スパークインストール
チュートリアルスパークとScalaの参照リンクをインストールするには、参照します。http://dblab.xmu.edu.cn/blog/1307-2/
環境:LinuxはすでにHadoopのインストール
スパーク公式ダウンロードします。http://spark.apache.org/downloads.html
「ユーザー提供のApache Hadoopのでプリビルド」を選択する必要性を「パッケージタイプを選択してください」の後、我々はすでに独自のHadoopのインストール、そう、それから「スパークの背面の「ダウンロード・スパーク」をクリックしますので、図の内容を参照すると、火花をダウンロード-2.4.4-ビンなし-hadoop.tgz「ダウンロード。

スパーク展開モード、4つあります:ローカルモード(シングルモード)、スタンドアロンモード(スパークを使用したが、単純なクラスタマネージャが付属しています)(クラスタマネージャとしてYARNを使用して)、糸モードとMesosモード(Mesosクラスタマネージャとして使用して) 。
ダウンロードしたコンテンツを解凍し、ユーザーのアクセス権を変更するには
sudoのタール-zxf〜/ -Cダウンロード/spark-2.1.0-bin-without-hadoop.tgzは/ usr / local /
CDは/ usr / local
にsudoのミュージックビデオは./spark-2.1.0-bin-without-hadoop/。 /スパーク
ユーザー名のため、ここでのHadoop Hadoopの./spark#:sudoのchownコマンド-RのHadoop

インストール後、あなたはまた、spark-env.shスパーク構成ファイルを変更する必要があります
CDは/ usr / local /火花
CP ./conf/spark-env.sh.template ./conf/spark-env.sh
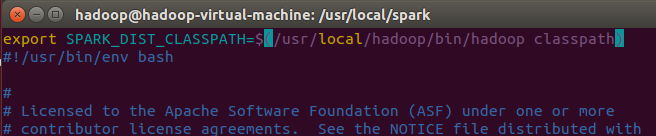
編集spark-env.shファイル(VIM ./conf/spark-env.sh)、最初の行に次の構成情報を追加します。
vimの、挿入するためにIを入力し、ESCの打ち上げエディタ,:保存するWQして終了
設定が完了した後、あなたはHadoopの起動コマンドのように実行する必要はありません直接使用することができます。
スパークを実行しています例として、スパークは、インストールが成功したかどうかを確認します。
CD は/ usr / local /火花
ビン/実行例SparkPi
ウィル出力運用多くの情報が実行され、出力は見つけることは容易ではない、あなたはgrepのコマンド(コマンド2>&1によってフィルタリングすることができそうによる出力ログの性質上、または意志の出力に、stdoutにすべての情報を持つことができます)画面:
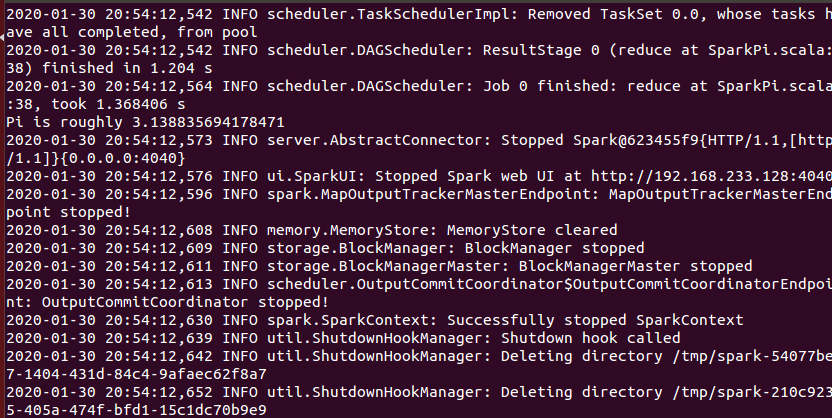
ビン/実行例SparkPi 2>&1 | grepの"Piがあります"
![]()
πの近似値を取得します。
スパークシェルの実行コード
スパーク・シェル環境にコマンドのbin /スパーク・シェルを使用してください
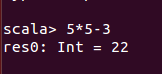
入力式が評価され
あなたがコマンドを使用することができます。exitへの「Ctrl + D」を「終了」または直接使用するキーの組み合わせ