ディレクトリ
消費者クライアントマルチスレッディング
KafkaProducerはスレッドセーフですが、KafkaConsumerなくはスレッドセーフ。KafkaConsumerは、定義された取得()メソッドは、唯一のスレッドで現在動作するかどうかを検出するために使用される他のスレッドが例外を操作している場合はConcurrentModifcationExceptionをスローします。
java.util.ConcurrentModificationException: KafkaConsumer is not safe for multi-threaded access.アクションの実行前にこの呼び出しのKafkaConsumerが取得する各パブリックメソッドを()メソッドによって実行される、唯一のウェイクアップ()メソッドは例外です。
特定の定義を取得()メソッドは次の通りであります:
private final AtomicLong currentThread
= new AtomicLong(NO_CURRENT_THREAD); //KafkaConsumer中的成员变量
private void acquire() {
long threadId = Thread.currentThread().getId();
if (threadId != currentThread.get() &&
!currentThread.compareAndSet(NO_CURRENT_THREAD, threadId))
throw new ConcurrentModificationException
("KafkaConsumer is not safe for multi-threaded access");
refcount.incrementAndGet();
}その唯一のスレッドの動作を保証するために、スレッドの並行操作の発生を検出するための標識された方法をカウントすることにより、スレッド操作の取得()メソッドかどうか。取得()メソッドとペア解除()メソッドは、その対応するロック・アンロック動作を示しています。
我々はそれが正しく、効果的に適切なプログラムのロジックを記述するために私達を促すことができる内部の仕組みを理解し、その後、明示的に実用的なアプリケーションで呼び出す必要はありますが、ないように取得()メソッドおよびrelease()メソッドは、プライベートメソッドです。
消費者のニュースを達成する方法をマルチスレッド、マルチスレッドの目的は、全体的な購買力を向上させることです。マルチスレッド実装の様々な、第一及び最も一般的な方法があります。スレッドは、オブジェクトがKafkaConsumer各スレッドのインスタンス化である、閉じ
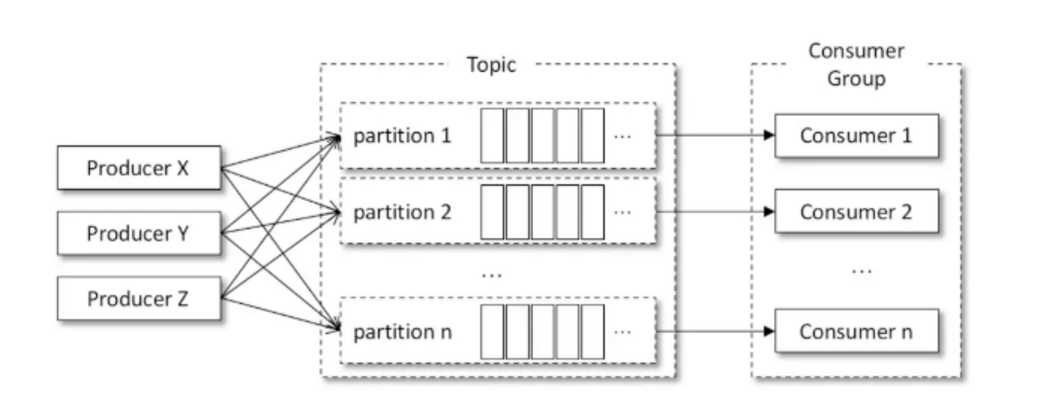
KafkaConsumer例にスレッド対応は、我々は消費者のスレッドにそれを呼び出すことができます。消費者のスレッドがニュースで1つ以上のパーティションを消費することができ、すべての消費者のスレッドが同じコンシューマ・グループに属しています。並行度この実装は、パーティションの実際の数に制限されているスレッドの数は、消費のパーティションの数よりも大きい場合、一部の消費者スレッドがアイドル状態になっているがあります。
public class FirstMultiConsumerThreadDemo {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
public static Properties initConfig(){
Properties props = new Properties();
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
StringDeserializer.class.getName());
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerList);
props.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
return props;
}
public static void main(String[] args) {
Properties props = initConfig();
int consumerThreadNum = 4;
for(int i=0;i<consumerThreadNum;i++) {
new KafkaConsumerThread(props,topic).start();
}
}
public static class KafkaConsumerThread extends Thread{
private KafkaConsumer<String, String> kafkaConsumer;
public KafkaConsumerThread(Properties props, String topic) {
this.kafkaConsumer = new KafkaConsumer<>(props);
this.kafkaConsumer.subscribe(Arrays.asList(topic));
}
@Override
public void run(){
try {
while (true) {
ConsumerRecords<String, String> records =
kafkaConsumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
//处理消息模块 ①
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
