Word2Vecは、テキストの大規模コーパスからの大部分は、自然言語処理(NLP)で使用されているセマンティック知識のモデルを、学ぶための教師なしの方法にあります。Word2Vecモデル、主にスキップ-グラムとCBOW 2つのモデルが、この記事では詳細に二つのモデルをご紹介します。
CBOW
CBOW名単語モデル、すなわち袋連続単語モデル(グラフ線7月NLPコーステーマ)を以下に示すモデルの袋連続である
ように図から分かるように、入力CBOWコンテキストで、文脈内容により中間出力ワード、すなわち、あります中間期を予測します。
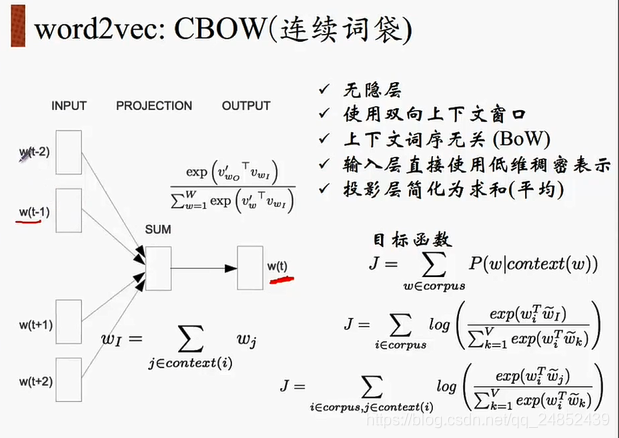
次は、私たちは、ニューラルネットワークを訓練する方法を見て。私たちは、文を持っている場合は、「犬が郵便配達人に吠えました」 。
:二つのパラメータBATCH_SIZE bag_window、BATCH_SIZE定義バッチ番号、bag_windowコンテキスト定義された長さの定義は、4我々セットBATCH_SIZE、bag_windowが1である、我々は、バッチを得ることであると仮定し[['The', 'barked'], ['dog', 'at'], ['barked', 'the'], ['at,'mailman']]、ラベルは、対応する['dog', 'barked', 'at', 'the']X、ラベルとしてバッチ構築されたネットワークは、確率分布を生成することができるようにyが供給されます。
バッチコードは、次のコードを参照して定義することができます。
data_index = 0
def cbow_batch(batch_size, bag_window):
global data_index
batch = np.ndarray(shape=(batch_size,bag_window*2), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * bag_window + 1 # [ bag_window target bag_window ]
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size):
batch[i] = list(buffer)[:bag_window] + list(buffer)[bag_window+1:]
labels[i] = buffer[bag_window]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
CBOWモデルの場合は、以下の改善点があります。


スキップ - グラム
Oスキップ-グラムとCBOW反して、スキップ・グラムは、入力、出力コンテキストとして単語の中心で、次のように、特定のモデルは次のとおりです。
次の私たちは、ニューラルネットワークを訓練する方法を見て。私たちは、文を持っている場合は、「犬が郵便配達人に吠えました」 。
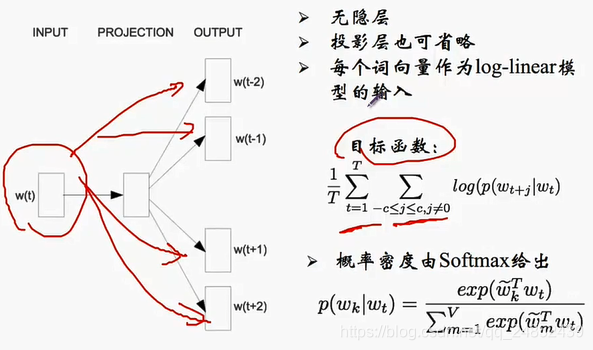
二つのパラメータ、我々は現在の入力ワード(左または右)の片側から選択した単語の数、num_skipsと呼ばれる別のパラメータを表しskip_window、というパラメータを定義し、それが別のウィンドウ全体から選択何我々表します私たちの出力ワードとして単語。場合BATCH_SIZE = 4、skip_window = 2、と仮定 num_skips = 、2バッチを得るため
['barked', 'barked', 'at', 'at']のラベル['dog', 'at', 'barked', 'the']ラベルが一括に1と、例として、中心ワード「吠え」を想定されていない、num_skips = 2、そうラベルからなぜなら「」、「犬」、 「での」、「」 リコールランダム2の4つの単語。
これらのデータ意志の出力に確率分布をニューラルネットワークの学習、確率は、各単語を、私たちの辞書を表し出力ワードの可能性があります。
バッチコードは、次のコードを参照して定義することができます。
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= 2 * skip_window
# x y
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1 # context word context
# deque是一个左右都可以增加元素的结构
buffer = collections.deque(maxlen=span)
# 滑动窗口大小,取上下文
for _ in range(span):
buffer.append(data[data_index])
# print(buffer)
# print(data_index)
# 循环使用
data_index = (data_index + 1) % len(data)
# i表示batch中中心词的个数
for i in range(batch_size // num_skips):
target = skip_window #
targets_to_avoid = [ skip_window ]
# j表示一个中心词取多少个上下文
for j in range(num_skips):
# print(target)
# print(targets_to_avoid)
# 随机从span个词中出num_skips个
while target in targets_to_avoid:
target = random.randint(0, span - 1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
return batch, labels
参考:https://blog.csdn.net/qq_24003917/article/details/80389976
