この部分ではclip_by_value、clip_by_norm、勾配クリッピングがあります
1.tf.clip_by_value
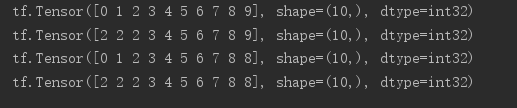
tf.range = A(10 ) 印刷(A) #IF X <a res=a,else x=x 印刷 (tf.maximum(a,2 )) x> IF #A、A = RES、他のX = X 印刷(tf.minimum(,. 8 )) 位の最大値と最小機能の二つの機能を統合し、下限は、指定された プリント(tf.clip_by_value(2,8))を
2.tf.clip_by_norm
#ランダム2行2列テンソル生成 A = tf.random.normal([2,2&]、平均= 10 ) #印刷2つのノルム、 プリント(tf.norm(A)) #新しい規範に従ってズーミングのために 印刷(tf.clip_by_norm(A、15 )) プリント(tf.norm(tf.clip_by_norm(A、15)))

3.tf.clip_by_global_norm
#グラデーションクリッピングが勾配降下及び勾配消失問題を解決するために、 #を全体ベクトルを確保することができる一方、スケーリング(及び他の倍数) のために G でGrADSの: GrADSの、_ = tf.clip_by_global_norm(GrADSの、15)
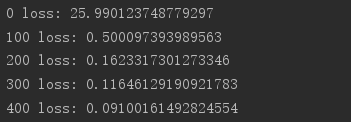
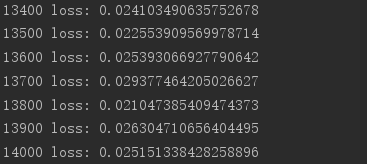
測定:
インポート TFとしてtensorflow から tensorflow インポートkeras から tensorflow.keras インポートデータセットを、層、オプティマイザは インポート のOS はos.environ [ ' TF_CPP_MIN_LOG_LEVELを' ] = ' 2 ' プリント(TF。__version__ ) (x、y)は、_ = datasets.mnist。 LOAD_DATA() X = tf.convert_to_tensor(X、DTYPE = tf.float32)/ 50 。 Y = tf.convert_to_tensor(Y) Y = tf.one_hot(Y、深さ= 10 ) 、印刷('X: 'x.shape、 ' Y:' 、y.shape) train_db = tf.data.Dataset.from_tensor_slices((X、Y))バッチ(128).REPEAT(30 ) のx、yは = 次(ITERを(train_db)) プリント(' サンプル:' 、x.shape、y.shape) #1 プリント(X [0]、Y [0]) DEF メイン(): #784 => 512 W1、B1 = tf.Variable( tf.random.truncated_normal([784、512]、STDDEV = 0.1))、tf.Variable(tf.zeros([512 ])) #512 => 256 W2、B2 = tf.Variable(tf.random.truncated_normal( [512、256]、STDDEV = 0.1))、tf.Variable(tf.zeros([256 ])) #256 => 10 W3、B3 = tf.Variable(tf.random.truncated_normal([256、10]、STDDEV = 0.1))、tf.Variable(tf.zeros([10 ])) オプティマイザ = optimizers.SGD( LR = 0.01 ) のための工程、(X、Y)に列挙(train_db): #[B、28、28] => [B、784] X = tf.reshape(X、(-1、784 )) TFとテープなど.GradientTape(): #レイヤ1。 H1 = X @ W1 + B1 、H1 = tf.nn.relu(H1) #レイヤ2 H2 = H1 @ W2 + B2 H2 = tf.nn.relu(H2) #出力 アウト= H2 @ W3 + B3 #アウト= tf.nn.relu(OUT) #計算損失 #[B]、[10] - [B]、[10] 損失= tf.square(Y- OUT) #[B、10 ] => [B] 損失= tf.reduce_mean(損失、軸= 1 ) #[B] =>スカラー 損失= tf.reduce_mean(損失) #計算勾配 卒業生= tape.gradient(損失、[W1、B1、W2 、B2、W3、B3]) #1 プリント( '==前==') #卒業生でG用: # プリント(tf.norm(G)) 卒業生、_ = tf.clip_by_global_norm(グラード、15 ) #1 プリント( '== ==後') #卒業生でG用: #1 プリント(tf.norm(G)) #1 = W「wの更新- LR *卒業生の オプティマイザ.apply_gradients(ZIP(グラード、[W1、B1、W2、B2、W3、B3])) であればステップ%100 == 0: プリント(ステップ、' 損失:' 、フロート(損失)) なら __name__ == ' __main__ " : メイン()