1.クラスタノードと配信サービス
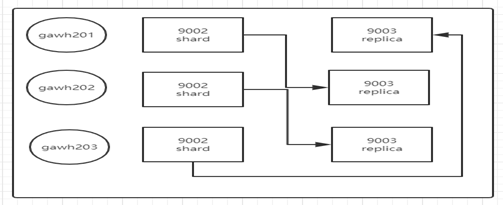
説明:
1.1、ダウンタイムデータの整合性とデータ・パーティションとデータのバックアップが同じノードでないことを保証するために、サービス(後意志詳細この手順を実行する方法)、データの断片化、データのバックアップclickhouse各ノード2日スタートgawh201でgawh201バックアップではないレプリカ上の例のシャードのために、そしてあなたがしなければgawh201がダウンした場合、データのノード破片が見つかりません。
シャードとレプリカに基づいて1.2はそう互い違いに配置しなければならないが、それをずらすために自由ではありません。オフセットの法則に従って図(大断片クラスタノードとレプリカの分布に後述します)。
1.3。にかかわらず、どのような状況の、例えば、上記のように3がその上にデータを見つけるシャードとダウンタイムがある限り、データの整合性を行うことができますどのように。
3つの断片データは依然として見つけることができるの下仮定するgawh202は、ダウンしている(gawh202のデータ断片レプリカgawh203から求めることができます)
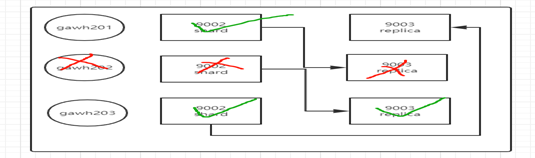
仮定gawh203がダウンしている、次のデータがまだ(gawh203シャードデータレプリカgawh201から求めることができる)は、3つの図の断片を見つけることができ
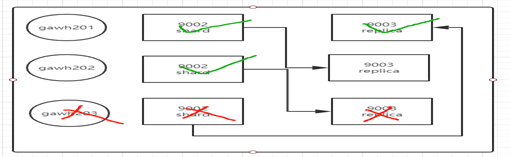
注意:
。なぜgawh201がここにダウンしていると言うではありませんか?分散クラスタテーブルが存在することになるので、テーブル自体は、分散データ、各スライス重合にのみデータに格納されていません。すべて、(分散表上のマスタノードダウンバックの問題はプログラムを与える)、マスタノードのような表を作成するために、作成し、プライマリノードがダウンした場合、あなたは、分散クエリにテーブルを使用することはできません必要に配布された後クラスタセットアップgawh201ないダウンタイム。
同時にすべてのノードダウンB。図の例では、許可されgawh202、gawh203全ては以下ダウンする場合は、3つだけデータは、2つの検索シャード
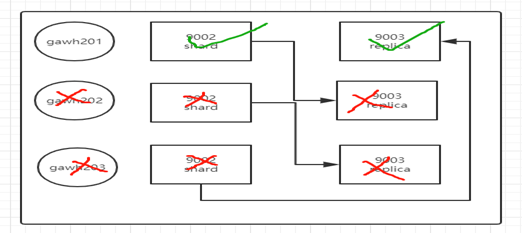
あなたはデータを1時間を確保するために、クラスタ内の2つのノード3ノードクラスタをしたい場合は、唯一のgawh201でclickhouseサービス拡張ではなく、3つのノードnode clickhouseサービスに、お勧めできませんリソースの消費量が性能に影響を与える向上します
いずれの場合も、上記の既存のデータに影響を及ぼさないで、C。、唯一のデータ挿入、クエリ有力ビーイングが実行します
2.高可用性クラスタの設定と検証
2.1. 先确保单节点和集群节点搭建没有问题,可以参考之前的文档
2.2. 在gawh201上增加一个clickhouse服务
a. 将/etc/clickhouse-server/config.xml文件拷贝一份改名
$: cp /etc/clickhouse-server/config.xml /etc/clickhouse-server/config1.xmlb. 编辑/etc/clickhouse-server/config1.xml更改以下标签内容将两个服务区分开
$:vim /etc/clickhouse-server/config1.xml<log>/var/log/clickhouse-server/clickhouse-server1.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server1.err.log</errorlog>
<http_port>8124</http_port>
<tcp_port>9003</tcp_port>
<interserver_http_port>9010</interserver_http_port>
<path>/apps/clickhouse/data/clickhouse1</path>
<tmp_path>/var/lib/clickhouse1/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse1/user_files/</user_files_path>
原有的clickhouse服务的配置应该是这样的:
<log>/var/log/clickhouse-server/clickhouse-server.log</log>
<errorlog>/var/log/clickhouse-server/clickhouse-server.err.log</errorlog>
<http_port>8123</http_port>
<tcp_port>9003</tcp_port>
<interserver_http_port>9009</interserver_http_port>
<path>/apps/clickhouse/data/clickhouse</path>
<tmp_path>/var/lib/clickhouse/tmp/</tmp_path>
<user_files_path>/var/lib/clickhouse/user_files/</user_files_path>c. 创建对应的目录
d. 将之前默认的集群配置文件metrika.xml更改为自定义,config.xml和config1.xml都需要放开
