まず、いくつかのコーディングの導入
1、ユニコード、UTF-8とISO8859-1とゴミ問題
以下の説明では、「中国」という言葉になり、例えば、ルックアップテーブルによりGB2312コーディング知ることができることは、「d6d0のcec4」で、Unicodeは「4e2d 6587」としてエンコード、UTFエンコーディングは「e4b8ad e69687」です。(注)この言葉はないISO8859-1エンコーディングを行い、それにISO8859-1エンコーディングできること「を表現します。」
コーディングの2.基本知識
第1の符号化は、ISO8859-1、及びASCII同様の符号化です。しかし、表現言語のさまざまなを容易にするために、標準コードの数が徐々に出現は、次のような重要なを持っています。
2.1。ISO8859-1
コーディングシングルバイトに属し、0〜255まで表現できる文字の範囲は、英語のシリーズを適用しました。例えば、文字コードがの0x61 = 97です。
もちろん、文字範囲のISO8859-1エンコードされた表現は非常に狭く、中国語の文字を表現することはできません。それは同じの最も基本的な単位のシングルバイトコーディング、およびコンピュータ表現であるため、しかし、そう頻繁に、まだ表現するために、ISO8859-1エンコーディングを使用します。そして、多くのプロトコルでは、デフォルトのエンコーディングを使用します。例えば、「中国」という言葉は、コーディングISO8859-1存在しないが、例えばGB2312にコーディング、ISO8859-1エンコーディングを使用して、「d6d0のcec4」の2つの文字でなければならない、場合には、4つのバイトに離れ意志(蓄積時間の間に、実際には、だけでなく、バイト単位で処理された)「D6 D0 CE C4」:彼は表しています。それはUTFにある場合、それは6バイト「E4 B8広告e6の96 87」です 。明らかに、これは別のエンコーディングに基づいており、さらに表現する必要があります。
2.2。GB2312 / GBK
これは、国家標準中国語の文字を表現するために設計されたコード、ダブルバイトコーディング、および英語の文字とISO8859-1一貫した(ISO8859-1エンコーディングとの互換性)の男性です。GBKコーディングは、繁体字および簡体字を表して同時に使用することができ、唯一の簡略化2312を示す、GBKコーディング互換GB2312です。
2.3。ユニコード
これは、含まれた文字を含め、コーディングほとんどコーディング統一、すべての言語の文字を表すために使用することができますが、また、ダブルバイトの固定長(も4バイト)されます。あなたはそれがコーディングISO8859-1、また任意のコーディングとの互換性と互換性がないと言うことができるように。しかし、ISO8859-1エンコーディングに関して、ちょうど前にコーディングuniocodeは、文字として、0バイトが追加されます「0061」。
なお、固定長(注GB2312 / GBKない固定長符号化)処理するコンピュータを容易にするために、コーディング、および彼らがそうJavaなどの多くの内部使用のUnicodeソフトウェアコーディングプロセスで、すべてのUnicode文字を表すために使用されてもよいです。
2.4。UTF
アカウントコーディングUnicodeの互換性がありませんISO8859-1に取ることコーディング、およびより多くのスペースを占有するのは簡単です:英語のアルファベットは、Unicode文字も表現するために2つのバイトを必要とするため。そう簡単ではない転送とストレージをUNICODE。従ってコーディングUTF互換ISO8859-1コード、コードUTFを生成するだけでなく、すべての言語の文字を表すために使用することができるが、UTFエンコーディングは、可変長符号化、1-6の範囲の各文字のバイトの長さです。さらに、UTFは独自のシンプルなチェック機能をコーディングします。一般的に、文字がバイトで表され、3バイト文字を使用しています。
UTFは、より少ないスペースと使用を使用することであるが、すでに漢字を知っている場合のみ、コーディングユニコードに関連して、使用GB2312 / GBKは間違いなく最も貯蓄ですが、あることに注意してください。一方、UTF文字の3つのバイトを使用してエンコードされますが、ウェブサイトは英語の文字を多く含んでいるため、偶数ページの漢字のために、コーディングよりもコーディングUTFユニコードが保存されますが、ことは注目しかし、価値があります。
文字の3. Javaの取り扱い
Javaのアプリケーションソフトでは、文字セットエンコーディングに多くの関連があるだろう、いくつかの場所は、いくつかの場所では、治療の一定のレベルを必要とし、正しい設定を必要としています。
3.1。GetBytesメソッド(文字セット)
この効果は、文字列で表され、係る文字セットでエンコードされたバイト数で表現され、Java文字列の標準関数です。メモリは常にJavaの文字列はUnicodeストレージにより符号化することに注意してください。たとえば、「中国」、通常の状況下では、文字セットが、それは「d6d0のcec4」としてコード化された「GBK」の場合、「4e2d 6587」用のストレージ(つまり、何も間違って時間がない)、その後、「D6 D0 CE C4」のバイトを返します。文字セットがある場合は、「UTF8」を「E4 B8広告e6の96 87」最後のものです。それは「ISO8859-1」であれば、最終的にエンコードすることができない、とは、「3F 3F」(2つの疑問符)を返します。
3.2。新しいString(文字セット)
これは、別の標準Java文字列操作関数、及び逆に、文字セット符号化識別の組み合わせに応じて、バイト配列に作用する機能であり、最終的にユニコードストレージに変換します。上記GetBytesメソッド、「GBK」および「UTF8」することができ、正しい結果「4e2d 6587」が、ISO8859-1最終的にオン「003F 003F」(疑問符)の例を参照します。
