参考:PythonのWebクローラーと情報抽出(技術ムークラスの北京研究所)
何Scrapyこと?

Scrapyは強力で、非常に高速なウェブクローラフレーム、Pythonは非常に良いサードパーティのライブラリである、ベースのpythonのWebクローラの技術ロードマップを実現することも重要です。
Scrapyのインストール:
直接実行するには、コマンドプロンプトウィンドウで、pip install scrapy一見ではありません。
私たちは、その後、インストール、ツイストを必要なコンポーネントをダウンロードする必要があり、ここでダウンロードしてください。
ダウンロード完全なものはこれです:

(あなたが右の自分のコンピュータのオペレーティングシステムのために、とにかく、別のバージョンをダウンロードする必要があります)
その後、我々は(通常CMDと呼ばれる)、コマンドプロンプトウィンドウを開き、実行します
pip install S:\Python\Twisted\Twisted-19.10.0-cp38-cp38-win_amd64.whl
(あなたがダウンロードしたツイストバージョンに基づいてコードの変更は)
そして、実行pip install scrapy取得します。
インストール後、実行することができscrapy -h、インストールが成功したかどうかを確認するためにテストを:

注:Scrapyない機能の関数ライブラリが、爬虫類のフレームワーク。
Scrapyクローラフレーム構造:
まず、何を見て爬虫類のフレームワークです:
Webクローラーが懸念されるため、ユーザーが使用できる半完成の機能の多くは、このフレームワークは、テンプレートの使用を制限し、ユーザーは、知っているだろう、それはこのテンプレートの操作方法に必要です。

