pyltpは LTPが単語、スピーチタグ付け、固有表現認識、係り受け解析、意味役割ラベリング機能を提供ラッパーのPythonです。
あなただけので、ここで、pyltpを理解し始めかもしれませんダウンロードとpyltpモデルダウンロードアドレスへpyltpモジュールは次のとおりです。
pyltpインストールダウンロード:pyltpポイントIのインストール
pyltpモデルのダウンロードを:モデルのポイントIをダウンロード
注注注(3回を言う):pyltpはそれをダウンロードし、適切に動作するモデルの対応バージョンを使用するので、ダウンロードする前に、pyltpのダウンロードしたどのバージョンを必ず覚えておいてくださいする必要があります
Python環境:python3.6の
システム:Windows10
句
pyltpは、テキストのSentenceSplitter段落は、各センテンスにこれらの言葉で、その結果、句中国語と英語の句読点のルールに従って行うことができる提供しました。聞いSentenceSplitterスプリット機能ストア文に我々はリストを取得することができ、我々はそのリストをプリントアウト。
'''
created on January 22 17:23 2019
@author:lhy
'''
from pyltp import SentenceSplitter
def sentenceSplitter(sentence='机器学习有下面几种定义: “机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。 “机器学习是对能通过经验自动改进的计算机算法的研究”。 “机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。” 一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.'):
sents=SentenceSplitter.split(sentence)#分句
print('\n'.join(sents))
sentenceSplitter()
結果:
机器学习有下面几种定义: “机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能”。
“机器学习是对能通过经验自动改进的计算机算法的研究”。
“机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。”
一种经常引用的英文定义是:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
分詞
公式によって提供されるモデルを使用すると、cws.model一つの文章に対応する単語に分割されます。
'''
created on January 22 17:34 2019
@author:lhy
'''
from pyltp import Segmentor
def segmentor(sentence=''):
segmentor=Segmentor()#初始化实例
segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型
words=segmentor.segment(sentence)#产生分词
segmentor.release()#释放模型
print('\n'.join(words))
segmentor(sentence='我今天很开心能去看电影')
結果:
我
今天
很
开心
能
去
看
电影
私たちは、文は、中国の文法に従って、中国語の単語に分割されている見ることができます。
スピーチのタグ付け
単語に基づき、当社は、各単語の品詞を知ることができます。
'''
created on January 22 17:42 2019
@author:lhy
'''
from pyltp import Segmentor
from pyltp import Postagger
#分词
def segmentor(sentence=''):
segmentor=Segmentor()#初始化实例
segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型
words=segmentor.segment(sentence)#产生分词
words_list=list(words)
segmentor.release()#释放模型
return words_list
#词性标注
def posttagger(words):
