次の表Tには、我々は3と5の間でkは、あなたが走査線検索操作の数倍の木、どのくらいの意志を実行する必要がT SELECT * FROMを実行する場合は?
mysql> create table T ( id int primary key, k int not null default 0, name varchar(16) default '', index (k)) engine=InnoDB; mysql>insert into T values(100,1,'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');次の図に示す指数の組織構造はInnoDB
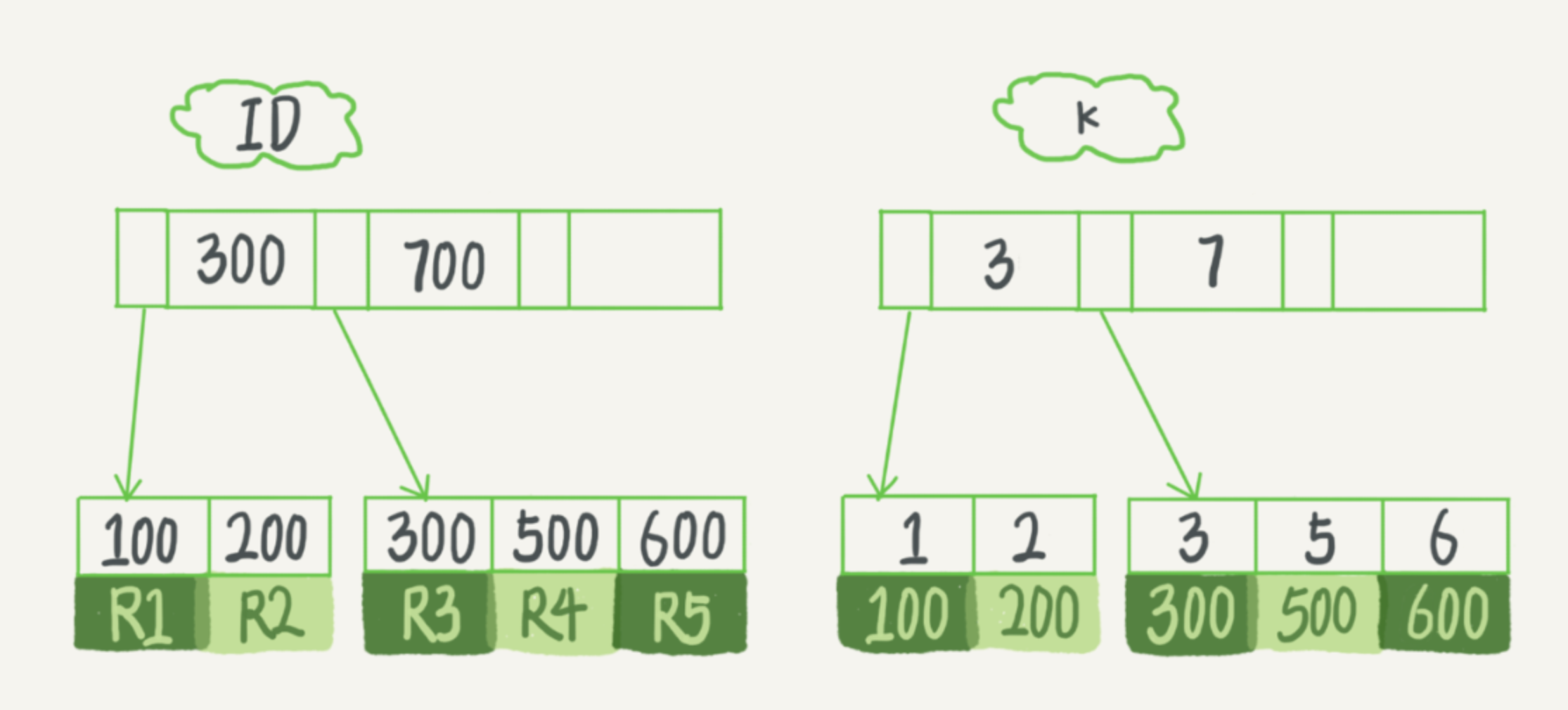
今、私たちは、このSQLクエリステートメントの実行の流れを見てみましょう:
- K = 3は、ID = 300を取得し、インデックスツリーKで記録されたインデックスを検索します。
- 次いで、ID = 300 R3に対応する主キーインデックスツリーのレコードを見つけました。
- 次の値k = 5、ID = 500を得るために、インデックスツリーのK。
- プライマリキーインデックスツリーへ= 500 R4を発見IDに対応します。
- K値k = 6におけるインデックスツリーを削除し、条件が、ループの端部を満たしません。
このプロセスでは、探索木の処理に主キー索引の背中には、我々はテーブルにコールバック。あなたが見ることができ、クエリ処理は二回表に3つのレコードのk個のインデックス・ツリー、バックを読んで、この例では、唯一の主キー索引の目的のクエリ結果データから、そのテーブルに戻りました。だから、そこにある可能性が高いことのプロセスを避けるために、テーブルにインデックスバックによって最適化されるように?