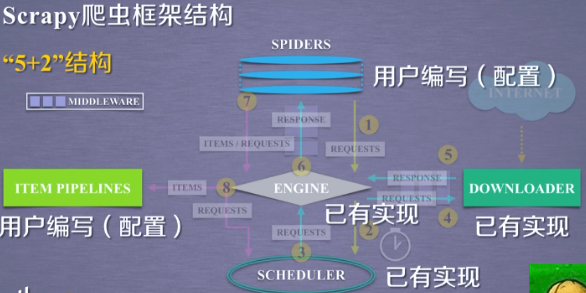
7つの部分の合計を含むScrapyクローラフレームが、我々はそれを呼び出すフレーム部の5つの主要な部分が存在する「5 + 2」構造は、さらに二つの中間体を含みます:
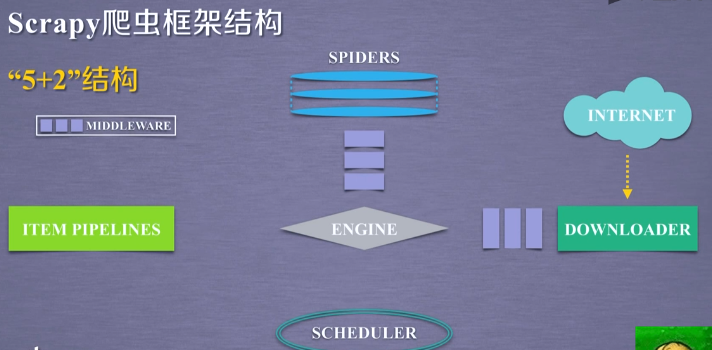
構造形成は、5つのモジュールScrapyのクローラフレームと呼ばれています。
5つのモジュールの間でデータ、ユーザによって提出ウェブクローラー要求を含む、及びネットワークから取得した関連コンテンツ、形成するために、これらの構造の間を流れるデータストリームを。
Scrapy框架包含三条主要的数据流路径:
- 第一条路径:
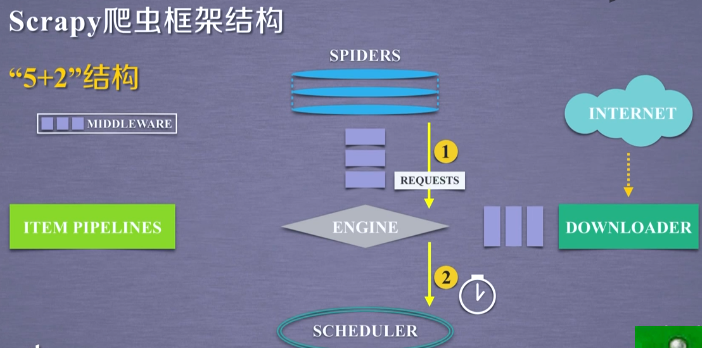
从 SPIDERS 模块,经过 ENGINE,到达 SCHEDULER。
其中 ENGINE 从 SPIDERS 的地方获得了爬取用户的请求,我们对这种请求叫REQUESTS(可以简单地把请求理解为一个url)。
那么,请求通过 SPIDERS 到达 ENGINE 之后,ENGINE 将这个爬取请求转发给了 SCHEDULER 模块。SCHEDULER 模块负责对爬取请求进行调度。
- 第二条路径:
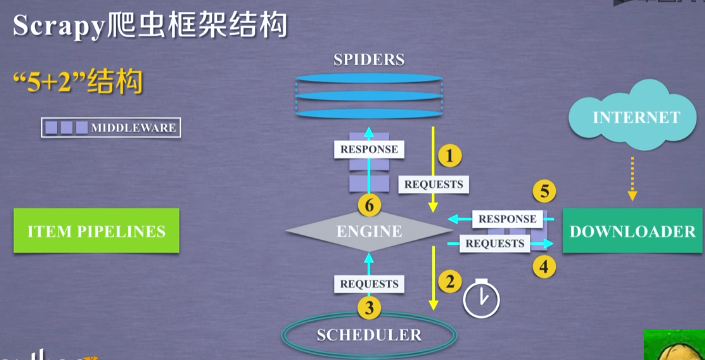
从 SCHEDULER 模块,通过 ENGINE 模块,到达 DOWNLOADER 模块,并且最终数据返回到 SPIDERS 模块。
首先,ENGINE 模块从 SCHEDULER 获得下一个要爬取的网络请求,这个时候的网络请求是真实的、要去网络上爬取的请求。ENGINE获得这样的请求之后,通过中间件,发送给 DOWNLOADER 模块,DOWNLOADER 模块拿到这样的请求之后,真实地连接互联网,并且爬取相关的网页,爬取到网页之后,DOWNLOADER 模块将爬取的内容形成一个对象,这个对象叫 RESPONSE(响应)。将所有的内容封装成一个 RESPONSE 之后,将这个响应再通过中间件 ENGINE,最终发送给 SPIDERS。
在这条路径中,一个真实的、爬取url的请求,经过 SCHEDULER、DOWNLOADER,最终返回了相关内容,到达了 SPIDERS。
- 第三条路径:
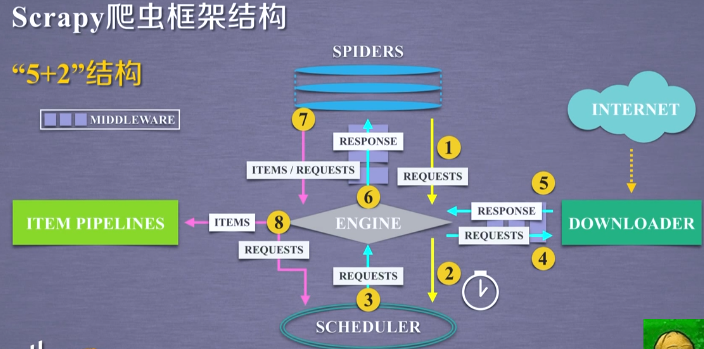
从 SPIDERS 模块,经过 ENGINE 模块,到达 ITEM PIPELINES 模块以及 SCHEDULER 模块。
首先,SPIDERS 处理从 DOWNLOADER 获得的响应(也就是从网络中爬取的相关内容),处理之后产生了两个数据类型,一个数据类型叫爬取项,另外一个数据类型是新的爬取请求。
也就是说,我们从网络上获得一个网页之后,如果这个网页中有其他的链接也是我们十分感兴趣的,那么你可以在SPIDERS中增加相关的功能,对新的链接发起再次的爬取。
SPIDERS 生成了这两个数据类型之后,将它们发送给 ENGINE 模块,那么 ENGINE 模块收到了两类数据之后,将其中的 ITEMS 发送给 ITEM PIPELINES,将其中的 REQUESTS 发送给 SCHEDULER 进行调度,从而为后期的数据处理,以及再次启动网络爬虫请求提供了新的数据来源。
在这个路径之中,ENGINE 控制着各个模块的数据流,并且它不断地从 SCHEDULER 获得真实要爬取的请求,并且将这个请求发送给 DOWNLOADER。
整个框架的执行是从向 ENGINE 发送第一个请求开始,到获得所有链接的内容,并将内容处理后,放到 ITEM PIPELINES 为止。


(用户不需要去编写它们,它们会按照既定的功能去完成它们的任务)
-
SPIDERS 模块用来向整个框架提供要访问的url链接,同时要解析从网络上获得的页面的内容。
-
ITEM PIPELINES 模块负责对提取的信息进行后处理。
由于在这个框架下,用户编写的并不是完整的或者大片的代码,而仅仅是对 SPIDERS 和 ITEM PIPELINES 中已有的代码框架(或者叫代码的模板)进行编写,
所以,我们也将这种代码编写方式叫做配置。
相当于用户在Scrapy爬虫框架下,经过简单的配置,就可以实现这个框架的运行功能,并且最终完成用户的爬取需求。
