的数据,并以表格的形式返回。select语句的基本语法如下:
| SELECT语句 | 解释说明 |
|---|---|
| SELECT子句 | 指定查询返回的列(对应后台接口的返回值) |
| FROM子句 | 指定操作的表 (对应后台接口的操作类Bean) |
| WHERE子句 | 指定查询条件 (对应后台接口的Service层业务逻辑需求) |
| GROUP BY子句 | 指定查询结果的分组条件 (对应后台接口的Service层业务逻辑需求) |
| HAVING子句 | 指定组或统计函数的搜索条件 (对应后台接口的Service层业务逻辑需求) |
| ORDER BY子句 | 指定对结果集如何排序 (对应后台接口的Service层业务逻辑需求) |
| UNION运算符 | 将两个或更多查询的结果集组成为单个结果集,该结果集包含联合查询中的所有查询的全部记录 |
3.3 最基本的select查询语句
1、查询所有数据
含义:直接查询 select * from 表名
需求:查询所有员工信息
SQL语句:
select * from employees;
运行结果:

2、查询指定列数据
含义:仅返回指定列的数据
需求:仅查询员工的姓名、性别和职位
SQL语句:
select Emp_name,Sex,Title from employees;
运行结果:

3、使用Distinct关键字
含义:distinct关键字的作用是指定结果集中返回指定列存在不重复数据的记录
需求:查询所有职务数据
SQL语句:
select Title from employees;
运行结果:

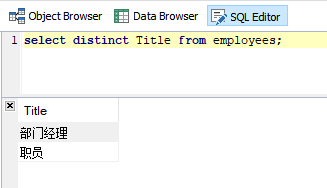
需求:查询所有职务数据,过滤掉重复数据
SQL语句:
select distinct Title from employees;
运行结果:
4、limit关键字
含义:limit关键字仅采集指定范围行
需求:查询(3,8]个员工记录
SQL语句:
select * from employees limit 3,5;
运行结果:

特殊:limit只有一个参数
需求:查询前3个员工记录
SQL语句:
select * from employees limit 3;
运行结果:

LIMIT 接受一个或两个数字参数。两个参数均必须是一个整数常量。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目,其初始记录行的偏移量是 0(而不是 1)。
如果只有一个参数,LIMIT n 等价于 LIMIT 0,n,所以说,mysql中的limit关键字和sqlserver中的top关键字效果相同
5、改变显示的列标题
含义:自定义查询结果列标题(而不是使用原表列标题)
需求:查询员工的姓名、性别、职务、工资、身份证,并显示指定的中文列名
SQL语句:
select Emp_name as 姓名, Sex as 性别,Title as 职务,Wage as 工资,IdCard as 身份证 from Employees;
运行结果:

也可以不使用as关键字

3.4 设置查询条件
1、简单查询条件
需求:查询工资在(3000,4000)的所有员工的信息
SQL语句:
select * from Employees where Wage>3000 and Wage<4000;
运行结果:

2、在查询条件中使用between关键字
需求:查询工资在(3000,4000)的员工的信息
SQL语句:
select * from Employees where Wage between 3000 and 4000;
运行结果:

3、在查询条件中使用IN关键字
需求:查询“张三”、“李四”、“王五”的信息
SQL语句:
select * from Employees where Emp_name in ('张三','李四','王五');
运行结果:

4、模糊查询
| 通配符 | 含义 |
|---|---|
| % | 包含零个或多个任意字符的字符串 |
| _ | 任意单个字符 |
| [] | 指定范围或集合中的任意单个字符,例如,[a-f]表示a~f中任意一个字符,[abcdef]表示集合中的任意一个字符,两种表示方法是一样的 |
| [^] | 不属于指定范围或集合中的任意单个字符,例如,[^A-M]表示不属于A~M中的任意一个字符 |
sql中的模糊查询是不是有点像正则匹配的意思,其实它比正则表达式容易多了
需求:查询身份证号中包含“ddd”字符串的员工的信息
SQL语句:
select * from Employees where IDCard like '%ddd%'
运行结果:

需求:查询身份证号匹配"110123?adx?"的员工的信息
SQL语句:
select * from Employees where IDCard like '110123_adx_'
运行结果:

5、使用AND和OR关键字
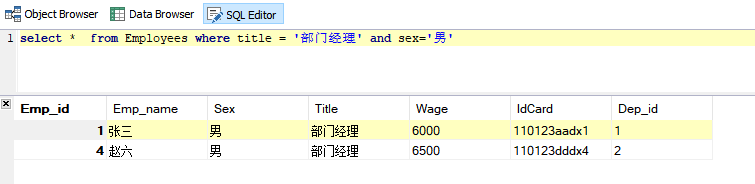
需求:查询所有男性部门经理的信息
SQL语句:
select * from Employees where title = '部门经理' and sex='男'
运行结果:
3.5 对查询结果排序
含义:使用order by子句对查询结果进行排序。排序表达式可以是一个列,也可以是一个表达式。ASC表示按照递增的顺序排列,DESC表示按照递减的顺序排列,ASC为默认值。在order by子句中,可以同时按照多个排序表达式进行排序,排序的优先级从左到右。
需求:查询员工信息,并按姓名排序
SQL语句:
select * from Employees order by Emp_name
运行结果:

