「流暢パイソン」の研究ノート(4) - 辞書、ハッシュのコレクション
要約:Pythonの辞書データ構造は、完了word2intのint2wordように、多くの場合、建物や語彙を格納するに使用され、その高い効率および便利なインターフェイス検索NLP番組の、最も一般的にプログラミングで使用されるの一つであり、。したがって、それは辞書の構造の中に深く見ていく必要があります。
1.辞書工法:導出辞書
そして、同様の導出、導出方法辞書形式のリスト:
reduced_dict = {key: value for key, value in ...}
この方法は、例えば、特に既知のキー値の配列に、非常に有用です。
(1)は、2つのキーと値の既知のリスト1対辞書の構築を表します
keys = ['a', 'b', 'c', 'd']
values = list(range(len(keys)))
reduced_dicts = {key: value for key, value in zip(keys, values)}
(2)はどのようにint2wordを知っていますか、などNLPのword2intで知られ、デマッピングを構築する方法を、辞書の1つのマッピングに知られています
word2int = {...}
int2word = {word2int[key], key for key in word2int}
CRUDの最適化の2辞書
通常、実際のビジネスのコース、使い切るか、CRUD機能、最初のPythonの組み込みの辞書の方法のいくつかを検討した後、これらのメソッドの変換でCRUD機能の私達の必要性を利用または完全な
2.1内蔵方法辞書の三種類
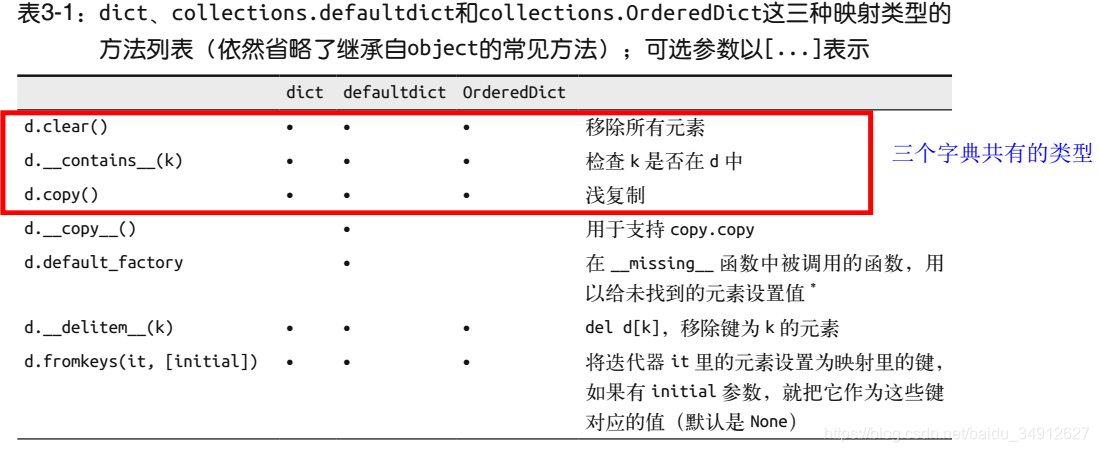

「流暢パイソン」からの抜粋
ここで一般的に用いられている方法は以下のとおりです。
- d.values()、d.keys()、より少ない2つの方法は、方法メモリリソース占有のビュー内のオブジェクトのキーと値を返します
- d.items()キーと値のペアのリターンです
- d.setdefault
2.2信頼性の高いアクセス、変更
実質的に多くの熟練したPythonプログラムがd.get(キー、DEFAULT_VALUE)でD [キー]を置き換えるために知って、より簡単に期待する使用理由文試みを削減し、効率的に問題を解決することができます。しかし、十分ではなかったこと、d.get()十分なペアを修正するに。例えば:
"""创建一个从单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
# 这其实是一种很不好的实现,这样写只是为了证明论点
occurrences = index.get(word, []) #1
occurrences.append(location) #2
index[word] = occurrences #3
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper):
print(word, index[word])
この方法では表示されません変更の主要な問題を解決することができますが、2つの問題があります。
- あまりにも長い間、機能の変更を達成するために3つのライン
