ブリーフ
そのような文のペア、BERT、ロベルタGET創太としてテキストの意味的類似性タスクのリターンで。
しかし、それは必要と2つの文は、莫大な費用で、その結果、ネットワークに入力されています10000から文章の最も類似文ペアセットを見つける(約65時間)を計算する約5000万推論が必要です。
BERTは、セマンティック類似検索、クラスタリングなど教師なしタスクに適していないためには適していません。
クラスタリングおよびセマンティック検索に一般的な解決策は、各文章は文章が意味的に類似近くなるように、ベクトル空間にマッピングされます。
だから、何人かの人々は、get sentene埋め込み固定サイズの、BERT単一の文を入力してみてください。最も一般的な方法は、平均BERT出力層又は出力される最初のトークン(トークン[CLS])を使用することです。しかし、それは多くの場合、グローブ埋め込みを平均ないよう、非常に悪い文章埋め込みを持っていました。
本稿で:センテンスBERT(SBERT)、事前訓練BERT修正する:使用シャム三(トリプレットがあろう)embedding->コサイン類似度を用いて、文の埋め込みの固定長を生成することができる意味論的に意味のある文にインフラストラクチャネットワークを文を意味的類似度又はManhatten /ユークリッド距離を見つけるために比較。
SBERTは上記BERT /ロベルタ65時間、5Sを低減するために、同じ時間の精度を保証します。(計算されたコサイン類似度は、おそらく0.01秒)
セマンティック類似検索に加えて、クラスタリングはまた、検索に使用すること。
20分未満の時間でNLIデータで微調整SBERTで。
Sbert
プーリング戦略:
MEAN戦略:CLS-トークンを使用して、いずれかのすべての出力ベクトルの平均値。
MAX戦略:出力CLS-トークン使用は、最大オーバー時間は、すべての出力ベクトルに対して計算されます。
目的関数:
カテゴリー:
要素毎の差演算文embeedings uとvと重量:
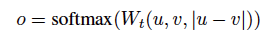
前記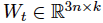 文は緯度を埋め込むこと、N、kはラベルの数です。
文は緯度を埋め込むこと、N、kはラベルの数です。
ロス:クロスエントロピー
図1:
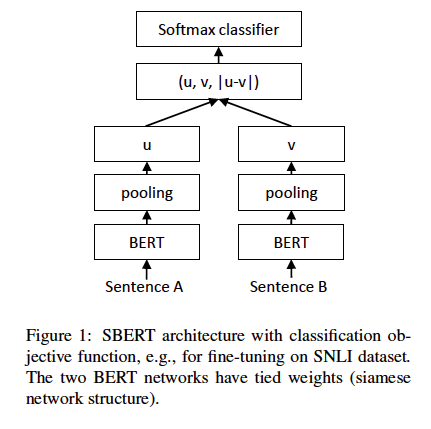
戻り値:
コサイン類似度の2文の埋め込み(U&V)を計算します。
ロス:平均二乗誤差
図2:
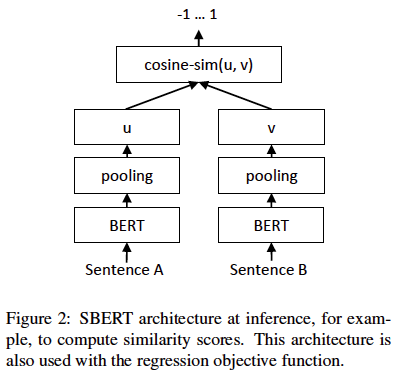
トリプレット:
输入:アンカー文A、正の文章P、否定文nを
目標は、とPとの間の距離の損失であり、nとの間の距離よりも小さくなっています。

サSpのSnが、文の埋め込みのAPNです。||・||εは余裕で、距離の尺度です。距離測定のために、ユークリッド距離を使用することができます。とき実験、1に設定されているε著者。
実験は、著者は、3ウェイソフトマックス目的関数の微調整SBERTエポックで分類する場合。戦略MEANをプールします。
次のステップは、良好な結果と結論付け、実験結果テーブルのシリーズです。
アブレーション学習:
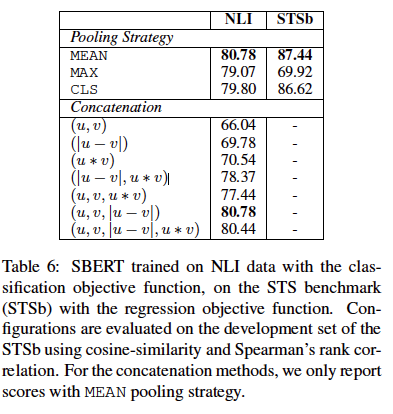
プーリング戦略は、小さな、大きなインパクト接続です。