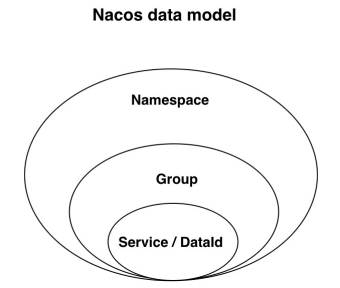
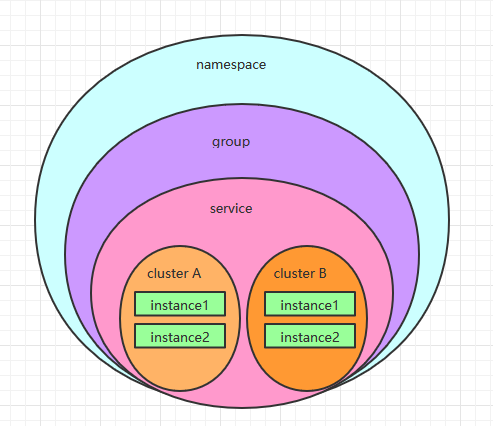
ナコスキーデータモデルを一意にトリプレットによって識別され、空の文字列に名前空間のデフォルトは、公共の名前空間(パブリック)は、パケットは、デフォルトのDEFAULT_GROUPです。
これらはナコスの公式の写真と説明オンライン顔、総合的な外観は次のようになります
することができますナコスは、対応するインターフェースコンソールを参照してください

私たちは、やってするために使用されているこれらの事を見て
名前空間は、そのような私たちのように分離株のリソースに使用することができますのdevのサービスや環境、テスト環境サービスは同じにしているナコス、上記のサービスを登録のdevの環境が呼び出していないテスト環境サービス。
我々ナコス二つの新しいコンソールの名前空間には、テストおよびdevが2つの生成IDを

当社は、サービスと在庫サービスの順序設定名前空間を通り、DEVのの1 のテスト
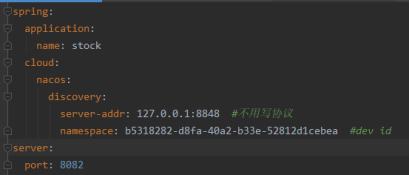

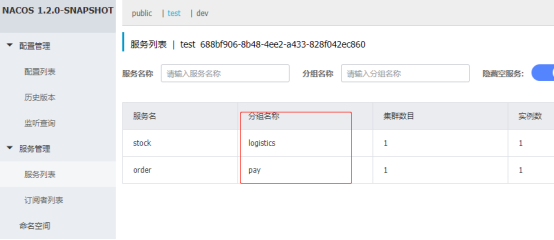
再来查看nacos控制台的服务列表会看见两个服务并不在public的命名空间下了,而是去到了test和dev下面,调用我们创建订单的接口,会发现在订单服务里面无法去扣减库存了。因为这两个服务现在已经不在同一个namespace下面了,无法进行调用了。
Group顾名思义就是分组了,比如订单和支付服务是支付组,库存物流属于物流组,不同的分组之前的服务也是不能进行调用的。将上面的服务设置成同样的namespace之后,发现服务可以调用了。但是我们有设置成不同的分组,发现服务又不能调用了。

两个扩展点:spring.cloud.nacos.discovery.cluster-name参数
cluster-name,可以设置上之后通过自己的负载均衡算法可以实现优先同集群调用,减少网络开销,比如在成都这边都有部署订单服务和库存服务,那么订单调库存的时候优先调用成都机房的库存服务(spring.cloud.nacos.discovery.cluster-name=CD)。
spring.cloud.nacos.discovery.metadata参数
元数据参数可以配置一些额外的信息,比如设置一个版本进去,通过自己的负载均衡算法实现同版本之间的服务调用。比如线上有10个订单服务和10个库存服务都是V1版本,现在改部分改动,都上了2个V2版本,通过实现我们自己的负载算法,使得V2版本的订单只能调用V2库存服务。
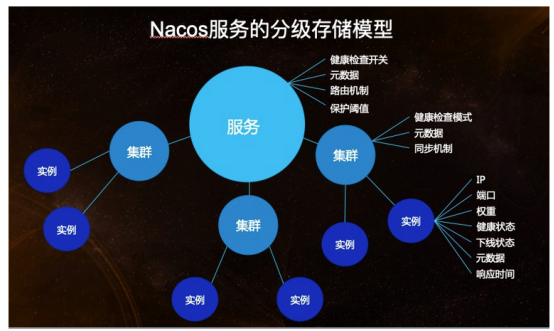
以上的数据模型详见Nacos源码:com.alibaba.nacos.naming.core.ServiceManager类
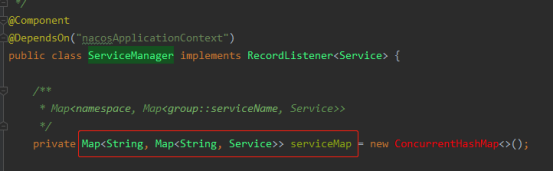
这个双层Map的key分别是namespace和group::serviceName,
com.alibaba.nacos.naming.core.Service中可以看到有一个Map<String, Cluster>,

com.alibaba.nacos.naming.core.Cluster中才是具体的服务实例com.alibaba.nacos.naming.core.Instance的Set集合,一个是持久化实例,一个非持久化实例。