postagger=Postagger()#初始化实例
postagger.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pos.model')
postags=postagger.postag(words)#词性标注
postagger.release()
return postags
if __name__=='__main__':
words=segmentor(sentence='我今天很开心能去看电影')
postags=posttagger(words)
for word,tag in zip(words,postags):
print(word+'/'+tag)
結果:
我/r
今天/nt
很/d
开心/a
能/v
去/v
看/v
电影/n
LTPは、すべての単語で見ることができる音声タグ付けの一部でした。音声の各部分の意味は以下の表を参照することができるステージ863に採用LTP音声タグ付け:
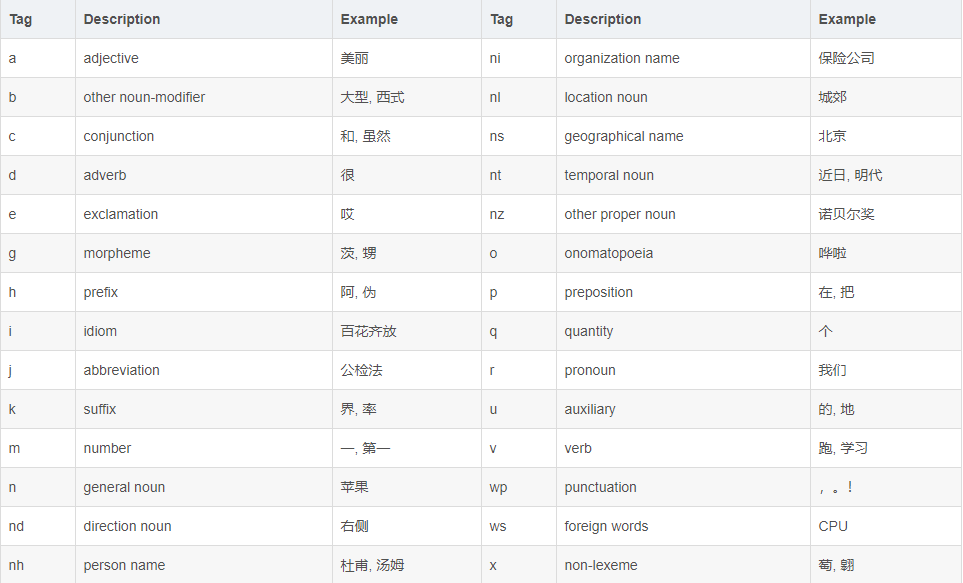
名前付きエンティティ認識
(エンティティの認識、NER名前付き)NERは見つけての文章中の単語の配列を同定することである名、地名、組織名のタスクや他のエンティティ。
NER文知る必要達成したい単語を、対応する単語POSタグ付けを。
BIESOラベリングシステムを使用してLTP。Bは、開始エンティティワードを表し、Iは、エンティティ、中間項を表し、Eがエンドエンティティワードを表し、Sは、名前付きエンティティを構成しないためにO、として別のエンティティを表します。名前付きエンティティタイプLTPがために用意されています。名前(NH)、名前(NS)、組織名(Ni)から。I、E、Sおよびダッシュエンティティタイプのラベルとラベルの位置との間のB、 -接続; Oなしタイプタグタグの後。
例:
'''
created on January 22 17:56 2019
@author:lhy
'''
from pyltp import Segmentor
from pyltp import Postagger
from pyltp import NamedEntityRecognizer
#分词
def segmentor(sentence=''):
segmentor=Segmentor()#初始化实例
segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型
words=segmentor.segment(sentence)#产生分词
words_list=list(words)
segmentor.release()#释放模型
return words_list
#词性标注
def posttagger(words):
postagger=Postagger()#初始化实例
postagger.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pos.model')
postags=postagger.postag(words)#词性标注
postagger.release()
return postags
#命名实体识别
def reco(words,postags):
recognizer=NamedEntityRecognizer()#初始化实例
recognizer.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\ner.model')
netags=recognizer.recognize(words,postags)#命名实体识别
for word ,ntag in zip(words,netags):
print(word+'/'+ntag)
recognizer.release()
return netags
if __name__=='__main__':
#因为有**词,只能通过拼音,大家在练习的时候换成汉字就行
words=segmentor(sentence='guowuyuanzonglilikeqiang调研上海外高桥时提出,支持上海积极探索新机制')
postags=posttagger(words)
reco(words,postags)
結果:
guowuyuan/S-Ni
zongli/O
likeqiang/S-Nh
调研/O
上海/B-Ns
外高桥/E-Ns
时/O
提出/O
,/O
支持/O
上海/S-Ns
积极/O
探索/O
新/O
机制/O