インデックスをカバー
文がTから選択IDを実行した場合は3と5の間でkは、その後のみ必要ID値、およびインデックスIDの値は、このようにすぐに結果を提供し、ツリーのkにすでにある場合、あなたが戻ってテーブルにする必要はありません。言い換えれば、このクエリは、インデックスkは、私たちの調査のニーズをカバーしている、我々はカバーインデックスと呼ばれます。
カバーインデックスは、ツリーの検索数を減らすことができるので、大幅ので、カバーインデックスは一般的なパフォーマンス最適化ツールで使用し、クエリのパフォーマンスを向上させます。走査線の数は、MySQL 2であるように、インデックスkにおける実際のリードを3つのレコードを使用して、エンジンカバーインデックスの内部に、なおが、MySQLサーバ層のために、二つのレコードは、それがエンジンを見つけるために取りました。
次の問題の議論:テーブル上の公開情報は、それが必要であるかどうかのジョイントインデックスID番号と名前を設定するには?
CREATE TABLE `tuser` (
`id` int(www.moyouylzcdl.cn) NOT NULL, `id_card` varchar(32) DEFAULT NULL, `name` varchar(32) DEFAULT NULL, `age` int(www.yuanyyleezc.cn) DEFAULT www.uedylezc.cn NULL, `ismale` tinyint(1) DEFAULT NULL, PRIMARY KEY (`id`), KEY `id_card` (`id_card`), KEY `name_age` (`name`,www.xinyiylzc.cn`age`) ) ENGINE=InnoDB私たちは、ID番号が一意にクエリID番号に基づいて国民の要求がある場合、私たちはIDの数が十分であるにインデックスを付け、その後、(ID番号を作成する必要がある、と言うことです国民を、特定することを知っています共同インデックスの名前)、それはスペースの無駄ではないでしょうか?
高周波数はID番号に応じて、彼の名前をチェックする必要がある今がある場合は、完全なインデックス・リンクそれは理にかなっています。リクエストに応じて、この周波数インデックスをカバーするために使用することができ、ステートメントが実行されている削減、バックテーブル全体の行をチェックする必要がなくなりました。
もちろん、インデックスフィールドを維持することは、常に価格です。被覆インデックスをサポートするために、冗長なインデックスを確立する際のトレードオフを考慮する必要があります。
最も左のプレフィックスの原則
このB +ツリーインデックス構造インデックスは、レコードを検索するために、「一番左の接頭辞」に使用することができます。視覚的にこの概念を説明するために、我々は、関節の指標を分析するためにショー(名前、年齢)の下のインデックス概略図を(名前、年齢)を使用します。
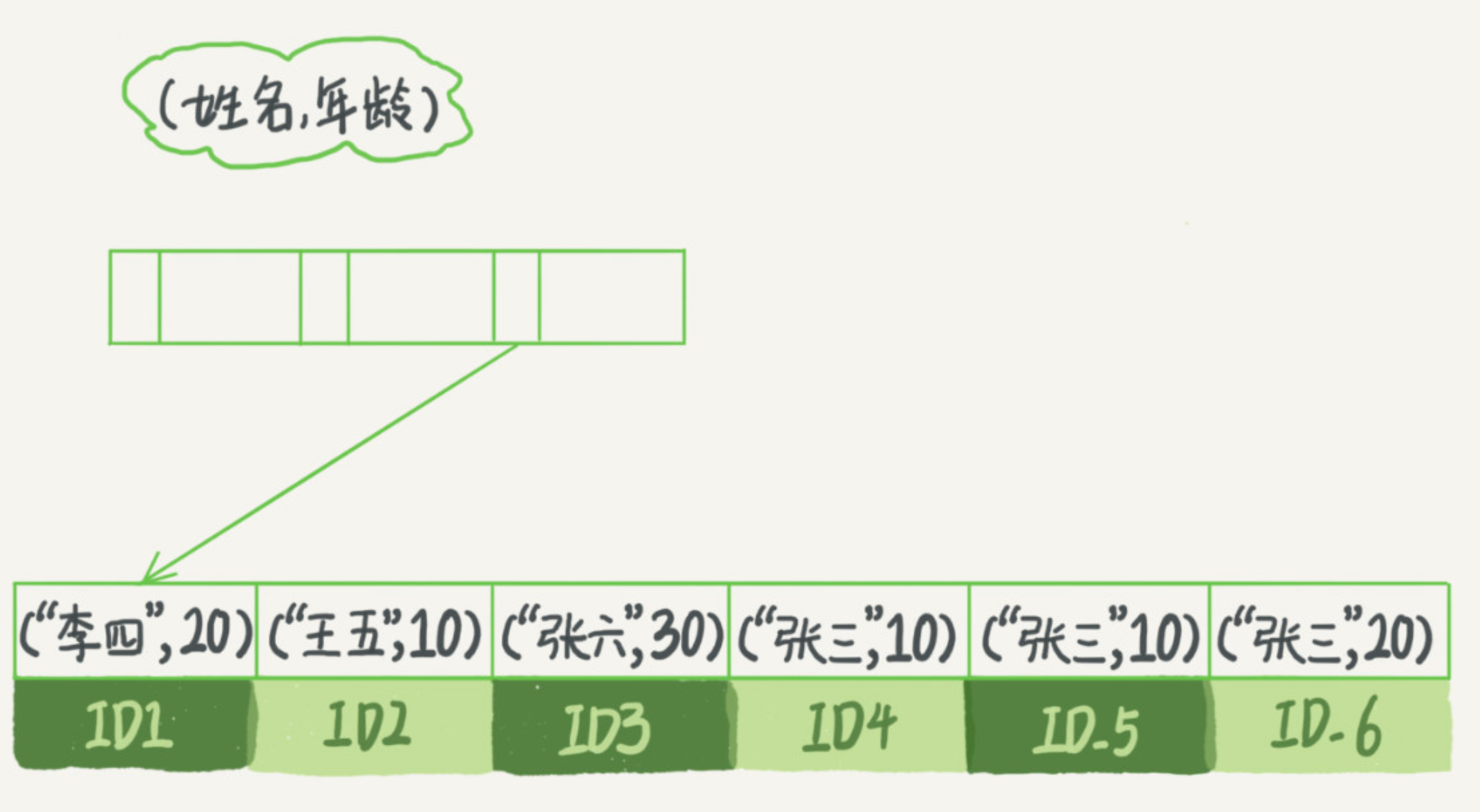