- メモリアクセスは、2倍の時間の過程で変更は、3 1であります
これらの問題に対処するために、我々はいくつかの方法を持つことができます。
(1)は、SetDefault方法、改変するためのデフォルト値
"""创建从一个单词到其出现情况的映射"""
import sys
import re
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index.setdefault(word, []).append(location) ➊
# 以字母顺序打印出结果
for word in sorted(index, key=str.upper):
print(word, index[word])
这里使用的是setdefault方法来解决,当index不存在word这个键时,将index[word] = default
但这个方法就割裂了查找和删除的接口,会用到setdefault这个不常见的方法。
(2)弹性键查询方法
弹性键查询方法,是指当某个键的映射不存在的时候,我们希望通过这个键获取一个默认的值
目的是获得了一个统一的接口,如index[k].append(value)可以不出现错误的直接使用,有两种方法,一个是使用default_dict,另一个是使用__missing__方法重写
- 利用default_dict的方法是
"""创建从一个单词到其出现情况的映射"""
import sys
import re
import collections
WORD_RE = re.compile(r'\w+')
index = collections.defaultdict(list) ➊
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start()+1
location = (line_no, column_no)
index[word].append(location) ➋
# 以字母顺序打印出结果
这样就能达到要求,但值得注意的是:defaultdict的方法只会在__getitem__中调用,其他调用,在其他的方法中如d.get()中不会调用。
- __missing__方法发调用
在defaultdict中,其实当出现键值问题时,则调用__missing__方法
class StrKeyDict0(dict):
def __missing__(self, key):
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys()
这是一种继承与dict类的变种类,更好的方式是继承Userdict,这样能够写出更优美的代码。
3 哈希与效率的问题
可以看到,字典这种类型的使用方式一般是:一次建立,多次查询的;所以查询的效率需要重点考察。而为了弄清楚是字典的效率就必须了解背后的算法原理。在Python中字典的实现方法是通过Hash表的方法。
大致的工作流程如:
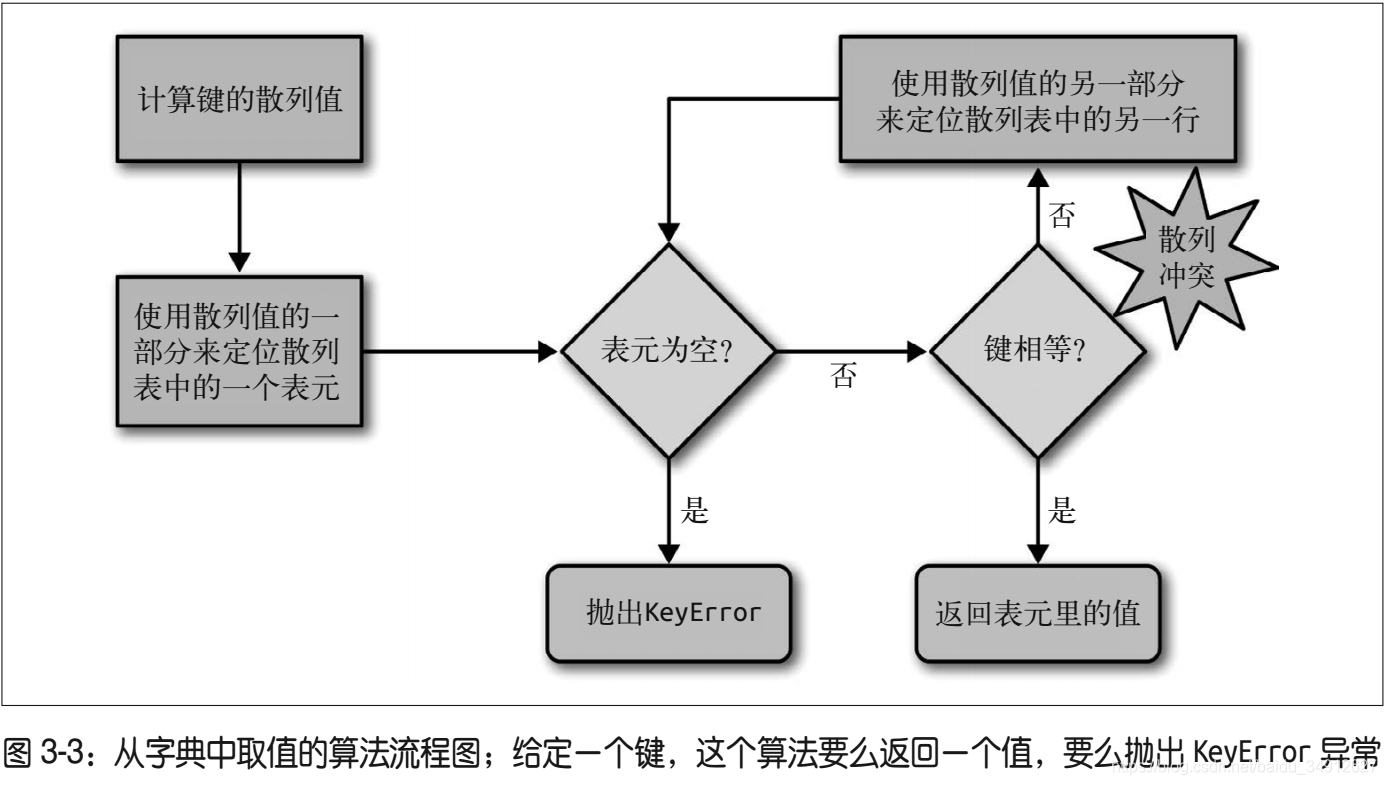
既然使用了Hash算法,则由如下几个特点:
- 键需要是能Hash的类型,基本上要是不可变类型如元组(由不可变的内容组成),字符串,
- 内存资源消耗很大,是实际需要内存的3/2
- 查询速度很快,基本上不随着数据量的增大,是O(1)级别
- 增添和删除字典,可能会导致内存的迁移
