、クリックスルー率推定の問題を解決するために、この記事では、基本的なnumpyのライブラリを使用して、ゼロから始める簡単なニューラルネットワークを達成するためにはPythonを使用します(単層ニューラルネットワークがあるためか、単純なLRを、LRがあります)。ホワイトに従うように興味のある友人は、それが見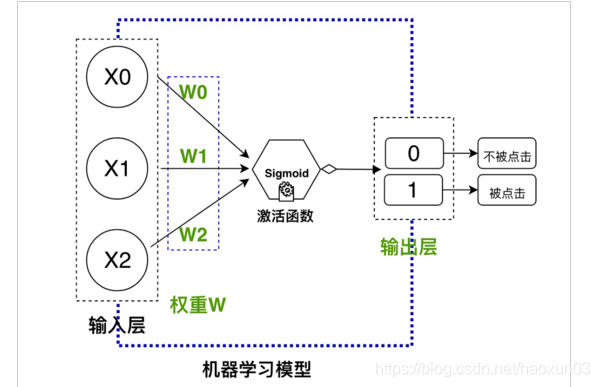
予測モデルに当たります
0.はじめに
Benpian機械学習の基本的な紹介記事で、機械学習を用いたニューラルネットワークアーキテクチャと自分自身を理解。
Pythonはすぐにビジネスの問題を解決するための機械学習モデルのさまざまなを構築するために、このようTensorFlowなどsklearn、などの高度な機械学習ツールキット、のすべての種類の毎日の使用に慣れています。
、クリックスルー率推定の問題を解決するために、この記事では、基本的なnumpyのライブラリを使用して、ゼロから始める簡単なニューラルネットワークを達成するためにはPythonを使用します(単層ニューラルネットワークがあるためか、単純なLRを、LRがあります)。
ビジネスシナリオを想定し1
免責事項:シンプルな...すべてから簡単にするために、以下の設定。
解決すべき問題を定義します。
ボス:マイクは、このマシン上のログデータのクリックをマイクロブログの数は、あなたが分析するために取る、その後、CTRの予測何に従事するがあります...
はい、それはつぶやきは、ユーザーが(クリックされる確率)をクリックしているかどうかを予測することである......未来を予測、非常に不思議な道のように見えます!
人気のマイクロブログ
ビジネスデータを深めに簡単なルック
ツイッター{ID、ツイッター前記X、Y} Twitterのクリックフラグ:各々は、マイクロブログのデータは、3つの部分から構成されています
フィーチャーXマイクロブロギングは、3つの次元を持っている:X={x0="该微博有娱乐明星”,x1="该微博有图”,x2="该微博有表情”}
マイクロブログは、Yフラグをクリックされたかどうか:
Y={y0=“点击”, y1=“未点击”}
データを、我々はモデルを設計する必要があり、列車へのデータ入力後、予測期間中に、ちょうど{特徴Xをマイクロブログ、マイクロブログのID}を入力し、各モデルの出力は、IDがクリックされたマイクロブログであろう確率
2.タスク分析:
これは、教師付き機械学習タスクであります
明らかにならない、クリッククリック、または:タスクを学ぶ教師のマシンは、単に分類と回帰の問題に分けることができるために、我々は単にここに達成したいマイクロボーは、ユーザーがクリックするかどうかを予測し、目標は、バイナリのカテゴリを予測することです分類問題として。
そこで、我々はまた、我々はトレーニングデータセットを学習指導構築する必要があると判断した分類モデルを(クリックスルー率の予測モデル)、構築する必要があります。
モデルを選択
最も単純なニューラルネットワークモデルを選択して、人工ニューラルネットワークは、このようなフィードフォワードニューラルネットワークなどのニューラルネットワークのいくつかの種類、畳み込みニューラルネットワークとリカレントニューラルネットワークを持っています。これは、一例として、フィードフォワードニューラルネットワークを知覚または単純され、人工ニューラルネットワークのこのタイプは、短い伝播プロセスの前に、前方から後方へ直接送信されたデータです。
3.データの準備:
全体のプロセス:
データの前処理(数値コード) - >機能の選択 - >セレクトモデル(フィードフォワードニューラルネットワーク) - モデル予測> - >モデルトレーニング
数値的に符号化された4マイクロブログデータに対して、それは以下の行列形式で表現することができる、と仮定:
訓練データXY
サンプルデータの解釈:
最初のサンプルデータ:X0 = [0 0 1] 、三次元の特徴に対応する、最終的な4x1の行列はYであり、0はいずれも、1は、それが、対応する機能がY0ないことが理解され、そこであることを示していない示しクリックしてください。
だから、このサンプルでは、のように変換することができます、最終のy = 0 [NOエンターテインメント星マイクロブロギングなし、写真、表現がある]、記事のマイクロブログの代表がクリックされていません。
ビジネスとデータ機能は非常に簡単ではありません...シンプルシリーズは、少し合理的に見えます。 - !
