スパークは、HBaseのを書きました
スパークでのHBaseにデータを書き込むために、我々は、使用する必要がありますPairRDDFunctions.saveAsHadoopDataset的方式。
cn.com.winパッケージ
のインポートorg.apache.hadoop.hbase.HBaseConfigurationの
インポートorg.apache.hadoop.hbase.client.Put
インポートorg.apache.hadoop.hbase.io.ImmutableBytesWritable
インポートがorg.apache.hadoop.hbase.mapred .TableOutputFormat
インポートorg.apache.hadoop.hbase.util.Bytesが
org.apache.hadoop.mapred.JobConfインポートする
インポートorg.apache.log4j.Loggerの
インポートorg.apache.sparkを{SparkConf、SparkContext}
オブジェクトTestHbase {
DEFメイン(引数:配列[文字列]){
ログVAL = Logger.getLogger( "TestHbase")
//初始化スパーク
。ヴァルCONF =新しいSparkConf()setMaster( "[2]ローカル")setAppName( "testHbase")
ヴァルSC =新しいSparkContext(CONF) //定义のHBase的配置
ヴァルhconf = HBaseConfiguration.create()
ヴァルjobConf =新しいJobConf(hconf、this.getClass)
//指定输出格式和输出的表名
jobConf.setOutputFormat(classOf [TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE、 "wifiTarget" )
ヴァルARR =配列(( "tjiloaB#3#20190520"、10、11)、( "tjiloaB#3#20190521"、12、22)、( "tjiloaB#3#20190522"、13、42))
のVal RDD = sc.parallelize(ARR)
のValのlocalData = rdd.map(変換)
localData.saveAsHadoopDataset(jobConf)
sc.stop()
} //定义函数RDD - > RDD [(ImmutableBytesWritable、PUT)]
DEF変換(三重:(文字列、INT、INT))= {
ヴァルP =新しいプット(Bytes.toBytes(triple._1))
p.addColumn(Bytes.toBytes( "wifiTargetCF")、Bytes.toBytes(」inNum」)、Bytes.toBytes(triple._2))
p.addColumn(Bytes.toBytes( "wifiTargetCF")、Bytes.toBytes( "outNum")、Bytes.toBytes(triple._3))
(新しいImmutableBytesWritable、P)
}
}
結果:
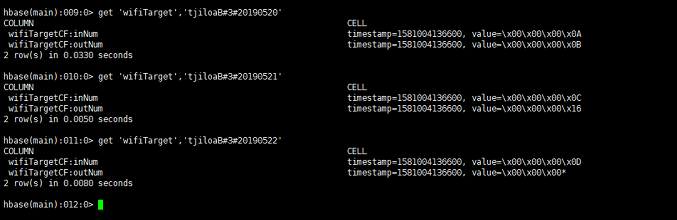
スパークは、HBaseの読み込み
スパークは、HBaseのを読んで、私たちは、主に使用しSparkContext てnewAPIHadoopRDDRDDSの形で火花にロードされたコンテンツのAPIテーブルを。
指定された列:
インポートorg.apache.hadoop.hbase.HBaseConfigurationの
インポートorg.apache.hadoop.hbase.client.Scan
インポートorg.apache.hadoop.hbase.filter.PrefixFilterの
インポートorg.apache.hadoop.hbase.mapreduce。{TableInputFormat、TableOutputFormat}
インポートorg.apache.hadoop.hbase.protobuf.ProtobufUtil
インポートorg.apache.hadoop.hbase.util。{Base64で、バイト}
インポートorg.apache.spark。{SparkConf、SparkContext}
/ **
* AUTHOR Guozy
* DATE 2020 / / 7-0 2:33
** /
オブジェクトTestHbase2 {
DEFメイン(引数:配列[文字列]):単位= {
//初始化スパーク
ヴァルCONF =新しいSparkConf()setMaster( "[2]ローカル")setAppName。 ( "testHbase")
conf.set( "spark.serializer"、「org.apache.spark.serializer。 KryoSerializer ")
ヴァルSC =新しいSparkContext(CONF)
ヴァルスキャン=新しいスキャン()
ヴァルフィルタ=新しいPrefixFilter( "tjiloaB#3#20190520" .getBytes())
scan.setFilter (フィルタ)
ヴァルhconf = HBaseConfiguration.create()
hconf.set(TableInputFormat.INPUT_TABLE、 "wifiTarget")
hconf.set(TableInputFormat.SCAN、convertScanToString(スキャン))
ヴァルdataRdd = sc.newAPIHadoopRDD(hconf、classOf [TableInputFormat]
classOf [org.apache.hadoop.hbase.io.ImmutableBytesWritable]、