$:vim /etc/clickhouse-server/config.xml<include_from>/etc/clickhouse-server/metrika.xml</include_from>$:vim /etc/clickhouse-server/config1.xml<include_from>/etc/clickhouse-server/metrika1.xml</include_from>e. 增加实例对应的服务的启动脚本
$:cp /etc/init.d/clickhouse-server /etc/init.d/clickhouse-server1在原有基础上修改以下项
$vim /etc/init.d/clickhouse-server1CLICKHOUSE_CONFIG=$CLICKHOUSE_CONFDIR/config1.xml
CLICKHOUSE_PIDFILE="$CLICKHOUSE_PIDDIR/$PROGRAM-1.pid"原有的clickhouse-server为
$vim /etc/init.d/clickhouse-serverCLICKHOUSE_CONFIG=$CLICKHOUSE_CONFDIR/config.xml
CLICKHOUSE_PIDFILE="$CLICKHOUSE_PIDDIR/$PROGRAM.pid"f. 将先前部署集群的/etc/metrika.xml文件复制到对应的config的include_from标签配置的路径中,两个实例都要做该操作
$:cp /etc/metrika.xml /etc/clickhouse-server/
$:cp /etc/metrika.xml /etc/clickhouse-server/metrika1.xml2.3. gawh201完成上述操作配置后,gawh202,gawh203节点上和gawh201的以上操作完全一样,对三个节点每个节点两个clickhouse的服务实例对metrika*.xml文件逐个修改
a. 六个metrika*.xml共同部分:
<yandex>
<clickhouse_remote_servers>
<!-- <perftest_3shards_2replicas> -->
<cluster>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>gawh201</host>
<port>9002</port>
</replica>
<replica>
<host>gawh202</host>
<port>9003</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>gawh202</host>
<port>9002</port>
</replica>
<replica>
<host>gawh203</host>
<port>9003</port>
</replica>
</shard>
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>gawh203</host>
<port>9002</port>
</replica>
<replica>
<host>gawh201</host>
<port>9003</port>
</replica>
</shard>
<!-- </perftest_3shards_2replicas> -->
</cluster>
</clickhouse_remote_servers>
<!--zookeeper相关配置-->
<zookeeper-servers>
<node index="1">
<host>gawh201</host>
<port>2182</port>
</node>
<node index="2">
<host>gawh202</host>
<port>2182</port>
</node>
<node index="3">
<host>gawh203</host>
<port>2182</port>
</node>
</zookeeper-servers>
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>
<networks>
<ip>::/0</ip>
</networks>
<clickhouse_compression>
<case>
<min_part_size>10000000000</min_part_size>
<min_part_size_ratio>0.01</min_part_size_ratio>
<method>lz4</method>
</case>
</clickhouse_compression>
</yandex>b. 不同部分如下,对这部分做详细修改
gawh201实例1(config.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-1</replica>
</macros>其中layer是双级分片设置,这里是01;然后是shard表示分片编号;最后是replica是副本标识,这里使用了cluster{layer}-{shard}-{replica}的表示方式,比如cluster01-02-1表示cluster01集群的02分片下的1号副本,这样既非常直观的表示又唯一确定副本
gawh201实例2(config1.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-2</replica>
