スペクトルクラスタリングは、従来のクラスタリング手法と比較して、理論的な基礎スペクトルに基づくクラスタリング手法です。
サンプル空間内の任意の形状を有し、全体最適解に収束する利点をクラスタリング。
サンプルデータのラプラシアン行列の固有ベクトルサンプルデータをクラスタリングの目的を達成するように、クラスタリング。
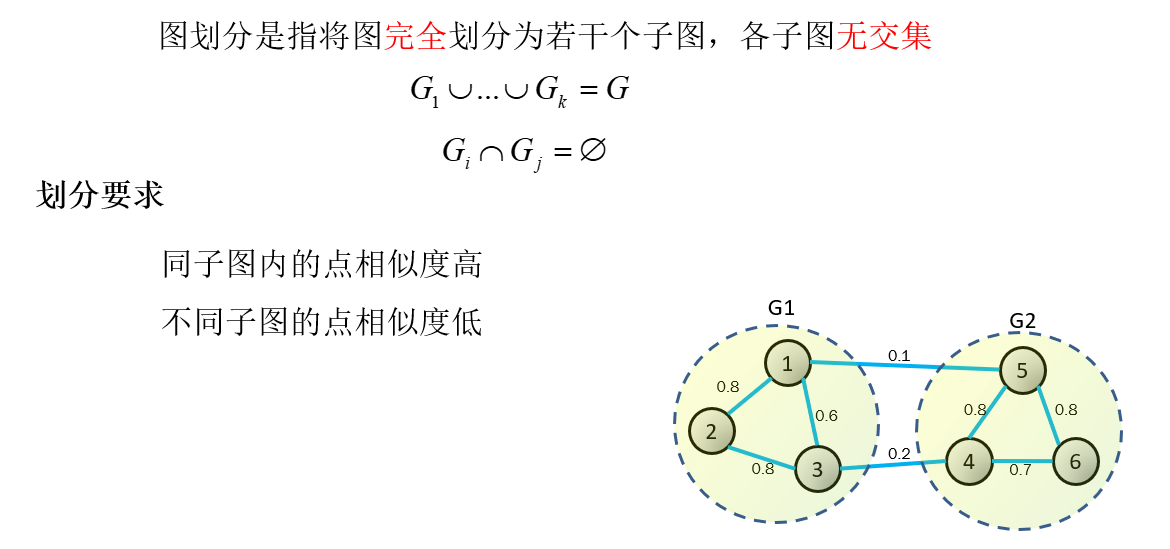
その本質は、最適な分割問題のためのグラフのクラスタリングの問題があるに変換することであるクラスタリングアルゴリズムのポイント。
類似性に基づいて1 -これは構成、wはデータの各オブジェクトは、対応する接続側頂点重みに図頂点V、量子化された頂点Eとの間の類似性に見られるスペクトルクラスタリングを設定する非加重を図G(V、Eは)、次いで、クラスタリング問題は、境界図に変換されます。
最適な分割ルールマップは、最小、最大類似度、サブグラフ内のサブグラフ間の類似性。ここで、Vは、全てのサンプルの集合、Eのコレクションの重表現を表します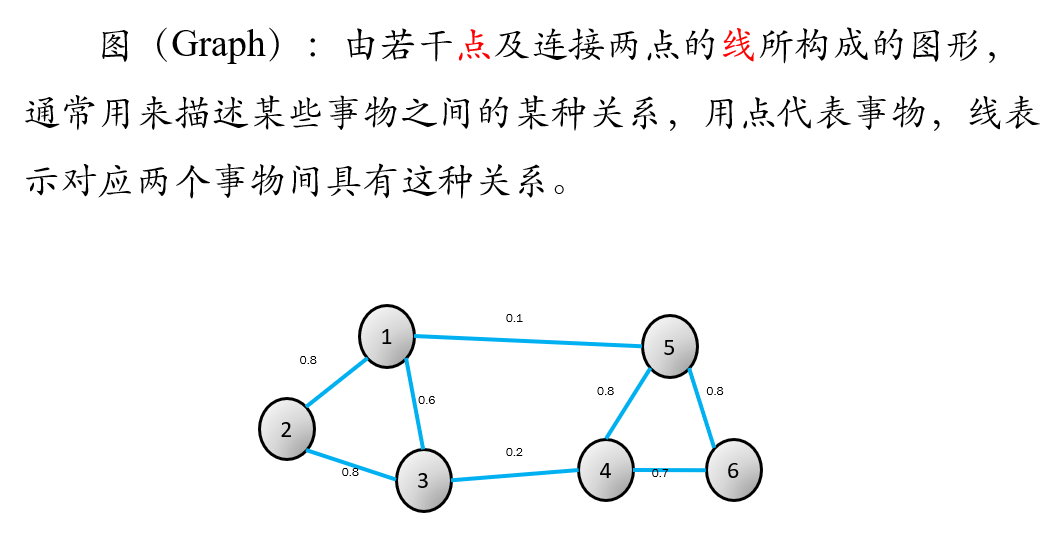
この図では内部、すなわちサンプルは、重量を定量化するために、それらの間の類似性、123456であります