}別のKafkaConsumerインスタンス内にラップ消費者のスレッドに代わって内部クラスKafkaConsumerThread、。消費者が複数のスレッドは、スレッドconsumerThreadNum消費変数の数で指定された外部メインクラス()メソッドを、開始します。パーティションの数がconsumerThreadNumはパーティション主題の数を知ることなく、パーティションの数の値以下に設定することができる、一般的に事前にテーマを知ることができ、次に妥当を設定することができ、間接的にpartitionsFor KafkaConsumerクラス()により得られるする方法であってもよいですconsumerThreadNum値。
このマルチスレッド実装とオープン複数の消費者以上の本質的な違いは、各スレッドは、注文メッセージに各パーティションを消費することができるという利点を有する、方法を処理していません。デメリットは、各消費者のスレッドは、別々のTCP接続を維持しなければならないパーティションとconsumerThreadNumの数の値が大きい場合、それは小規模なシステムのオーバーヘッドが生じないことは明らかです。
周波数を引っ張る非常に迅速なメッセージの処理、次いでポール()は高くなり、したがって、全体的な消費の性能を強化する場合は、逆に、ここではメッセージの遅い処理は、例えば、ある場合には、トランザクションの動作、または待機RPC同期応答であり、その後、周波数を引っ張るために()をポーリングし、それによって全体的な消費性能の低下をもたらす、低下します。一般的には、ポーリング()スピードプルメッセージは非常に高速ですが、ボトルネックは、この一つのメッセージを処理の全体的な消費にもあり、我々はこの部分に特定の方法を改善することであれば、我々は消費者の全体的なパフォーマンスを導くことができます改善されました。
元の消費者スレッドの数の制限を破ることができる複数のコンシューマスレッドコンシューマ同じパーティションにこの対応は、これは割り当てすることによって達成される第二の方法()、シーク()メソッドは、パーティションの数を超えることはできませんさらに消費する能力を向上させます。しかし、提出と変位のシーケンス制御のためのそのような実施過程は非常に複雑で、あまりにも少し実用になります。
第三の実施態様では、マルチスレッドの実装にメッセージ処理モジュール
public class ThirdMultiConsumerThreadDemo {
public static final String brokerList = "localhost:9092";
public static final String topic = "topic-demo";
public static final String groupId = "group.demo";
//省略initConfig()方法,具体请参考代码清单14-1
public static void main(String[] args) {
Properties props = initConfig();
KafkaConsumerThread consumerThread =
new KafkaConsumerThread(props, topic,
Runtime.getRuntime().availableProcessors());
consumerThread.start();
}
public static class KafkaConsumerThread extends Thread {
private KafkaConsumer<String, String> kafkaConsumer;
private ExecutorService executorService;
private int threadNumber;
public KafkaConsumerThread(Properties props,
String topic, int threadNumber) {
kafkaConsumer = new KafkaConsumer<>(props);
kafkaConsumer.subscribe(Collections.singletonList(topic));
this.threadNumber = threadNumber;
executorService = new ThreadPoolExecutor(threadNumber, threadNumber,
0L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<>(1000),
new ThreadPoolExecutor.CallerRunsPolicy());
}
@Override
public void run() {
try {
while (true) {
ConsumerRecords<String, String> records =
kafkaConsumer.poll(Duration.ofMillis(100));
if (!records.isEmpty()) {
executorService.submit(new RecordsHandler(records));
} ①
}
} catch (Exception e) {
e.printStackTrace();
} finally {
kafkaConsumer.close();
}
}
}
public static class RecordsHandler extends Thread{
public final ConsumerRecords<String, String> records;
public RecordsHandler(ConsumerRecords<String, String> records) {
this.records = records;
}
@Override
public void run(){
//处理records.
