最近、私は注意に関するいくつかの記事をお読みください。注意は、人間の視覚の仕組みを理解することは簡単ですが、コンピュータの問題を使用する方法について簡単ではありません。
実際には15年前の視覚的なタスクに注意を持っていましたが、なぜ17年の最も簡単なセネトは前例のない成功を収めて?一つの理由は、前の仕事のほとんどは、特性(チャネル)の寸法の注目を考慮し、別の方法(空間)空間的注意、およびセネトを検討するということである。第二の実施形態が実装され、セネト基本的にちょうど非常にシンプル構造が、ニューラルネットワークのより強力な学習能力を与えた、と著者は達成しているバーストテーブルの前にも非常に良いですが、最終的なパフォーマンス(17年は優勝分類タスクを獲得しました)。
もちろん、主突極性の形で低レベルのタスク上で最も頻繁にすることにより、高レベルのタスクでの注意は、発表しました。
SOTAとは、画像分類タスクの前方の仕事のためにネットワーク設計の注目を達していません。私たちは、ネットワークの深さを懸念しているため。セネトが突破口を達成する前に、実際には[[そして、この記事では、わずかにカニを食べるために最初の人も、優れた技術により実現します]。セネトだけでなく、ネットワーク、単純なプラグインプラグアンドプレイ]
強みの注目メカニズムに参加することはポイントです:タイプの機能を識別するためには、ネットワークの表現が強いことができます。[チェック、ネットワーク+の注目は、多くの作業を生成されています]
もちろん、理由はユニークなネットワーク設計のこの記事で、追加の注意の利点をもたらします。これは、ネットワークの導入に言うことです。私たちは、回路図と効果を見てみましょう:

図の注目は、マスクを生成する入力機能であり、一体化した入力及び出力特性を得る単にモジュールにより本明細書に、左。
右に示すように、マスクの異なるレベルが異なる問題を有します。背景、そのような空や建物などへのマスクの低レベルの注意、マスクの高レベルのみバルーンの底部に関する。
1.関連作品
[23]確認:注意のメカニズムは、人間の知覚に重要です。具体的には、トップダウン、ボトムアップ情報による情報の人間の送信プロセスを案内します。[Bloggerが理解:トップダウンの意思決定の注目を意味理解(文脈)の文脈に応じてキャラクタジェネレータの底の部分を参照して、所属]
注意が広く使用さRNNとLSTMてきました。画像分類の分野では、三つの形式で、このトップダウンの注意のメカニズム:
シリアル化。意思決定プロセスのシーケンスとして画像分類。
地域の提案。提案の画像分類は、一般的に地上の真実を持っていないので、それは多くの場合、教師なし学習です。
制御のドア。LSTMと高速道路ネットワークとして。
2.残留注意ネットワーク
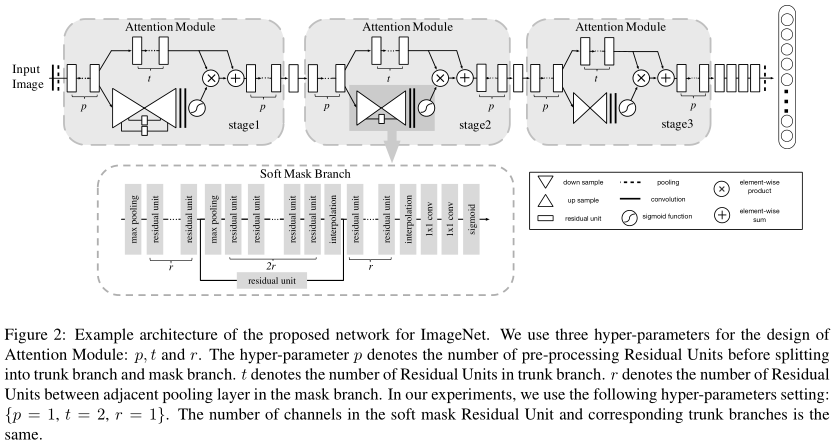
