なぜBlueStore
まず、セファロオリジナルのファイルストアは、EXT4、のbtrfs、XFSなどLinuxでさまざまなファイル・システムと互換性が必要です。理論的には、各ファイルシステムには、POSIX契約を実装し、実際には、すべてのファイルシステムは少し「あまり標準」の場所があります。セファロは、信頼性に大きな重点を達成し、ひいては異なるWalkaroundハックを紹介したり、各ファイルシステムの必要性、例えば名前の変更はない冪等、などが挙げられます。作品は、セファロの継続的な開発のための大きな負担となっています。
第二に、ファイルストアおよびLinuxファイルシステムの上に構築。POSIXは、非常に強力なを提供しますが、ほとんどのセファロは本当に必要ではありません。これらの機能は、パフォーマンスの足かせとなっています。一方、セファロファイルシステムの実装のいくつかの機能は、例えば、ディレクトリトラバーサル順序の要件、およびその上で、友好的ではありません。
一方、問題は二重のセファロログです。、単一OSD内のものを達成するために、ファイルストアの書き込みパスをオーバーライド停電回復することができ、途中、だけでなく、支援を確保するために、セファロは、最初のログに書き込まれたデータとメタデータを変更し、ログインした後、そのデータが実際に書き込まれますディスク位置オフ。ACID方法を確保するために、このメソッドログ(WAL)データベースとファイルシステム規格。しかし、ここでセファロで、問題を提起:
データはディスクのスループットを犠牲にしセファロの半分を意味ログダブル問題を、書くこと、つまり、二回書かれています。
- セファロのファイルストアはログ再びそれを行って、Linuxのファイルシステムは、実際には、ログは再びそれを行うで、独自のロギングメカニズムを持っています。
- そのようなRocksDB、LevelDB、などの新しいLSMツリーベースのストレージのためのログデータそのものであるので、必要に応じて、実際には、もはや単一の追加WAL、に従って編成。
- 優れたパフォーマンスSSD / NVM記憶媒体を示します。そして、別のディスク、フラッシュベースのストレージ高い並列処理、利用する必要があります。CPUの処理速度が徐々にこうしてマルチコア並列のより良好な使用を必要とし、記憶されていません。などのストレージ・キューの広範な使用は、簡単に時間のかかる競争によって複雑につながるだけでなく、最適化する必要があります。一方、RocksDBはSSDのために良いサポートがあるというように、それはBlueStoreが採用されています。
また、コミュニティは、ストレージバックエンド用LevelDBと、ファイルストアに問題があった。店舗への変換です。KeyValueオブジェクトストア、代わりに自分のファイルを変換すること。その後、LevelDBストアがオープン、主流を促進するか、またはファイルストアを使用することではありません。しかし、アイデアはBlueStore RocksDBは、メタデータを格納するために使用され、スタンディングです。KeyValueです。
BlueStore全体のアーキテクチャ
生まれbluestoreは、自分のファイルストアは、ジャーナルを維持しても問題にズームインするファイルシステムの必要性を記述するために解決することであり、それ自体がそのようにbluestore主に2つのコア事業分野が行うファイルストアに比べて、SSDに最適化されていないファイルストア:
- ジャーナルを削除し、直接rawデバイスを管理します
- 個別に最適化されたSSDの場合
下に示すように、全体的な構造をbluestore。
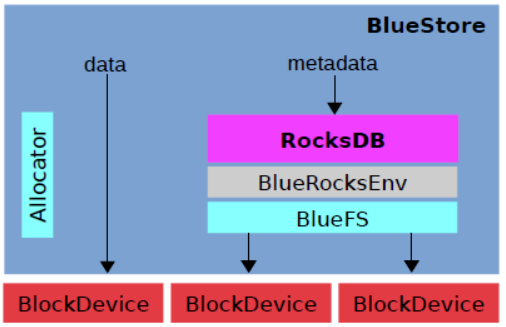
アロケータ(ディスペンサー)裸デバイスの管理によって達成さ、デバイスに直接データを保存し、メタデータのRocksDB保存同じ時間を使用して、ドッキング装置と裸RocksDBの基礎となる自己BlueFSをカプセル化します。
モジュール部門
コアモジュール
- RocksDB:メモリ先行書き込みログデータオブジェクトのCEPHデータOMAPメタデータ、およびメタデータ分配器(分配器は、どこかに保存される実際のデータを決定する責任があります)
- BlueRocksEnv:RocksDBとのインタラクティブなインターフェース
- BlueFS:アドレスメタデータ、ファイル・スペースの割り当ておよび管理やディスクスペース、および実現rocksdb :: Envのインタフェース(SSTおよびストレージRocksDBログファイル)に小さなファイルシステム。rocksdbルーチンは、ファイルシステムの最上位で実行されているので、以下はBlueFSです。これは、同一の物理デバイスに格納されたデータ記憶層、RocksDB BlueStoreデータと実際のデータ・ブロックをバックエンド