</macros>gawh202实例1(config.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-1</replica>
</macros>gawh202实例2(config2.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>01</shard>
<replica>cluster01-01-2</replica>
</macros>gawh203实例1(config.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>03</shard>
<replica>cluster01-03-1</replica>
</macros>gawh203实例2(config1.xml对应的)
<macros>
<!-- <replica>gawh201</replica> -->
<layer>01</layer>
<shard>02</shard>
<replica>cluster01-02-2</replica>
</macros>说明:这其中的规律显而易见,这里不再说明
2.4.启动高可用clickhouse集群
在三个节点上都执行如下脚本:
$: /etc/init.d/clickhouse-server start
$: /etc/init.d/clickhouse-server1 start启动无误后客户端进入每个服务进行验证:
gawh201上:
$:clickhouse-client --host gawh201 --port 9002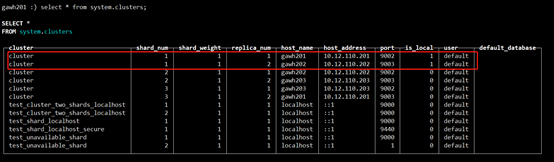
$: clickhouse-client --host gawh201 --port 9003
gawh202上:
$:clickhouse-client --host gawh202 --port 9002
$:clickhouse-client --host gawh202 --port 9003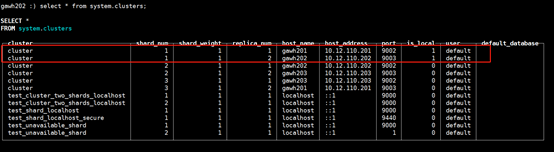
gawh203上:
$:clickhouse-client --host gawh203 --port 9002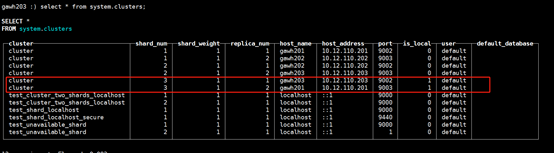
$:clickhouse-client --host gawh203 --port 9003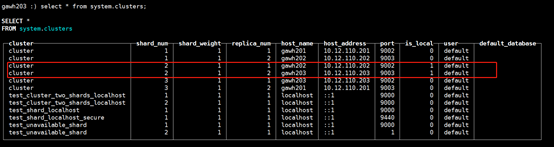
说明:仔细对比发现和之前的设计规划是完全吻合的,证明高可用clickhouse集群是部署成功的
3.现有数据查询节点宕机一致性方案验证
3.1.高可用原理
zookeeper+ReplicatedMergeTree(复制表)+Distributed(分布式表)
3.2.首先创建ReplicatedMergeTree引擎表,以实例航班数据为例
a. 需要在三个节点六个实例中都创建,创建sql如下:
CREATE TABLE `ontime`( `Year` UInt16, `Quarter` UInt8, `Month` UInt8, `DayofMonth` UInt8, `DayOfWeek` UInt8, `FlightDate` Date, `UniqueCarrier` FixedString(7), `AirlineID` Int32, `Carrier` FixedString(2), `TailNum` String, `FlightNum` String, `OriginAirportID` Int32, `OriginAirportSeqID` Int32, `OriginCityMarketID` Int32, `Origin` FixedString(5), `OriginCityName` String, `OriginState` FixedString(2), `OriginStateFips` String, `OriginStateName` String, `OriginWac` Int32, `DestAirportID` Int32, `DestAirportSeqID` Int32, `DestCityMarketID` Int32, `Dest` FixedString(5), `DestCityName` String, `DestState` FixedString(2), `DestStateFips` String, `DestStateName` String, `DestWac` Int32, `CRSDepTime` Int32, `DepTime` Int32, `DepDelay` Int32, `DepDelayMinutes` Int32, `DepDel15` Int32, `DepartureDelayGroups` String, `DepTimeBlk` String, `TaxiOut` Int32, `WheelsOff` Int32, `WheelsOn` Int32, `TaxiIn` Int32, `CRSArrTime` Int32, `ArrTime` Int32, `ArrDelay` Int32, `ArrDelayMinutes` Int32, `ArrDel15` Int32, `ArrivalDelayGroups` Int32, `ArrTimeBlk` String, `Cancelled` UInt8, `CancellationCode` FixedString(1), `Diverted` UInt8, `CRSElapsedTime` Int32, `ActualElapsedTime` Int32, `AirTime` Int32, `Flights` Int32, `Distance` Int32, `DistanceGroup` UInt8, `CarrierDelay` Int32, `WeatherDelay` Int32, `NASDelay` Int32, `SecurityDelay` Int32, `LateAircraftDelay` Int32, `FirstDepTime` String, `TotalAddGTime` String, `LongestAddGTime` String, `DivAirportLandings` String, `DivReachedDest` String, `DivActualElapsedTime` String, `DivArrDelay` String, `DivDistance` String, `Div1Airport` String, `Div1AirportID` Int32, `Div1AirportSeqID` Int32, `Div1WheelsOn` String, `Div1TotalGTime` String, `Div1LongestGTime` String, `Div1WheelsOff` String, `Div1TailNum` String, `Div2Airport` String, `Div2AirportID` Int32, `Div2AirportSeqID` Int32, `Div2WheelsOn` String, `Div2TotalGTime` String, `Div2LongestGTime` String, `Div2WheelsOff` String, `Div2TailNum` String, `Div3Airport` String, `Div3AirportID` Int32, `Div3AirportSeqID` Int32, `Div3WheelsOn` String, `Div3TotalGTime` String, `Div3LongestGTime` String, `Div3WheelsOff` String, `Div3TailNum` String, `Div4Airport` String, `Div4AirportID` Int32, `Div4AirportSeqID` Int32, `Div4WheelsOn` String, `Div4TotalGTime` String, `Div4LongestGTime` String, `Div4WheelsOff` String, `Div4TailNum` String, `Div5Airport` String, `Div5AirportID` Int32, `Div5AirportSeqID` Int32, `Div5WheelsOn` String, `Div5TotalGTime` String, `Div5LongestGTime` String, `Div5WheelsOff` String, `Div5TailNum` String) ENGINE = ReplicatedMergeTree('/clickhouse/tables/01-01/ontime', 'cluster01-01-1') PARTITION BY toYYYYMM(FlightDate) ORDER BY (Year,FlightDate,intHash32(Year))注意:下面这种创ReplicatedMergeTree已经被弃用
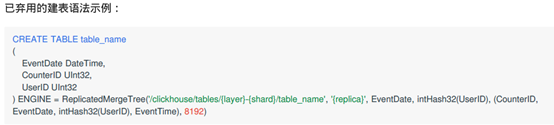
b. 六个实例中创建sql语句大部分相同 不同部分如a中绿色标出
gawh201实例1(config.xml对应的)为:
'/clickhouse/tables/01-01/ontime', 'cluster01-01-1'
gawh201实例2(config1.xml对应的)为:
'/clickhouse/tables/01-03/ontime', 'cluster01-03-2'
gawh202实例1(config.xml对应的)为:
'/clickhouse/tables/01-02/ontime', 'cluster01-02-1'
gawh202实例2(config1.xml对应的)为:
'/clickhouse/tables/01-01/ontime', 'cluster01-01-2'
gawh203实例1(config.xml对应的)为:
'/clickhouse/tables/01-03/ontime', 'cluster01-03-1'
gawh203实例2(config1.xml对应的)为:
'/clickhouse/tables/01-02/ontime', 'cluster01-02-2'
解释:
ReplicatedMergeTree('/clickhouse/tables/01-01/ontime', 'cluster01-01-1')
第一个参数为ZooKeeper 中该表的路
第二个参数为ZooKeeper 中的该表的副本名称
注意:
这里的配置要和每个clickhouse实例的metrika*.xml的macros标签对应,如果仔细看可以发现规律
3.3. ReplicatedMergeTree表创建无误后,约定一个主节点创建Distributed表,这里约定gawh201的clickhouse实例1(config.xml文件对应)