損失関数は1と4重量の間であり、5,3




真実は、そのようなAの混乱を言うと、私は無知、大きな栗を与えます!
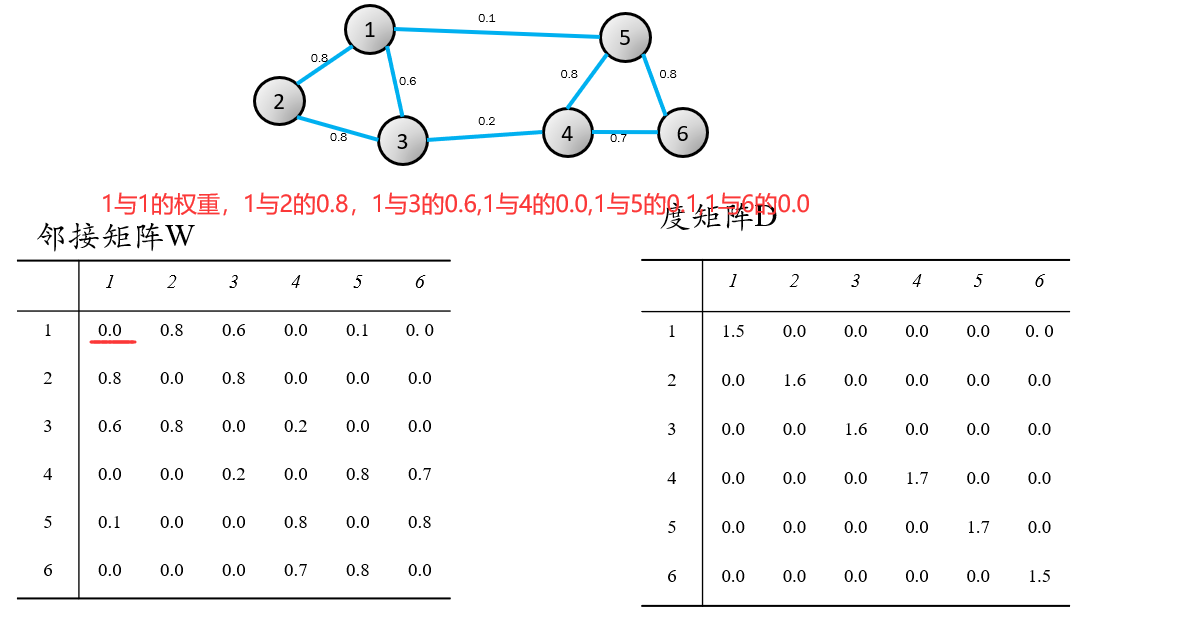
マトリックスおよび位置に対応する隣接行列の各行の(数行)に配置されます。
L = DW。
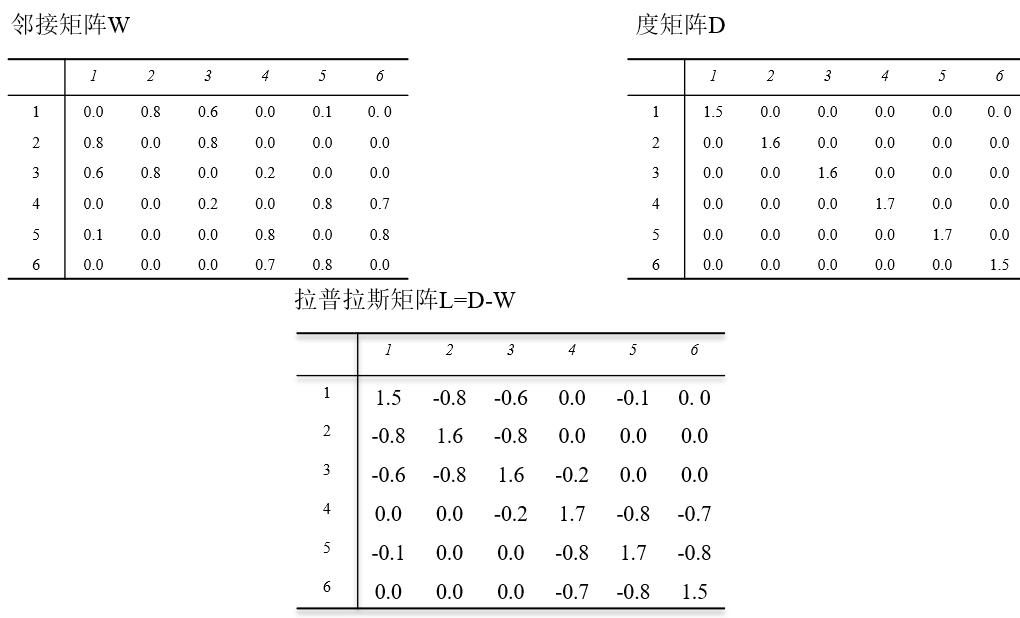




LX =λX、Lは、関連度を表す、ラプラシアン行列です。λは特性値である、第3のステップは、特徴値、昇順に特徴値(値ため、より小さいフィーチャを、関連のより小さな程度、より簡単に別のカテゴリに、容易にクラスタリング)、などの特徴ベクトルを算出します新機能の属性を使用すると、古典的なハが表示されます何を教えてください、醜いポイントを描く,,データセットを記述する