画像は、最初に後\(1 \ P =)トランク及びブランチ(上面)に、それぞれの処理の第残留ユニット、及び分岐マスク。
トランクは分岐され(T = 2 \)\残留ユニット。
図に、以下に示すように、マスクは、柔らかい注意分岐構造です。\(R = 1 \)二つの層の最大プール間の残留単位の数です。第1のダウンサンプリング、サンプルネットワーク構造リットルである伝説に記載の方法。
その後、計算、乗算ポイントトランクの出力、およびバックボーンの出力を加算した後に注意。
注意モジュール内の上記のプロセスの実装では。著者は、3回繰り返し行います。
著者は、マスクの別々の分岐が2つの利点があると考えています。
選択的な作用機構。[これは注目の利点である、実際には、支店ではほとんど関係を持っています]
勾配もアクションを制御します。例えば勾配ノイズ領域を抑えます。[著者はこれを確認しなかったが、唯一ノイズに対するロバスト性を示すこと]
なぜそんなにアテンションモジュールは、それをスタック?マスク枝[17]は十分ではありませんか?注目の異なるレベルが異なっているので、それを分離することを学ぶことが最善である:これは事実FIG1によって説明されています。
2.1注意残留学習
だけではないが、十分に説明した理由の十分な注意[ありません。このマスクブランチは深ネットワークトレーニング]の難しさにつながる、チャネル勾配の広がりを損なっ:個人的に私はResNetの同じ原因や動機だと思います。
この目的のために、我々は、次に短い聖歌で接続すなわちマスクは、トランクの出力と乗算され、その後、トランク出力に加えました。乗算結果は、残留としてバックボーン、すなわちへ出力マイナー調整、である:次のように理解することができます。
極端なケースを想像してみて:この時点で、我々はすべての注意調整機能を完了する必要はありません、マスクは、ライン上の0です。難しさを学ぶのない枝をマスクしません。
2.2トップダウンとボトムアップ
この最後の概念はDBN [21]シナリオは、本明細書に記載されている唯一の違いは、付属しています。図:
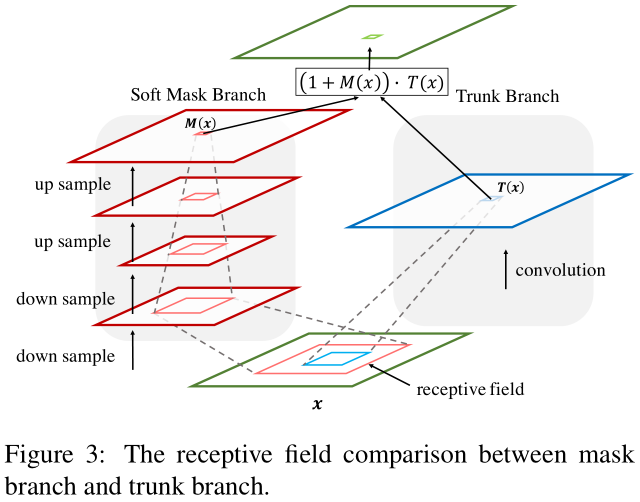
右側は急速な派生のボトムアッププロセスであり、左側がスロートップダウンです。トップダウンとは何ですか?マスクブランチので、したがって、その受容野を増加させる、ダウンサンプリング(最大プーリング)とコンボリューションを継続します。トップレベルでは、取得マスク情報の比較的高いレベルです。マスクと右のようにトップダウンの情報伝達と呼ばれる、ガイダンス機能とレイヤ情報の対応を掛けます。
2.3正則注意
著者はまた基づいています(注意を)マスキングすることが陽性であると考え。単純なシグモイド正則、いずれかのいずれかのチャネルの平均値で割ったすべての平均値及び正規化点シグモイドの分散のチャネルのいずれか。これは、最も簡単なの(結合されていない)という最高のを発見しました。
少し休みます。