CREATE TABLE ontime_all AS ontime ENGINE = Distributed(cluster, qwrenzixing, ontime, rand())3.4.写入数据
在下载的航班数据目录,执行以下脚本:
for i in *.zip; do echo $i; unzip -cq $i '*.csv' | sed 's/\.00//g' | clickhouse-client --host=gawh201 –port=9002 --query="INSERT INTO qwrenzixing.ontime_all FORMAT CSVWithNames"; done3.5.数据写入成功后对每个实例上分片和备份的数据做一个比较
select count(1) from qwrenzixing.ontime;节点 实例1(9002) shard 实例2(9002) replica
gawh201 59667255 59673242
gawh202 59670658 59667255
gawh203 59673242 59670658
结果已经非常明显了
select count(1) from qwrenzixing.ontime_all;数据总量:179011155
3.6.ReplicatedMergeTree创建及写入无误,现在来验证某一个节点宕机现有数据查询的一致性
a. 将gawh202上的两个实例服务全部停止模拟gawh202节点宕机:
在gawh202节点上
$: /etc/init.d/clickhouse-server stop
$: /etc/init.d/clickhouse-server1 stopb. 首先验证查询,在分布式表中查询数据总量
$:clickhouse-client --host gawh201 --port 9002select count(1) from qwrenzixing.ontime_all;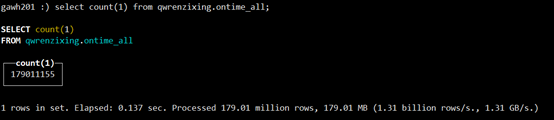
总量仍然没有变,证明对于查询单节点宕机数据一致性得到了保证,当然,当只有gawh203宕机,其他节点不宕机,结果和gawh202宕机是一样的
3.7.验证gawh202,gawh203两个节点四个示例全部宕机现有数据查询是否能保证一致性
a. 将gawh202, gawh203上的两个实例服务全部停止模拟gawh202节点宕机:
在gawh202,gawh203上均执行:
$: /etc/init.d/clickhouse-server stop
$: /etc/init.d/clickhouse-server1 stopb. 首先验证查询,在分布式表中查询数据总量
$:clickhouse-client --host gawh201 --port 9002select count(1) from qwrenzixing.ontime_all;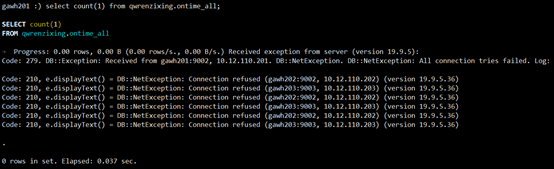
直接报错,可见在该方案中,gawh201作为主节点不能宕机,gawh202,gawh203只允许一个节点宕机。
4. 数据写入单节点宕机数据一致性方案
4.1. 删除三个节点六个clickhouse实例的的全部本地表
drop table ontime4.2. 删除主节点gawh202的实例1(config.xml文件对应)的分布式表
drop table ontime_all注意:
clickhouse不支持delete from table所以只能删表
4.3. 写入数据
按照3.2,3.3,,3.4步骤写入数据
4.4. 写入过程中停止gawh202上的两个实例模拟gawh202宕机
这里写入实例航班数据(179011155)需要10分钟左右
参照3.6的a
4.5. 数据写完之后在主节点上查询分布式表对比总量
$:clickhouse-client --host gawh201 --port 9002select count(1) from qwrenzixing.ontime_all;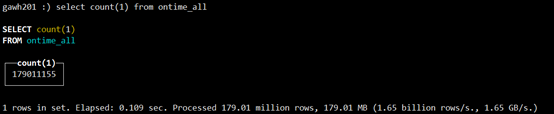
可见数据写入一致性方案是成功的
5. 总结说明
5.1. 弊端
从上面的步骤中可以看出基于zookeeper + ReplicatedMergeTree (复制表) + Distributed(分布式表)的高可用及数据一致性方案是非常繁琐的,包括配置,创复制表,这是因为clickhouse是对于集群和高可用时手动挡的,不像hadoop生态的数据库hive,hbase那样对分布式这块简单便捷。但集群越扩越大,该方案会带来配置和维护的巨大成本
5.2. 是否需要在每个节点上都起两个clickhouse实例
这里因为机器少的原因,所以在每个节点都起两个clickhouse服务实例,如果机器充足,每个实例一个节点。在配置分片和备份的时候相互两两关联。但权衡来看,这样会,这不是一个很好的方案,因为在集权健壮的情况下。一个节点一个实例有点浪费资源。而且许多节点在集群健壮下都不会发挥作用
5.3. 集群扩展
a. 四个节点方案(更多节点可以参照规律)
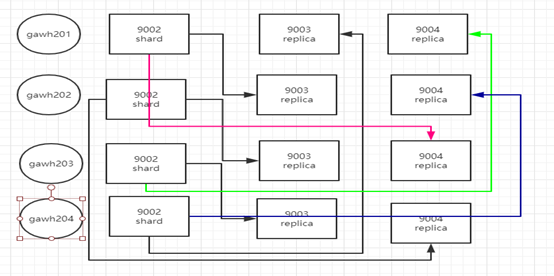
b. 以上节点一个节点宕机参照三数据肯定可以保证一致性,来看两个节点宕机是否仍然能保证

如上图实例,肯定是可以保证的,但是节点gawh204压力会加大,从这里也可以看出超大集群保证高可用和数据一致性会是比较简单但却繁琐的问题