「Guowuyuan」はNi等のラベル組織の名前で、「李克強は、」NSとしてマークされたNH、「上海外高橋」地名としてラベル名です。Bの開始のための「上海」を「上海外高橋」、「外高橋」はE.を終了します 単一のエンティティをguowuyuan、それがSです。
依存関係の意味解析
言語のセマンティック分析成分分析部との間の依存関係の依存性は、構文構造を決定しました。依存性の解析は、セマンティック文「SVO」を識別するために使用される「ように設定」および他の文法的要素、およびこれらのコンポーネント間の関係を分析しています。
次のような関係の依存関係の解析は、14種類の表記:
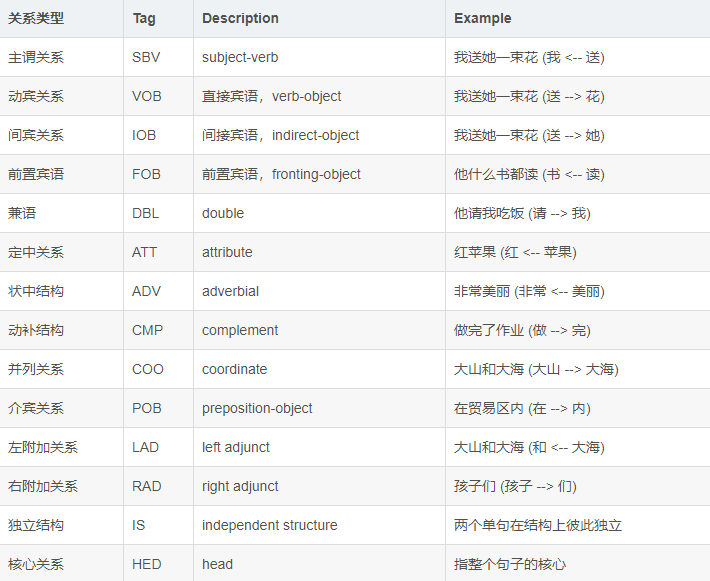
例:
'''
created on January 24 16:05 2019
@author:lhy
'''
from pyltp import Segmentor
from pyltp import Postagger
from pyltp import Parser
#分词
def segmentor(sentence=''):
segmentor=Segmentor()#初始化实例
segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型
words=segmentor.segment(sentence)#产生分词
words_list=list(words)
segmentor.release()#释放模型
return words_list
#词性标注
def posttagger(words):
postagger=Postagger()#初始化实例
postagger.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pos.model')
postags=postagger.postag(words)#词性标注
postagger.release()
return postags
#依存语义分析
def parse(words,postags):
parser=Parser()#初始化实例
parser.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\parser.model')
arcs=parser.parse(words,postags)#依存语义分析
i=0
for word,arc in zip(words,arcs):
i=i+1
print(str(i)+'/'+word+'/'+str(arc.head)+'/'+str(arc.relation))
parser.release()
return arcs
if __name__=='__main__':
words=segmentor(sentence='guowuyuanzonglilikeqiang调研上海外高桥时提出,支持上海积极探索新机制')
postags=posttagger(words)
parse(words,postags)
結果:
1/guowuyuan/2/ATT
2/zongli/3/ATT
3/likeqiang/4/SBV
4/调研/7/ATT
5/上海/6/ATT
6/外高桥/4/VOB
7/时/8/ADV
8/提出/0/HED
9/,/8/WP
10/支持/8/COO
11/上海/13/SBV
12/积极/13/ADV
13/探索/10/VOB
14/新/15/ATT
15/机制/13/VOB
コードは、arc.head親ノード依存アークのインデックスを参照すると、arc.relation依存関係アークを指します。結果では、我々は「見ることができる提案した」文全体との関係の核心である、その親インデックスは0です。他との関係については、私たちは「guowuyuan」親ノードがインデックス2「首相」で見ることができ、ATT、「guowuyuanzongli」、「上海」を構成し、それらの間の明確な関係を構成し、親ノードは、13を「探検」被験者述語関係SBVを構成し、「上海探索する。」を構成します
意味役割ラベル
意味役割ラベリング(意味役割ラベル付け、SRL)が与えられた述語元のラベル上の浅い意味解析技術、いくつかのフレーズである(意味役割)文、薬、患者、時間や場所など。どの応答システム、情報抽出、および機械翻訳アプリケーション生成の役割が可能です。
上海外高橋時に調査がguowuyuanzonglilikeqiangを上げ、積極的に上海をサポートするための新しいメカニズムを探ります。