これは、索引エントリが内部定義されたインデックスフィールドに合わせて出現順にソートされ、見ることができます。ニーズがで発見された場合、すべての論理名がすばやく移動ID = 4に、そして反復後方には、あなたが望むすべての結果を取得することができ、「ジョー・スミス」です。あなたが最初の単語のすべての名前を確認したい場合は、「張」の人、あなたのSQL文の条件はどこ「『張%』のような名前、そしてあなたは、インデックスを過ごすことができ、最初に発見」されています条件が満たされていないまで一致したレコードがID3、その後、反復後方です。
それは限り最も左接頭辞として、あなたは、検索を高速化するためにインデックスを使用することができ、インデックスだけでなくすべての定義を見ることができます。最も左のプレフィックスが最も左-Nフィールドの共同インデックスすることができ、それはまた、Mの文字の最も左の文字列のインデックスすることができます。
共同インデックスを確立するには、どのようにインデックスフィールドの順序を変更するには
多重化機能のインデックス:ここでは、基準は評価します。それが最も左接頭辞、そうだwhen've(a、b)は共同インデックスをサポートできるため、一般的に別のインデックスを必要としません。いくつかあるので、第一の原則は、あなたが順序を調整することにより、少ないインデックスを維持することができれば、その後、優先順位の順に多く使用されていることです。
インデックスプッシュダウン
私たちは、例えば、まだ共同インデックス市の時計(名前、年齢)となりました。需要があれば、今風水:名の各単語の重量を量るためにテーブルをチェックアウト張、と誰もが年齢10で、これはSQLを書く必要があります:
select * from tuser where name like '张%' and age=10あなたは探索木の時にこのステートメントので、唯一の「張」は記録ID3の条件を満たすために最初に見つけ、プリフィックス索引のルールを知っています。もちろん良いが、全表スキャンよりも優れている、良いです。その後、他の条件が満たされるか否かが判断されます。MySQL5.6の前に、一つは唯一のテーブルにID3の後ろから開始することができます。データ行を識別するための主キーインデックス、およびそのフィールド値。インデックスプッシュダウンMySQL5.6はインデックストラバーサルに最適化された導入しました。インデックスに含まれる最初のフィールドを行うために決定され、直接記録条件アウトフィルタは、テーブルに多数のバックを減らすために、満足していません。以下のフローチャートは、2つの処理を実行することです。
図3.ノーインデックスプッシュダウン実行プロセス
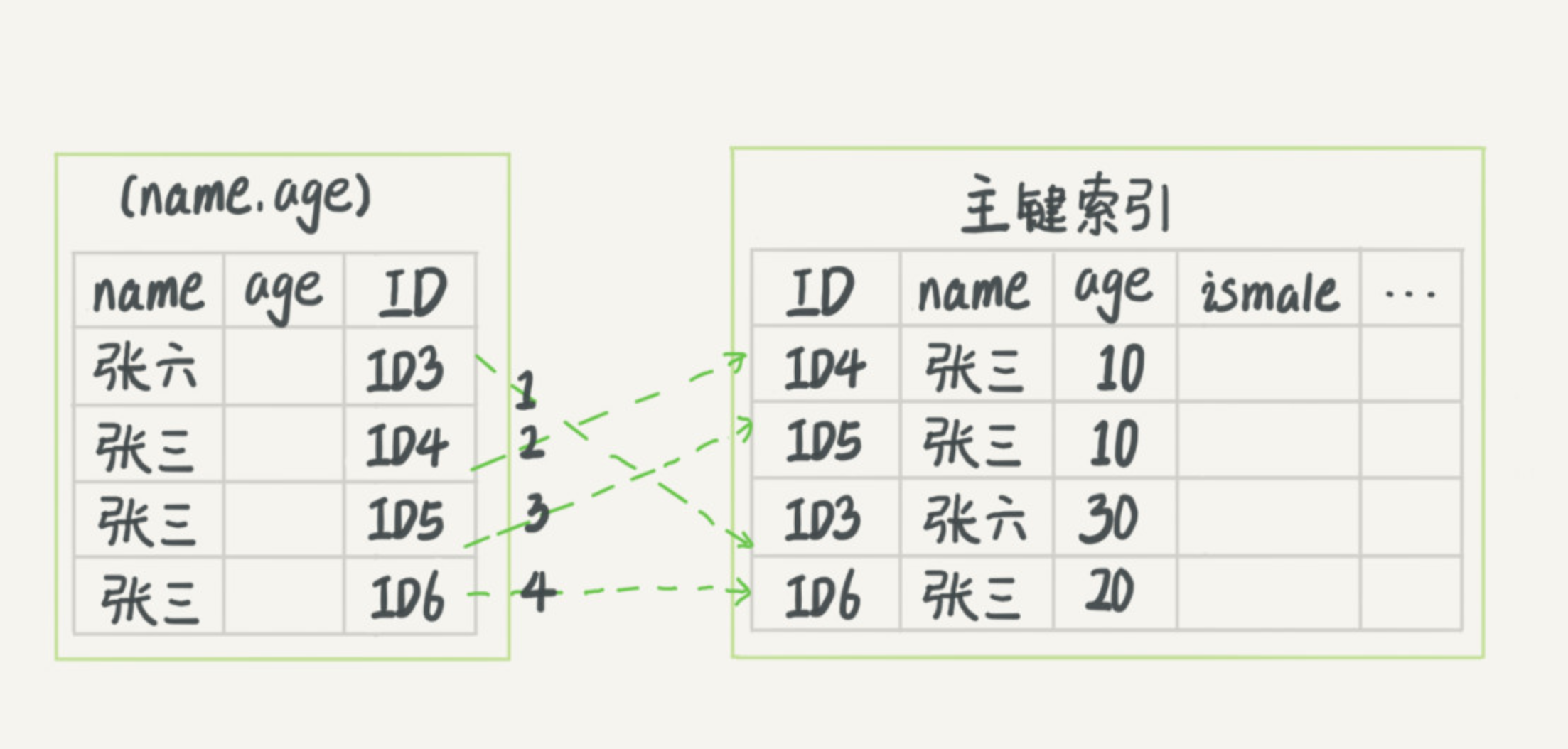
図4の実行フローインデックスプッシュダウン
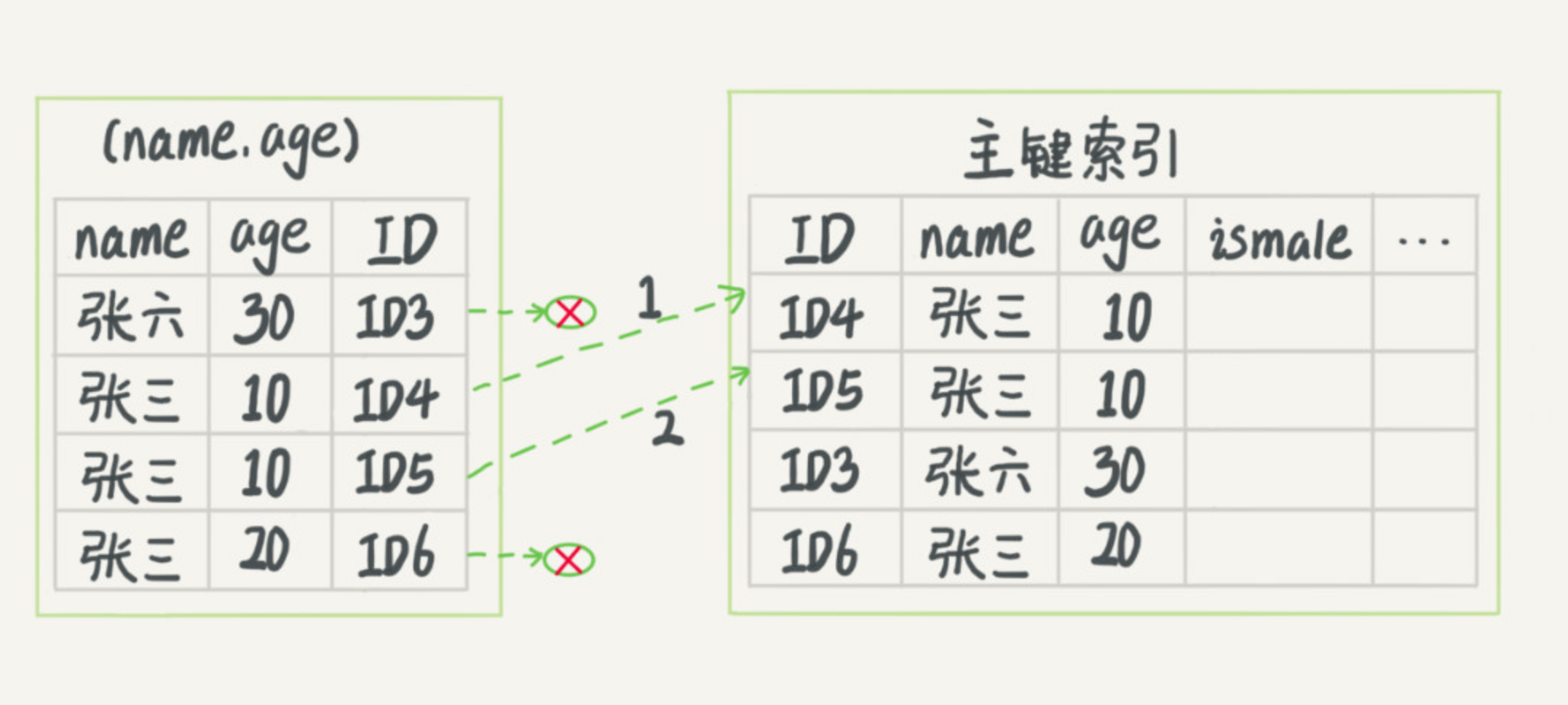
ここで点線の矢印のそれぞれは、バックテーブルを示しています。
図3では、(名前、年齢)は、特に年齢のインデックス値を削除したが、このプロセスは、年齢のInnoDBの値に行きませんが、順序、レコードA「の名前の最初の単語は、 『シート』です」丸棒のテーブルを削除します。そこで我々は、テーブルに4回を返却する必要があります。