需求:查询员工信息,并按性别、工资排序(先按性别排序,性别相同再按工资排序)
SQL语句:
select * from Employees order by Sex,Wage
运行结果:

3.6 使用聚合函数
1、count()函数
含义:count()函数可以用于统计记录的个数。
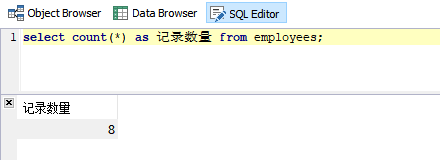
需求:统计公司员工数
SQL语句:
select count(*) as 记录数量 from employees;
运行结果:
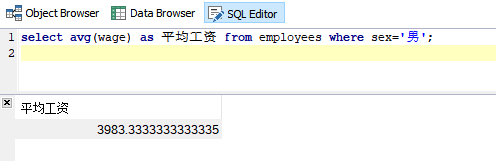
2、avg()函数
含义:avg()函数统计指定表达式平均值。
需求:统计所有员工平均工资、统计所有男性员工平均工资
SQL语句:
select avg(wage) as 平均工资 from employees;
select avg(wage) as 平均工资 from employees where sex='男';
运行结果:

3、sum()函数
含义:sum()函数用于统计指定表达式之和。
需求:统计所有员工工资之和
SQL语句:
select sum(wage) as 工资之和 from employees;
运行结果:

3.7 对查询结果分组
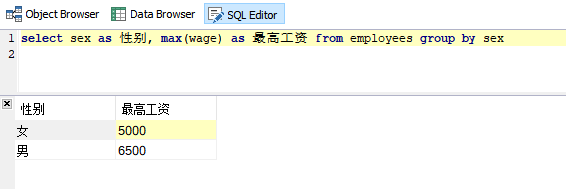
含义:当SELECT子句中包含聚合函数时,可以使用Group by子句对查询结果进行分组统计,计算每组记录的汇总值。
需求:按性别统计所有员工的最高工资
SQL语句:
select sex as 性别, max(wage) as 最高工资 from employees group by sex
运行结果:
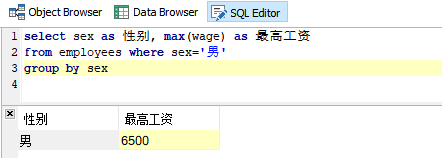
需求:统计所有男性员工的最高工资
SQL语句:
select sex as 性别, max(wage) as 最高工资
from employees where sex='男'
group by sex
运行结果:
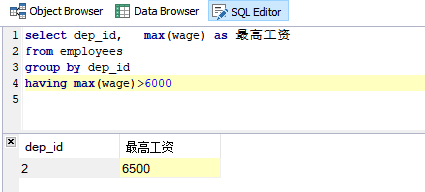
3.8 指定组或聚合的搜索条件
含义:Having子句的功能是指定组或聚合的搜索条件,having通常与group by子句一起使用。如果没有group by子句,having的作用和where子句一样。
having和where的区别:
where子句的搜索条件在进行分组操作之前应用,where子句中不可以包含聚合函数。
having子句的搜索条件在进行分组操作之后应用,having子句中可以包含聚合函数。
需求:统计最高工资超过6000的部门及其最高工资信息
SQL语句:
select dep_id, max(wage) as 最高工资
from employees
group by dep_id
having max(wage)>6000
运行结果:
3.9 连接查询
连接查询即将多个表连接起来,这里是employees表和departments表
这个点比较重要,使用三级标题“内连接”、“外连接”、“交叉连接”
3.9.1 内连接
含义:内连接使用比较运算符(最常用的是等号,即等号连接),根据每个表共有列的值匹配两个表中的行。只有每个表中都存在相匹配的记录才出现在结果集中。在内连接中,所有表都是平等的,没有主次之分。
内连接有两种实现方式,一是在where子句中设置等值条件,二是在inner join中设置等值条件,下面两种方式都会介绍。
需求:查询所有员工姓名及其所在的部门名称。
方式一:在where子句中设置等值条件
SQL语句:
select t1.Dep_name , t2.Emp_name
from departments t1 ,employees t2
where t1.Dep_id = t2.Dep_id
运行结果:

方式二:在inner join中设置等值条件
SQL语句:
select t1.Dep_name , t2.Emp_name
from departments t1 inner join employees t2
on t1.Dep_id = t2.Dep_id
运行结果:

3.9.2 外连接
含义: 参与外连接的表分为主表和次表,以主表的每一行数据去匹配从表中的数据列,符号连接条件的数据将直接返回到结果集中,对那些不符合连接条件的列,将被填上NULL值后再返回到结果集中。
外连接可以分为左外连接和右外连接两种。
1、左外连接
含义:左向外连接以连接JOIN子句左侧的表为主表,主表中所有记录都将出现在结果集中。如果主表中的记录在右表中没有匹配的数据,则结果集中右表的列值为NULL。可以使用LFET OUTER JOIN或LEFT JOIN关键字实现左外连接。
需求:查询所有部门的员工(部门departments为主表,员工employees为次表)
SQL语句:
select t1.Dep_name , t2.Emp_name
from departments t1 left join employees t2
on t1.Dep_id = t2.Dep_id
运行结果:

2、右外连接
含义:右外连接以连接JOIN子句右侧的表为主表,主表中的所有记录都将出现在结果集中。如果主表中的记录在左表中没有匹配的数据,则结果集中左表的列值为NULL。使用RIGHT OUTER JOIN或RIGHT JOIN关键字定义右外连接。
需求:查询所有员工的部门(员工employees为主表,部门departments为次表)
SQL语句:
select t1.Dep_name , t2.Emp_name
from departments t1 right join Employees t2
on t1.Dep_id=t2.Dep_id
运行结果:

需求:查询所有部门的员工(部门departments为主表,员工employees为次表)
SQL语句:
select t1.Dep_name , t2.Emp_name
from Employees t2 right join departments t1
on t1.Dep_id=t2.Dep_id
运行结果:

需求:查询所有部门的员工,该部门员工必须为null(部门departments为主表,员工employees为从表)
SQL语句:
select t1.Dep_name , t2.Emp_name
from departments t1 left join Employees t2
on t1.Dep_id=t2.Dep_id
where t2.Emp_name is null
运行结果:

3.9.3 交叉连接
含义:每个表的记录做笛卡尔积,最后得到的记录数为各个表记录数乘积之和。例如,第一个表m行,第二个表n行,则交叉连接后为m*n行。
需求:查询所有员工的姓名和所在部门名称
SQL语句:
select t1.Dep_name , t2.Emp_name
from departments t1 cross join Employees t2
运行结果:

3.10 子查询
含义:子查询是在一个SELECT语句中又嵌套另一个SELECT语句。在WHERE子句和HAVING子句中都可以嵌套SELECT语句。
四种子查询的实现:使用IN关键字连接子查询、使用等号连接子查询、使用EXISTS关键字连接子查询、在HAVING子句中使用子查询
1、IN关键字连接子查询
需求:查询和张三在同一个部门的所有员工的姓名
SQL语句:
select Emp_name from Employees where Dep_id in
(select dep_id from Employees where Emp_name = '张三')
运行结果:

2、使用等号连接子查询
需求:查询和张三在同一个部门的所有员工的姓名
SQL语句:
select Emp_name from Employees where Dep_id =
(select dep_id from Employees where Emp_name = '张三')
运行结果:

需求:查询财务部所有员工信息
SQL语句:
select * from Employees where dep_id
= (select dep_id from departments where dep_name= '财务部' )
运行结果:

3、使用EXISTS关键字连接子查询
需求:查询财务部所有员工信息
SQL语句:
select * from Employees where Exists
(select * from departments where dep_id=Employees.Dep_id and dep_name='财务部' )
运行结果:

4、在HAVING子句中使用子查询
需求:查询部门平均工资大于所有员工平均工资的记录(部门+该部门平均工资)
SQL语句:
select departments.dep_name,avg(Employees.wage) from Employees,departments
where Employees.dep_id = departments.dep_id
group by departments.dep_name
having avg(employees.wage) > (select avg(wage) from employees)
运行结果:

3.11 合并查询
意味:クエリの合成結果は、単一の結果セットには、2つの以上のクエリの組み合わせである、結果セットは、クエリ内のすべてのクエリのすべての接合線を含んでいます。
:UNION演算子の結果が、但し、その2つのクエリの組み合わせを使用して設定し
、列の順序と同じ順序でなければならない(1)列の数とすべてのクエリ結果
の列に対応するデータ型(2)適合性でなければなりません。
目的:複合クエリーは、多くの場合、詳細情報や統計情報を返すために使用されます。詳細な統計や統計情報のニーズがあるので、あなたは、統一された結果セットにクエリマージそれらを使用することができます。
要件:部門テーブル内のさまざまな部署からのクエリ情報、従業員テーブル内の様々な部門のクエリマネージャー。
SQL文:
select dep_id , dep_name from departments
union
select dep_id , emp_name from employees where title ='部门经理'
結果:

IVの概要
本論文では、MySQLを学習の最初の段階を完了するために、読者を助けるために、「挿入データ、削除データ、更新データ」と「クエリデータ」を含む二つの部分に分割されている- SQL文は、ビジネスニーズに基づいてCRUD機能を実現することができます理解しています。
スパンクコード、毎日進行!