}
}
}RecordHandlerクラスは、スレッドプールを介してメッセージのRecordHandlerバッチ処理が起動され、消費者スレッド、メッセージ、およびKafkaConsumerThreadクラス対応を処理するために使用されます。最後のパラメータ設定でThreadPoolExecutorは、全体的な能力は、スレッドプールポーリングの購買力に追いつくためにKafkaConsumerThreadクラスは、CallerRunsPolicy()であることに注意してください()引っ張るは、異常現象が生じることを防止できます。第3の実施形態は、さらに、複数KafkaConsumerThreadインスタンスをオンにすることによって、全体的な消費電力を向上させるために、スケールを達成することができます。
最初の実装に比べ達成する第三の方法は、スケールする能力に加えて、TCP接続は、システムリソースの消費を低減することができるが、欠点は、より困難に処理するためのメッセージの順序です。
提出の具体的な変位を行うために場合は、最初の実装のために、直接run()メソッドは、KafkaConsumerThreadの中で達成することができます。共有変数のオフセットの導入が提出参加する第三の実装については、
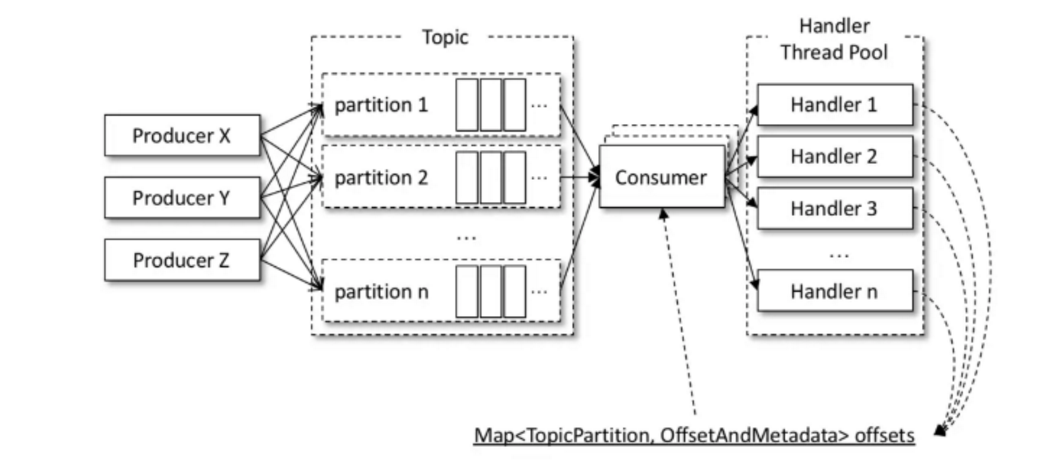
メッセージを処理した後RecordHandlerハンドリング各記憶されたメッセージがオフセットに共有可変容量消費にマッピングされ、KafkaConsumerThreadオフセットは各ポーリング()メソッド後のコンテンツを読み取り、その変位を提出しています。読み書きオフセットの必要性の実現のプロセスがハンドルをロックでは、並行性の問題を防止することに注意してください。そして、この問題への書き込みオフセットのカバーの変位時の注意を払うする必要は、次のように実装されるRecordHandlerクラス()メソッドを実行します
for (TopicPartition tp : records.partitions()) {
List<ConsumerRecord<String, String>> tpRecords = records.records(tp);
//处理tpRecords.