4.ニューラルネットワークの基本的な構造:
1.入力層:データ入力トラフィック特性
2.隠された層:初期化パラメータの重み
3.アクティブ機能:機能を有効にすることを選択します
前記出力層:予測されたターゲット、損失関数の定義
我々は、使用機械学習モデルしようとしている: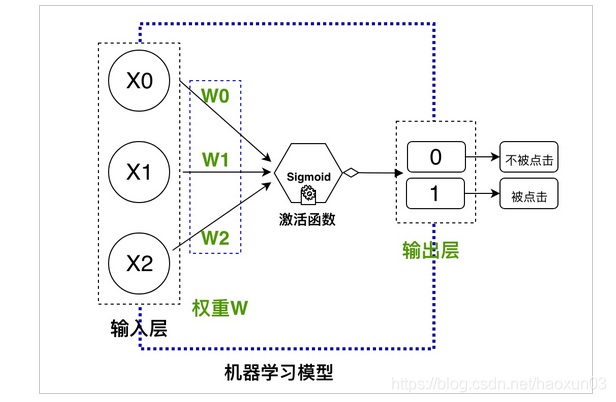
超シンプルなフィードフォワードニューラルネットワーク
ブラックボックスと同様のモデルを機械学習では、訓練のための歴史的なクリックのデータを入力し、あなたがデータの将来の量...私たちの上に設計さを予測することができ、それは、ニューラルネットワークのフィードフォワードスーパーシンプルですが、私たちの上記の目的を達成することができます。
活性化関数について:
活性化関数を導入することにより、非線形変換、モデルのフィット性を高める効果を達成します。
活性化関数の分析深学習 - 活性化機能に関連して、前の記事私の愛NLP(2)を参照してください
このチュートリアルでは、深いニューラルネットワークモデルでは、シグモイド活性化関数は、一般ためやすいその拡散勾配現象の好ましくない、という単純なシグモイド活性化関数が、ノートを使用して。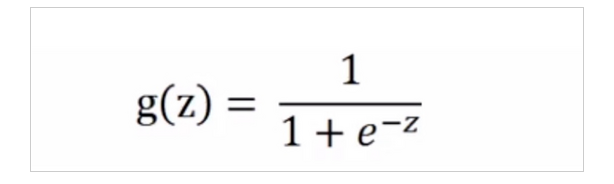
シグモイド式
此函数可以将任何值映射到0到1之间,并能帮助我们规范化输入的加权和。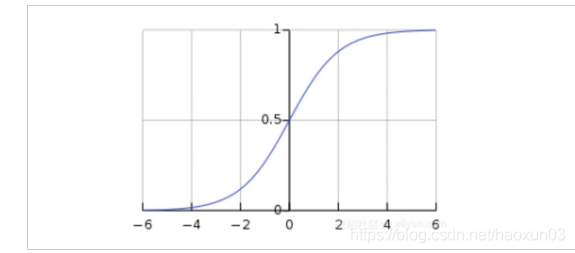
sigmoid图像
对sigmoid激活函数求偏导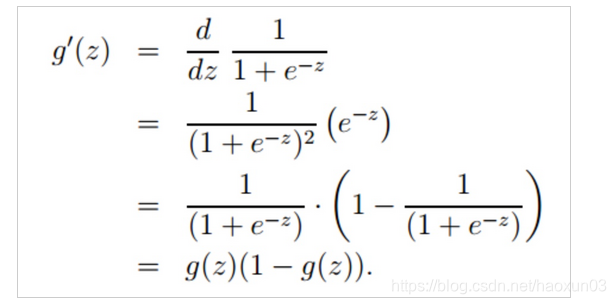 该偏导函数吗,等下写程序会用到,所以先放在这里!
该偏导函数吗,等下写程序会用到,所以先放在这里!