- BlockDevice(HDD / SSD):実際の物理データ・ブロック・デバイス、ストレージ
rocksdb自体がファイルシステムに基づいており、直接rawデバイスを操作することはできません。その関連する処理システムは、ユーザがインターフェースを実装することができる、のEnvを抽象化。BlueRocksEnvは、クラスbluestore rocksdbから実装継承:: EnvWrapper、根底にあるrocksdbのためのパッケージングシステムを提供することです。
Envが必要rocksdb小さなファイルシステムBlueFSを達成するために、BlueRocksEnvをインタフェースするため、唯一のインタフェースを実装します。すべての変更は、メタデータ、ログに保存されている永続的なBlueFS、のために、あるBlueFSログメタデータに記録されています。ファイルシステムをマウントし、システムの起動時に、ちょうど私たちは、すべてのメタデータがメモリにロードされていることができ、リプレイを記録します。BluesFSデータとログファイルは、デバイス(BlueFSとBlueStoreは、それぞれ、別のデバイスを指定することができ、生のデバイスを共有することができる)を介して裸のブロックデバイスに保存されています。
bluestore裸デバイスを引き継ぐローカルファイルシステムは、唯一の生のパーティションの物理ブロックデバイスHDD / SSDを使用して、ユーザモードでは、Linux AIO用いて直接裸のデバイスI / O操作を常駐していません。ディスクに直接書き込まBlockDevice、および必要性への書き込みは、ページに合わせて整列するように、オペレーティングシステムのサポートは、唯一DIRECTIOサポートAIOので。AIOが完了したかどうかを確認するために使用aio_threadその内部のスレッドが、あります。その終了後、コールバック関数aio_callbackを経由して、発信者に通知します。
アロケータモジュール
これは実メモリの割り当て特定のブロックに使用される現在のデータ・オブジェクトを格納するために使用される、ビットマップアロケータを達成するために、同じ方法を用いて、このように、複数の状態を記憶するために階層インデックスを使用しながら、メモリの消費量が比較的小さく、平均ディスクニーズ1TBにおそらく35Mの周りにスペースをラム。
BlueStoreモジュール
ストレージエンジンのファイルストアの前に、ファイル内のファイルシステムに対応するオブジェクトの形式は、デフォルトのファイルの4メガバイトのサイズが、bluestoreには、そこには従来のファイルシステムされていないが、自分の裸ディスク、元のためのための必要性を管理するために、データ管理オブジェクトは、対応するオノードは、オノデは、メモリ常駐のデータ構造であり、持続時間はKVの形態でrocksdbに保存されています。
すぐに、最高の性能を有するように別の例外処理経路は非常に複雑になることがありますとして最も一般的に使用されるメモリ書き込みパスはBlueStoreは、できるだけ単純に、できるだけ短くする必要があります。BlueStoreデザインは、次の機能があります。
- セファロは、POSIXファイルシステムを必要とされていません。それを放棄する、単純なファイルシステムを実装しようとすると、RocksDBの使用に特化。BlueFSと呼ばれるこのファイルシステム、
- メタデータは、積極的にRocksDBに格納されているです。KeyValue適当。システムは、データファイルを必要としない、生のブロックデバイスに直接保存することができます。我々はブロックデバイス上で必要なもの、実際には、それは宇宙の分周器(アロケータ)です。
もう一つのポイントは、BlueStore異なるコンポーネントは、異なるデバイスを使用することができます。例えばRocksDB WALは、NVRAM、SST SSD、HDDとデータファイルとファイルを構成するファイル、プログラムは柔軟性があります。
BlueStoreメタデータ管理
書き込みパスに入れる前に、セファロBlueStoreは、メタデータを管理する方法を見てみましょう。オブジェクトデータ構造がディスクにマッピングされる方法の最初の質問である(底部が上向きのCEPHオブジェクトストレージ、パッケージ記憶ブロック、ファイルストレージですか)?