UTF8は/エンコードにすべての文字を表すために使用することができるので、そう新しいString(str.getBytes(「UTF8」)、「UTF8」)、完全に可逆的である=== STR、。
3.3. setCharacterEncoding()
この機能は、httpリクエストやコーディング対応を設定するために使用されます。
指定されていない場合、要求のために、コードの内容を参照し、指定することができる()直接のgetParameter正しい文字列を経て得られた、ISO8859-1エンコーディングは、デフォルトでは、更なる処理を必要とします。以下の「フォーム入力」を参照してください。それはのsetCharacterEncoding()の実装前に、ことは注目に値する、任意のgetParameterでを実行することはできません()。Javaのドキュメントの指示:この方法は、従来getReader()を使用してリクエストパラメータまたは読み取り入力の読み込みに呼び出さなければなりません。また、指定されたPOSTメソッドはGETメソッドには無効に効果的です。理由の分析は、それはそうのsetCharacterEncoding()が無効である()、Javaはすべての応募作品のコーディング分析に従うだろう、とフォローアップのgetParameter()もはや分析され、getParameterでの実装にする必要があります。フォームはURLでコンテンツを提出される提出するGETメソッドの場合、最初は当然無効)(のsetCharacterEncoding、すべての応募作品の分析によれば、符号化されています。
応答のために、それは同時に出力を符号化するコンテンツを指定され、設定が使用されるエンコーディングブラウザの出力内容を伝え、ブラウザに渡されます。
リンクを参照してくださいhttps://jingyan.baidu.com/article/020278118741e91bcd9ce566.html
第二に、中国は、原因とシミュレーションを文字化け
1、文字化けシーン
バックグラウンドで文字化け、中国のフォアグラウンド受け取りました。
参照してくださいブログ投稿します。https://www.cnblogs.com/vole/p/12030764.html
2、理由
サーバは(中国の歪みが生じる)文字にデコードされたISO-8859-1エンコーディングストリームにバイトストリームのデフォルトを受信後、HTTPリクエストのURLは、エンコードされたISO-8859-1を送信します。
漢字ので、別の符号化方式がUTF-8に記憶されているHTTPを介して送信する際、サーバはワードを受信し、ISO-8859-1符号化バイトに向ける(メモリの最小単位であるバイト) ISO-8859-1のデフォルトのエンコード形式に絞っが文字ストリームにデコードされ、それが文字化けします。
一例として、中国の「ハロー」で:
コードは以下の通りであります:
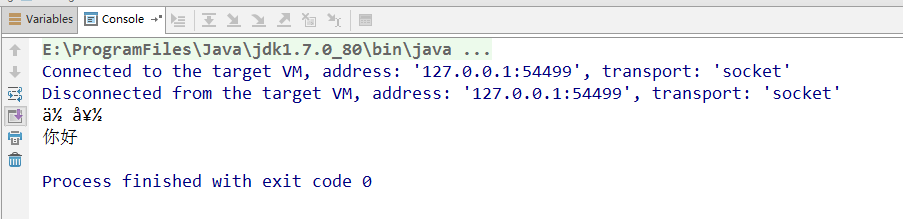
パッケージcom.asd.reserve.utils.coding; 輸入java.io.UnsupportedEncodingException。 / ** * @author ZS * @date 2020年1月10日夜04時56分 * / パブリック クラス符号化法{ 公共 静的 ボイドメイン(文字列[]引数)スローにUnsupportedEncodingException { / * "你好" =文字列strと、 バイト[] BS = str.getBytes( "ISO-8859-1")。 {(BSバイトb)のために System.out.println(B)。 } System.out.println(新しい文字列(BS、 "ISO-8859-1")); System.out.println(新しい文字列(BS、 "UTF-8")); System.out.println(新しいString(BS、 "GBK")); System.out.println(新しいString(BS、 "ユニコード")); * / / * 文字列str = "こんにちは"; //中国:こんにちは、メモリがUnicodeのjavaに格納します バイト[] UT = str.getBytes( "UTF-8"); // GETバイトUTF-8エンコーディング形式 System.out.println(新しいString(UT、 "ISO-8859-1")); System.out.println(新しいString(UT、 "UTF-8")); System.out.println(新しいString(UT、 "GBK")); System.out.println(新しいString(UT、 "ユニコード")); * / バイト [] UT1 = {-28、-67、-96、-27、-91、-67}; // UTF-8は、中国語に格納されたエンコーディングでアナログ受信:こんにちは 文字列= chuanshu 新しい新しい文字列(UT1、 " ISO-8859-1「); // なりHTTP&UT1転送符号化(ISO-8859-1の符号化) // へストリーミングISO-8859-1バイトフォーマットバック バイト []バイト= chuanshu .getBytes( "ISO-8859-1" ); System.out.println(新しい新しい文字列( "ISO-8859-1"、バイト)); // デフォルトの後端が中国をデコードするためにISO-8859-1を受け入れる:こんにちは(文字化け) のSystem.out.println(新しい新しい文字列(バイト、 "UTF-8")); // 後端が中国を復号化するために、UTF-8を受け入れる:こんにちは } }
出力: