図1に示すように、特性カテゴリの数値
2、離散連続値属性
二値化する二値化
// *- 1-准备环境
val conf: SparkConf = new SparkConf().setAppName("stringIndexerOperation").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
// 2-准备数据
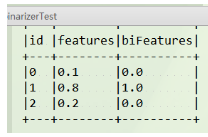
val data = Array((0, 0.1), (1, 0.8), (2, 0.2))
val df: DataFrame = spark.createDataFrame(data).toDF("id","features")
// 3-使用二值化的方法进行转换
val binarizer: Binarizer = new Binarizer()
.setInputCol("features") // 想要转化为列名
.setOutputCol("biFeatures") // 随意输入
.setThreshold(0.5) // 二值化的边界
binarizer.transform(df).show(false) // 继承transform所以这还需要transform
Bucketier分箱
// 2-准备数据
val data = Array(-0.5, -0.3, 0.0, 0.2)
val df: DataFrame = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
// 3-使用分箱的方法进行转换
// 请注意,如果您不知道目标列的上限和下限,则应添加Double.NegativeInfinity和Double.PositiveInfinity作为拆分的边界,以防止可能超出Bucketizer边界异常。
val splits = Array(Double.NegativeInfinity, -0.5, 0.0, 0.5, Double.PositiveInfinity)
val bucketizer: Bucketizer = new Bucketizer()
.setSplits(splits)
.setInputCol("features")
.setOutputCol("bucket")
bucketizer.transform(df).show(false)
// +--------+------+
// |features|bucket|
// +--------+------+
// |-0.5 |1.0 |
// |-0.3 |1.0 |
// |0.0 |2.0 |
// |0.2 |2.0 |
// +--------+------+QuantileDiscretizer分位タンク(セクションを制御することは容易ではありません)

val data = Array((0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2))
var df = spark.createDataFrame(data).toDF("id", "hour")
val discretizer = new QuantileDiscretizer()
.setInputCol("hour")
.setOutputCol("result")
.setNumBuckets(3)
val result = discretizer
.fit(df)
.transform(df)
result.show()
+---+----+------+
| id|hour|result|
+---+----+------+
| 0|18.0| 2.0|
| 1|19.0| 2.0|
| 2| 8.0| 1.0|
| 3| 5.0| 1.0|
| 4| 2.2| 0.0|3、特徴の組合せ
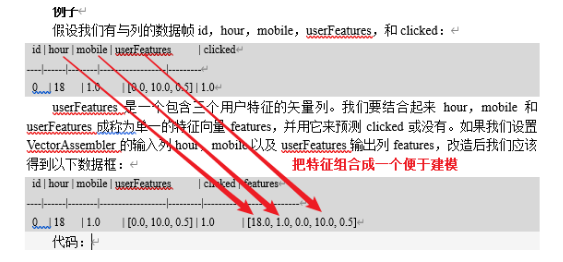
VectorAssemblerは、それが組み合わされたリストベクトル列に与えられ、変換器です。単一の特徴ベクトルに異なる変換特性によって生成オリジナルの特徴及び特性は、ロジスティック回帰および決定木などの、MLモデルを訓練するのに有用です。すべての数値型、ブールおよびベクトル型:VectorAssemblerは、入力列の次のタイプを受け入れます。各列において、値が順次入力列は、指定されたベクトルに接続されます。
// * 1-准备环境
val conf: SparkConf = new SparkConf().setAppName("stringIndexerOperation").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(conf).getOrCreate()
spark.sparkContext.setLogLevel("WARN")
// * 2-准备数据
val dataset = spark.createDataFrame(
// * 3-解析数据
Seq((0, 18, 1.0, Vectors.dense(0.0, 10.0, 0.5), 1.0))
).toDF("id", "hour", "mobile", "userFeatures", "clicked")
// * 4-VectorAssemble转换
val assembler: VectorAssembler = new VectorAssembler()
.setInputCols(Array("hour", "mobile", "userFeatures"))
.setOutputCol("features")
// * 5-得到结果
assembler.transform(dataset).show(false)
结果:[[18.0,1.0,0.0,10.0,0.5],1.0]
図4に示すように、数値データの標準化および正規化
標準化

正規化されました
MinMaxScalerは[0,1]に正規化
