この導入では、hadoop2.10 centos7完全に分散、機械4を最初に調製される:1局NN(名前ノード); 3セットは、(データノード)をdnは
| IP | ホスト名 | プロセス |
| 192.168.30.141 | S141 | NN(名前ノード) |
| 192.168.30.142 | S142 | DN(データノード) |
| 192.168.30.143 | S143 | DN(データノード) |
| 192.168.30.144 | S144 | DN(データノード) |
設定HDFSは、マシン、クローニング、残りのマシンの使用を設定した後、ユーザーとユーザーを追加し、ホスト名とIPを変更するように、各マシン上の各マシンの構成が統一されているので、私は、VMwareの仮想マシンを使用していますので、グループ、JDKの環境設定、インストールを参照のHadoop:centos7ダミー構造をhadoop2.10分布パターン
ここではいくつかのステップの詳細および完全な分散をインストールするには、次のとおりです。
1.各マシンのホスト名とホストを設定します
数字の最後のセットで提供されるホスト名、S + IP(例:192.168.30.141がS141である)、ファイルを変更
vimのは/ etc /ホスト名
修正ホストファイル、後部アクセスマシンのホスト名を備えたホストは、次のように変更、これはより便利であり、使用されてもよいです。
127.0。0.1 locahost 192.168。30.141 S141 192.168。30.142 S142 192.168。30.143 S143 192.168。30.144 S144
2.ないタイトな構成ログ、すなわちない密度ログSSH
ユーザーHDFSマシンS141、S141で鍵ペアを生成する必要があるとの〜/ .ssh /に他のマシンに公開鍵を送信ように、我々は、NN S141、他のマシンにはssh経由で何の接着をログに記録しないことができるようにするS141の必要性を設定しますauthorized_keysファイル
機械S141に鍵ペアの生成:
SSH-keygenは-t rsaの-P '' -fの〜/ .ssh / id_rsaと
コマンドを実行した後

ショーの成功、鍵のペアを生成するかどうかでの〜/ .sshを表示します。

S141-S144 /home/centos/.ssh/authorized_keysマシンに追加するId_rsa.pubファイルは、マシンが一時的に今は他のauthorized_keysファイルではありません他のマシンがすでにauthorized_keysに存在している場合、我々は、authorized_keysには名前を変更することができますid_rsa.pubファイルid_rsa.pubファイルの内容をファイルに追加することができた後、あなたは、リモートコピーscpコマンドを使用することができます。
SCP id_rsa.pub HDFS @ S141:/home/hdfs/.ssh/ のauthorized_keys のscp id_rsa.pub HDFS @ S142:/home/hdfs/.ssh/ のauthorized_keys のscp id_rsa.pub HDFS @ S143:/home/hdfs/.ssh/ authorized_keysに SCP id_rsa.pub HDFS @ S144:/home/hdfs/.ssh/authorized_keys
S141のマシンは猫を使用しているauthorized_keysファイルを生成することができます
猫id_rsa.pub >> authorized_keysに