オブジェクトを表すONODE、名前はLinuxのVFS inodeがそこに続くだろうからです。持続性のです。KeyValue形態にRocksDBで、永久メモリオーノード。
複数のlextent、すなわち論理エクステントを含むオーノード。マッピングpextentによってブロブ、すなわち物理エクステント、ディスク上の物理領域にマッピング。ブロブは、通常、同一のオブジェクトから複数のデータを含むが、他のオブジェクトが参照されてもよいです。BNODEオブジェクトのスナップショット後に、複数のオブジェクトは、共有データに使用されています。(理解していません)
BlueStore書き込みパス
書き込みパスは、事務の取扱いを含むが、二重の問題を記録BlueStoreを解決する方法を答えます。
まず、セファロトランザクションは、単一のOSD内で動作、複数のオブジェクトを確保するための操作は、ACIDは、主にその高度な機能を実装するために使用されて実行されます。(一緒ダイナモvノードと同様の配置グループは、ハッシュグループにグループ内の同じオブジェクトにマッピング)OpSequencer各PG、保証それによって実行されるPG順次動作を有しています。物事は次の3つのカテゴリを記述する必要があります。
(1)新たに割り当てられた領域に書き込まれます。メタデータRocksDBが更新されないので、ACIDの考慮事項は、この書き込みは、上書きしても途中、データをオフに存在しないので、ACIDセマンティクスが破壊されている心配しないでください。その後、目に見えるメタデータは、データが行うことに書き込まれた後RocksDBを更新します。したがって、ログは必要ありません。データが書き込まれた後、メタデータの更新がRocksDBに書かれている。RocksDB自体がトランザクションをサポートし、RocksDB情勢などのメタデータの更新が提出します。
BLOBに新しい場所に書き込まれる(2)。同様に、ログは必要ありません。
のみ(上書き)する場合を上書きするための(3)繰延書き込む(遅延書き込み)。また、上記から見ることができ、あなただけがオーバーライドログの問題を考慮する必要があります。このログであり、新しい書き込みブロックサイズ比(min_alloc_size)が小さい場合、そのデータは、実際のディスク位置下降非同期後、RocksDBに書き込まれたデータおよびメタデータをマージなります。不十分プレスセクション(3)処理された場合には、新しいブロックが書き込みのサイズよりも大きい場合、それは、(1)処理によって新たに割り当てられたブロック、書き込み、すなわちの一体部分、分割されています。
書き込み処理BlueStoreの基本的なアウトライン以上。私はそれが二重の問題をログファイルストアを解決するためのものであるかを見ることができます。
まず、何のLinuxファイルシステムが存在しない、とジャーナルの問題の余分なジャーナリングはありません。その後、書き込みのほとんどが新しい場所に書かれていますが、上書きされず、彼らは、ログを使用する必要はありませんのでされ、書き込みはまだ、二回ディスクからのデータ、及び、その後はRocksDBトランザクションのコミットはありませんが、もはや必要とされていることを初めて発生データがログに含まれています。最後に、送信小オーバーライドログに組み込まれ、完成したら、ユーザに戻り、データは、(一般的な技術であるログに小さなデータ)を実際の位置の後に非同期的に移動、大上書きは片部に分割されます追記専用モードでの治療は、それがログの必要性をバイパスします。この時点で、それは自然と通常の治療となります。
BlueFSアーキテクチャ
RocksDBのショートや仕事にファイルシステムを必要とし、特にRocksDBをサポートするために、目的のためにできるだけ単純に設計するBlueFS。BlueFSはPOSIXインターフェイスをサポートしていません。全体的に、それは次の特性があります。
(1)ディレクトリ構造、BlueFSフラットディレクトリ構造だけでは、何階層関係ツリーはありません。RocksDBはdb.wal /、DB /、db.slow /ファイルを配置します。これらのファイルは、NVMRAM上/ db.wal例えば、異なるハードドライブに取り付けることができ、SSDの熱データを含むDB / SST、ディスク上db.slow /。
(2)データがBlueFSのみ(追加のみ)追加のサポート、オーバーライドをサポートしていない、用語を書かれています。ブロック割り当て約1MBの粗粒度、。定期的なガベージコレクションプロセスは、無駄なスペースであります。
(3)ログに記録されたメタデータの操作は、ログは現在のメタデータを取得するために、各時間マウントリプレイ。メモリ内の生存メタデータ、および、そのようなフリーブロックリストの必要性保存されていないなど、ディスク上に保持されません。ログが多すぎると、それはコンパクトに書き換えられます。
デュアル書き込みの問題を解決するため、データのほとんどは、もはやログに再びそれを書くために必要とされる;ボローRocksDB治療をBlueStoreが2倍以上、なぜあなたはスループット向上させることができ、それがより簡単で、より短い書き込みパスでもファイルストアに比べてお願いしない場合SSDオプティマイザ良いの成熟化を実現したメタデータ、。
概要
BlueStore OSD最大の特徴は、直接、生のディスク・デバイス、およびデバイスに保存されたオブジェクトデータを管理しています。そのような情報は、ストレージ間でファイルやLevelDBの拡張属性である前に、さらに多くのオブジェクトは、KVの属性情報があります。BlueStoreでは、情報はRocksDB間に格納されます。RocksDB自体は、ファイルシステム上で実行するために必要なので、単純なファイルシステム(BlueFS)を開発するために、メタデータストレージRocksDBの必要性を使用するためです。
実装を簡素化するために、すべてのメタデータを管理するRocksDB BlueStoreを使用しながら、ビューの設計と実装点からBlueStore、それは、ユーザモードでファイルシステムとして理解することができます。
全体書き込まれたデータについては、データがディスクのAIO道に直接書き込まれ、その後、二回、実際のディスク書き込みディスクに適用した後、ログファイルストアを書いて最初の回避、メタデータRocksDBデータオブジェクトを更新します。従来のファイルシステムは、独自の内部ログおよびメタデータ管理の仕組みを持っているので、冗長ストレージ占有ログのメタデータを避けながら。
BlueStoreは、実際にはファイル・システム・ユーザーモードを実装しています。そしてシンプルを達成するために、実装を簡素化し、メタデータBlueStore管理のすべてを実装するためにRocksDBを使用しています。
利点:
全体書き込まれたデータの場合、データは二回、実際のディスク書き込みディスクに適用した後、ログファイルストアを書くを回避するために、ディスクのAIOの道に直接書き込まれます。
IOランダム形式の場合、WALは、直接書き込み性能RocksDB KVストアを指示します。