私たちは、例えば、「探検」に文を分析し、「ポジティブ」彼の方法、一般的に表現ADV、そして「新しいメカニズム」は、一般的にA1で示される彼のShoushi、です。
A0-5 6種類の中心的な役割セマンティック、A0エージェントは通常のアクションを意味し、A1は通常、アクション、などの効果を示し、A2-5は、動詞に応じて異なる意味論的な意味を持ちます。例えばLOCのような追加の意味論的な役割として、残りの15社の意味論的役割は位置を示し、TMPは時間を表します。意味役割のリストは次のとおりです。
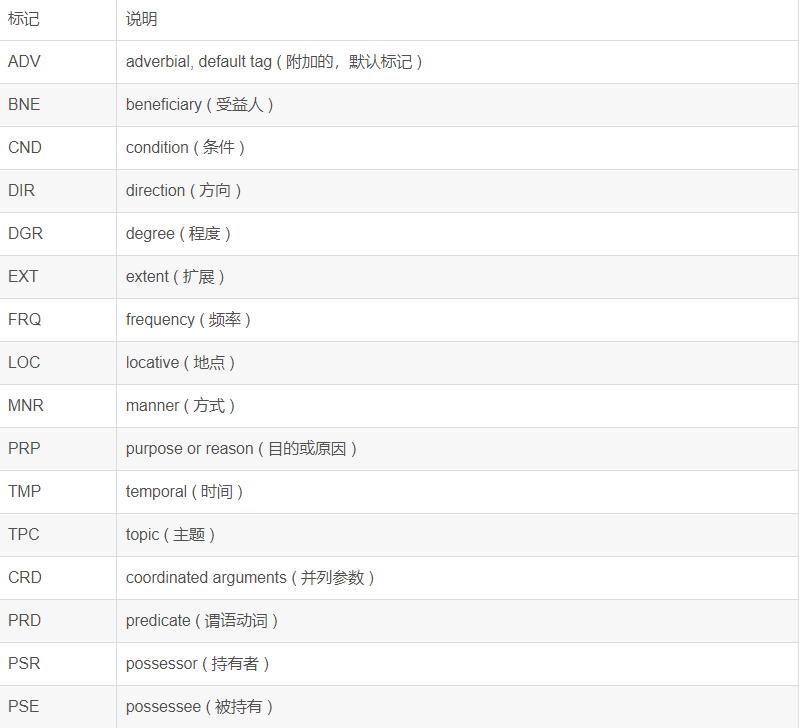
例:
'''
created on January 24 17:05 2019
@author:lhy
'''
from pyltp import Segmentor
from pyltp import Postagger
from pyltp import Parser
from pyltp import SementicRoleLabeller
#分词
def segmentor(sentence=''):
segmentor=Segmentor()#初始化实例
segmentor.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\cws.model') # 加载模型
words=segmentor.segment(sentence)#产生分词
words_list=list(words)
segmentor.release()#释放模型
return words_list
#词性标注
def posttagger(words):
postagger=Postagger()#初始化实例
postagger.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pos.model')
postags=postagger.postag(words)#词性标注
postagger.release()
return postags
#依存语义分析
def parse(words,postags):
parser=Parser()#初始化实例
parser.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\parser.model')
arcs=parser.parse(words,postags)#依存语义分析
parser.release()
return arcs
#角色标注
def role_label(words,postags,arcs):
labeller=SementicRoleLabeller()#初始化实例
labeller.load(r'D:\serve_out\auto-Q&A\ltp_data_v3.4.0\pisrl_win.model')
roles=labeller.label(words,postags,arcs)#语义角色标注
for role in roles:
print(role.index,"".join(["%s:(%d,%d)"%(arg.name,arg.range.start,arg.range.end) for arg in role.arguments]))
labeller.release()
if __name__=='__main__':
words=segmentor(sentence='guowuyuanzonglilikeqiang调研上海外高桥时提出,支持上海积极探索新机制')
postags=posttagger(words)
arcs=parse(words,postags)
role_label(words,postags,arcs)
結果:
7 TMP:(0,6)A1:(9,14)
9 A1:(10,10)
インデックスの言葉によると、インデックス7に対応する述語が「こと」、及び「提案」懸念しているため、どのような時間インデックスTMP 0-6代表ということで、見ることができ、「研究上海外高橋をguowuyuanzonglilikeqiangとき。」「それ」インパクトA1がさ9-14表さ何かのインデックス(コンテンツが提示されているもの)である「積極的に上海をサポートするための新しいメカニズムを探ります。」9インデックスがコンテンツをサポートするための「サポート」は表して「上海」。(必ずまあの「上海は積極的に新しいメカニズムを探る」であってはならない事をサポートするために、少し奇妙に感じました)