この時点で、authorized_keysファイルにアクセス権が644(権限のSSH秘密ログインに失敗したため、多くの場合、問題を引き起こすことに注意してください)を変更する必要があります
chmodの644件のauthorized_keysを
構成Hadoopのプロファイル($ {HADOOP_HOME}の/ etc / Hadoopの/)
コア - sit.xml:
<?xmlのバージョン= " 1.0 "エンコード= " UTF-8 "?> <?xmlの-スタイルシートタイプ= " テキスト/ XSL "のhref = " configuration.xsl "?> <設定> <プロパティ> <名前> fs.defaultFS </名前> <値> HDFS:// S141 / </ value>の </プロパティ> </設定>
HDFS-site.xmlを:
<?xmlのバージョン= " 1.0 "エンコード= " UTF-8 "?> <?xmlの-スタイルシートタイプ= " テキスト/ XSL "のhref = " configuration.xsl "?> <設定> <プロパティ> <名前> dfs.replication </名前> <値> 3 </値> </プロパティ> </設定>
mapred-site.xmlに:
<?xmlのバージョン= " 1.0 "?> <?xmlの-スタイルシートタイプ= " テキスト/ XSL "のhref = " configuration.xsl "?> <設定> <プロパティ> <名前> mapreduce.framework.name </名前> <値>糸</値> </プロパティ> </設定>
糸-site.xmlに:
<?xmlのバージョン= " 1.0 "?> <設定> <! - サイト特有の糸構成プロパティ - > <プロパティ> <名前> yarn.resourcemanager.hostname </名前> <値> S141 </ value>の </プロパティ> <プロパティ> <名前> yarn.nodemanager.aux-サービス</名前> <値> mapreduce_shuffle </ value>の </プロパティ> </設定>
スレーブ(データノードは、指定されました)。
S142
S143
S144
hadoop-env.sh(設定JDKの環境変数):
輸出JAVA_HOME =は/ opt /ソフト/ JDK
scpコマンドを使用して他の大型機械上に分散Hadoopのコンフィギュレーションファイルでは4 S141、
SCP -r HadoopのHDFS @ S142:は/ opt /ソフト/ Hadoopのは/ etc / SCP -rのHadoop HDFS @ S143:は/ opt /ソフト/ Hadoopのは/ etc / SCP -rのHadoop HDFS @ S144:は/ opt /ソフト/ Hadoopのは/ etc /
5.フォーマットHDFS
まず、/ tmpに/ Hadoopの関連書類の下で、直接空にすることができ、削除$ {HADOOP_HOME} / logsにログファイルを削除します
フォーマットファイルシステム
Hadoopの名前ノード-format
6.スタートのHadoop
start-all.sh
スタートの成功ことを確認します7。
JPSを使用してプロセスを見ます
NN: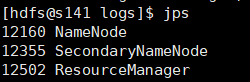
DN: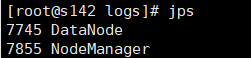
ページビュー:http://192.168.30.141:50070
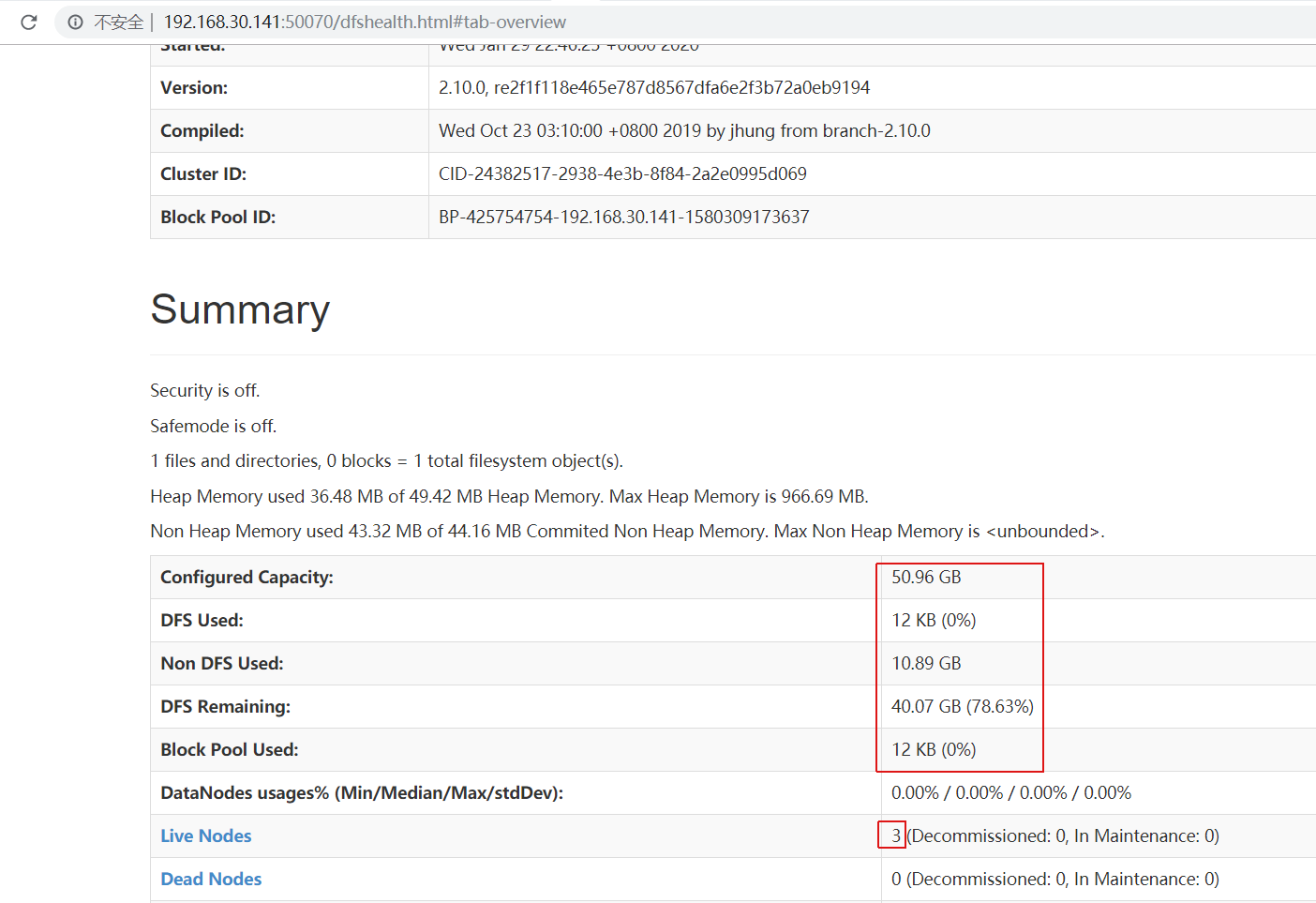
説明は正常に起動します