模型的训练
训练阶段,模型的输入X已经确定,输出层的Y确定,机器学习模型确定,唯一需要求解的就是模型中的权重W,这就是训练阶段的目标。
主要由三个核心的流程构成:
前向计算—>计算损失函数—>反向传播
本文使用的模型是最简单的前馈神经网络,起始就是一个LR而已….所以整个过程这里就不继续介绍了,因为之前已经写过一篇关于LR的文章— 逻辑回归(LR)个人学习总结篇 ,如果对其中的细节以及公式的推导有疑问,可以去LR文章里面去寻找答案。
这里再提一下权重参数W更新的公式: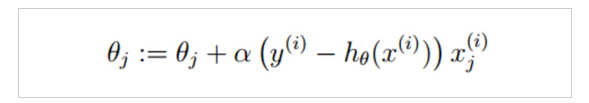
至此,所有的写代码需要的细节都已经交代结束了,剩下的就是代码了。
5.使用Python代码构建网络
# coding:utf-8
import numpy as np
class NeuralNetwork():
# 随机初始化权重
def __init__(self):
np.random.seed(1)
self.synaptic_weights = 2 * np.random.random((3, 1)) - 1
# 定义激活函数:这里使用sigmoid
def sigmoid(self, x):
return 1 / (1 + np.exp(-x))
#计算Sigmoid函数的偏导数
def sigmoid_derivative(self, x):
return x * (1 - x)
# 训练模型
def train(self, training_inputs, training_outputs,learn_rate, training_iterations):
# 迭代训练
for iteration in range(training_iterations):
#前向计算
output = self.think(training_inputs)
# 计算误差
error = training_outputs - output
# 反向传播-BP-微调权重
adjustments = np.dot(training_inputs.T, error * self.sigmoid_derivative(output))
self.synaptic_weights += learn_rate*adjustments
def think(self, inputs):
# 输入通过网络得到输出
# 转化为浮点型数据类型
inputs = inputs.astype(float)
output = self.sigmoid(np.dot(inputs, self.synaptic_weights))
return output
if __name__ == "__main__":
# 初始化前馈神经网络类
neural_network = NeuralNetwork()
print "随机初始化的权重矩阵W"
print neural_network.synaptic_weights
# 模拟训练数据X
train_data=[[0,0,1], [1,1,1], [1,0,1], [0,1,1]]
training_inputs = np.array(train_data)
# 模拟训练数据Y
training_outputs = np.array([[0,1,1,0]]).T
# 定义模型的参数:
# 参数学习率
learn_rate=0.1
# 模型迭代的次数
epoch=150000
neural_network.train(training_inputs, training_outputs, learn_rate, epoch)
print "迭代计算之后权重矩阵W: "
print neural_network.synaptic_weights
# 模拟需要预测的数据X
pre_data=[0,0,1]
# 使用训练的模型预测该微博被点击的概率
print "该微博被点击的概率:"
print neural_network.think(np.array(pre_data))
"""
终端输出的结果:
随机初始化的权重矩阵W
[[-0.16595599]
[ 0.44064899]
[-0.99977125]]
迭代计算之后权重矩阵W:
[[12.41691302]
[-0.20410552]
[-6.00463275]]
该微博被点击的概率:
[0.00246122]
[Finished in 20.2s]
"""
推荐我们的Python学习扣qun:913066266 ,看看前辈们是如何学习的!从基础的python脚本到web开发、爬虫、django、数据挖掘等【PDF,实战源码】,零基础到项目实战的资料都有整理。送给每一位python的小伙伴!每天都有大牛定时讲解Python技术,分享一些学习的方法和需要注意的小细节,点击加入我们的 python学习者聚集地
6.总结:
根据终端输出的模型训练以及预测的结果,针对预测数据pre_data=[0,0,1],模型输出该微博被点击的概率为0.00246,很显然被点击的概率比较小,可以认为简单认为该微博不会被点击!
是的,我们的业务目标初步实现了----输入任意一条微博的样本数据到我们的机器学习模型中,既可以输出该样本被点击的概率。
上記の私と一緒にクマをコンパイルした不合理な場所があるならば、我々は、超シンプルなビジネスシナリオを想定し、設計し、トレーニングデータの超簡単なランダムセットしているスーパーシンプルなモデルです!!!この例では、あなたが実際のビジネス上の問題を解決するのに役立つが、マシンを学習ニューラルネットワークの初心者の理解のためではないかもしれないが、それは今少しの助けとなるかもしれません!