long lastConsumedOffset = tpRecords.get(tpRecords.size() - 1).offset();
synchronized (offsets) {
if (!offsets.containsKey(tp)) {
offsets.put(tp, new OffsetAndMetadata(lastConsumedOffset + 1));
}else {
long position = offsets.get(tp).offset();
if (position < lastConsumedOffset + 1) {
offsets.put(tp, new OffsetAndMetadata(lastConsumedOffset + 1));
}
}
}
}対応するカテゴリの変位に対するコミットメントはKafkaConsumerThreadラインを追加①
synchronized (offsets) {
if (!offsets.isEmpty()) {
kafkaConsumer.commitSync(offsets);
offsets.clear();
}
}这种位移提交的方式会有数据丢失的风险。对于同一个分区中的消息,假设一个处理线程 RecordHandler1 正在处理 offset 为0~99的消息,而另一个处理线程 RecordHandler2 已经处理完了 offset 为100~199的消息并进行了位移提交,此时如果 RecordHandler1 发生异常,则之后的消费只能从200开始而无法再次消费0~99的消息,从而造成了消息丢失的现象。这里虽然针对位移覆盖做了一定的处理,但还没有解决异常情况下的位移覆盖问题。
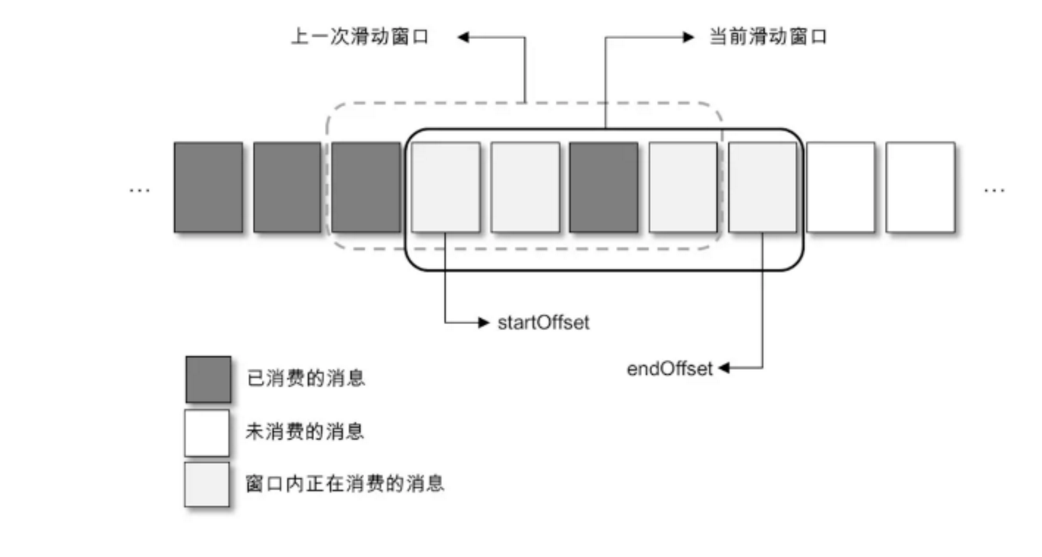
对此就要引入更加复杂的处理机制,这里再提供一种解决思路,参考下图,总体结构上是基于滑动窗口实现的。对于第三种实现方式而言,它所呈现的结构是通过消费者拉取分批次的消息,然后提交给多线程进行处理,而这里的滑动窗口式的实现方式是将拉取到的消息暂存起来,多个消费线程可以拉取暂存的消息,这个用于暂存消息的缓存大小即为滑动窗口的大小,总体上而言没有太多的变化,不同的是对于消费位移的把控。
如上图所示,每一个方格代表一个批次的消息,一个滑动窗口包含若干方格,startOffset 标注的是当前滑动窗口的起始位置,endOffset 标注的是末尾位置。每当 startOffset 指向的方格中的消息被消费完成,就可以提交这部分的位移,与此同时,窗口向前滑动一格,删除原来 startOffset 所指方格中对应的消息,并且拉取新的消息进入窗口。滑动窗口的大小固定,所对应的用来暂存消息的缓存大小也就固定了,这部分内存开销可控。
方格大小和滑动窗口的大小同时决定了消费线程的并发数:一个方格对应一个消费线程,对于窗口大小固定的情况,方格越小并行度越高;对于方格大小固定的情况,窗口越大并行度越高。不过,若窗口设置得过大,不仅会增大内存的开销,而且在发生异常(比如 Crash)的情况下也会引起大量的重复消费,同时还考虑线程切换的开销,建议根据实际情况设置一个合理的值,不管是对于方格还是窗口而言,过大或过小都不合适。
如果一个方格内的消息无法被标记为消费完成,那么就会造成 startOffset 的悬停。为了使窗口能够继续向前滑动,那么就需要设定一个阈值,当 startOffset 悬停一定的时间后就对这部分消息进行本地重试消费,如果重试失败就转入重试队列,如果还不奏效就转入死信队列。真实应用中无法消费的情况极少,一般是由业务代码的处理逻辑引起的,比如消息中的内容格式与业务处理的内容格式不符,无法对这条消息进行决断,这种情况可以通过优化代码逻辑或采取丢弃策略来避免。如果需要消息高度可靠,也可以将无法进行业务逻辑的消息(这类消息可以称为死信)存入磁盘、数据库或 Kafka,然后继续消费下一条消息以保证整体消费进度合理推进,之后可以通过一个额外的处理任务来分析死信进而找出异常的原因。