classOf [org.apache.hadoop.hbase.client.Result])
バルカウント= dataRdd.count()
のprintln()+カウント"dataRddカウントは"
dataRdd。キャッシュ()
dataRdd.map(_._ 2).filter(!_。のisEmpty).take( 20).foreach {結果=>
ヴァルキー= Bytes.toString(result.getRow)
ヴァルinnum = Bytes.toInt(また、Result.getValue(Bytes.toBytes( "wifiTargetCF")、Bytes.toBytes( "inNum")))
ヴァルoutnum = Bytes.toInt(結果。 getValue(Bytes.toBytes( "wifiTargetCF")、Bytes.toBytes( "outNum")))
のprintln(S "キー:$ {キー}、inNum:$ {innum}、outNum:$ {outnum}")
}
SC。ストップ()
}
/ **
*将スキャン转换为文字列
* /
DEF convertScanToString(スキャン:スキャン):文字列= {
ヴァルプロト= ProtobufUtil.toScan(スキャン)。
Base64.encodeBytes(proto.toByteArray())。
}
結果:
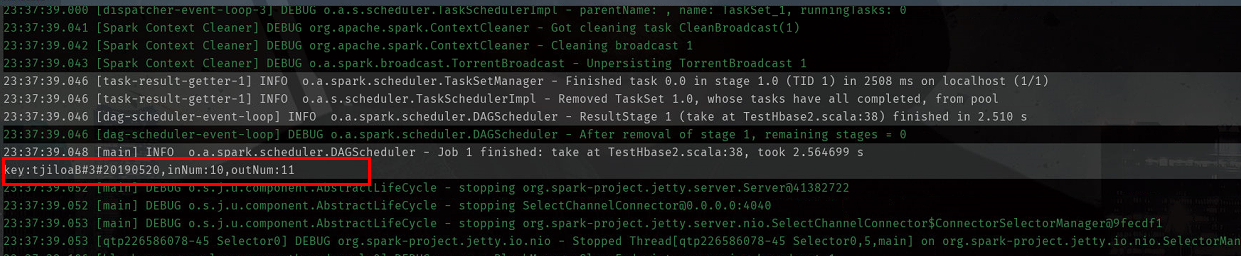
カラムを通すループ:
インポートorg.apache.hadoop.hbase.HBaseConfigurationの
インポートorg.apache.hadoop.hbase.client.Scan
インポートorg.apache.hadoop.hbase.filter.PrefixFilterの
インポートorg.apache.hadoop.hbase.mapreduce。{TableInputFormat、TableOutputFormat}
インポートorg.apache.hadoop.hbase.protobuf.ProtobufUtil
インポートorg.apache.hadoop.hbase.util。{Base64で、バイト}
インポートorg.apache.spark。{SparkConf、SparkContext}
/ **
* AUTHOR Guozy
* DATE 2020 / / 7-0 2:33
** /
オブジェクトTestHbase2 {
DEFメイン(引数:配列[文字列]):単位= {
//初始化スパーク
ヴァルCONF =新しいSparkConf()setMaster( "[2]ローカル")setAppName。 ( "testHbase")
conf.set( "spark.serializer"、「org.apache.spark.serializer。 KryoSerializer ")
ヴァルSC =新しいSparkContext(CONF)
ヴァルスキャン=新しいスキャン()
ヴァルフィルタ=新しいPrefixFilter( "tjiloaB#3#20190520" .getBytes())
scan.setFilter (フィルタ)
ヴァルhconf = HBaseConfiguration.create()
hconf.set(TableInputFormat.INPUT_TABLE、 "wifiTarget")
hconf.set(TableInputFormat.SCAN、convertScanToString(スキャン))
ヴァルdataRdd = sc.newAPIHadoopRDD(hconf、classOf [TableInputFormat]
classOf [org.apache.hadoop.hbase.io.ImmutableBytesWritable]、
classOf [org.apache.hadoop.hbase.client.Result])
バルカウント= dataRdd.count()
のprintln()+カウント"dataRddカウントは"
dataRdd。キャッシュ()
dataRdd.map(_._ 2).filter(!_。のisEmpty).take( 20).foreach {結果=>
ヴァルキー= Bytes.toString(result.getRow)
ヴァル細胞= result.listCells()。イテレータ()
一方、(cells.hasNext){
ヴァル細胞= cells.next()
ヴァルinnum = Bytes.toInt(cell.getValueArray、セル.getValueOffset、cell.getValueLength)
ヴァルoutnum = Bytes.toInt(また、result.getValue(Bytes.toBytes( "wifiTargetCF")、Bytes.toBytes( "outNum")))
のprintln(S」キー:$ {キー}、inNum。 $ {innum}、outNum:$ {outnum} ")
}
}
sc.stop()
}
/ **
*将スキャン转换为文字列
* /
DEF convertScanToString(スキャン:スキャン):文字列= {
ヴァルプロト= ProtobufUtil.toScan(スキャン)。
Base64.encodeBytes(proto.toByteArray())。
}
業績
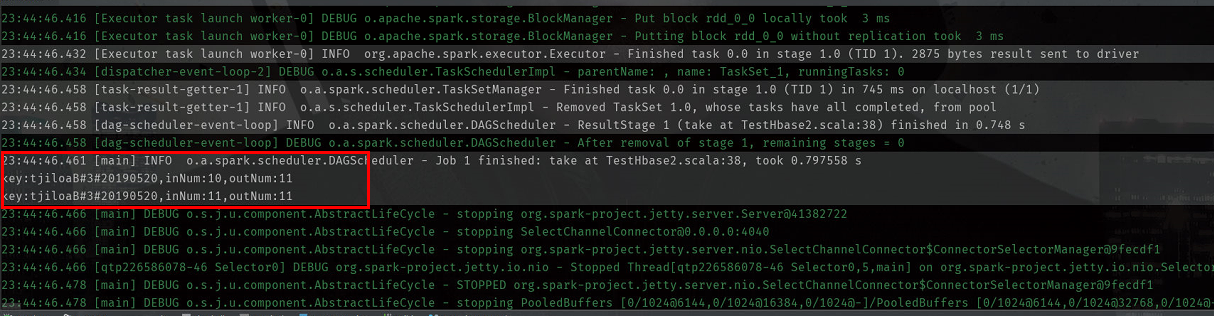
注:パッケージを導入する場合、 TableInputFormat対応するパケットがあり 、代わりにorg.apache.hadoop.hbase.mapreduce org.apache.hadoop.hbase.maped