休日大規模なデータのためのいくつかの時間前最後の学期我々は可視化ツールの少し要約行う echarts 参照Bのいくつかのセクションを学ぶためにスタンドを。
次の休日は、学ぶことができますスパークを。
う今日スパークインストールが完了し、学生moocをその上スパーク章ビデオ学習仕上がり。分け6 節。
スパーク、概要スパーク生態系を、スパークは建築、実行されているスパークSQL 、スパーク展開とアプリケーションモード、スパークプログラミングプラクティスを。
正常にインストール火花
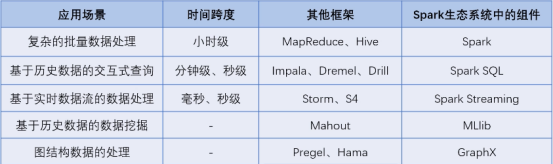
- スパークは、と比較して、大規模なデータ並列コンピューティングフレームメモリに基づいて計算されたディスク・ベースのコンピューティングHadoopの低レイテンシ、高速の利点を有するコンピューティングフレームワークを。
- スパークエコシステムは、スパークコア(設けられたインメモリコンピューティング)、スパークSQL (対話型分析を提供する)、スパークストリーミング、(フロー計算機能を提供する)MLLib (機械学習アルゴリズムは、コンポーネントライブラリを提供する)とGraphx (図コンピューティングを提供します)およびその他のコンポーネント。
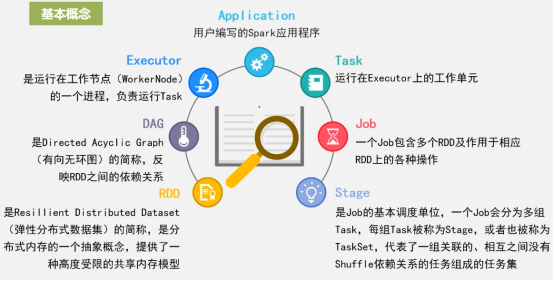
3. ファイル名を指定して実行アーキテクチャ
スパークのプロセスを実行しています:
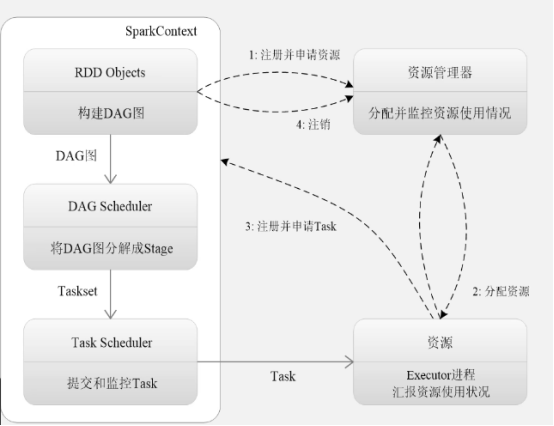
スパーク使っエグゼキュータの利点を
①起動時のオーバーヘッドの作業を減らす、特定のタスクを実行するために複数のスレッドを使用
②使用BlockManagerを低減するために記憶モジュールをIOのオーバーヘッドを
4.sparkのSQL:ハイブ互換性のレベルが唯一の依存HiveQLは、解決ハイブメタデータを。
スパーク実験の準備ができて、次の日