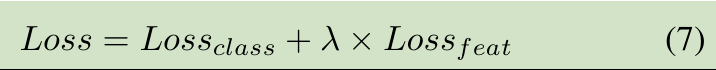原文标题:シーンチェンジ検出のための完全畳み込みシャムメトリックネットワーク:変化を測定するために学びます
論文リンク:http://arxiv.org/abs/1810.09111
抽象
シェーディング、影、および異なるカメラビューと、ノイズやセマンティック変更の変化の測定が困難で変化に起因するノイズの難しさのシーンによって、シーンチェンジ検出が絡み合っています。図の直接比較で最も直感的、特性差の観点から。変更と機能の距離を増加させない変更からの損失を低減するために、比較機能を使用し、また、発生する問題を解決するための観点で大きな変化の損失の閾値比較を提案しました。出典:https://github.com/gmayday1997/ChangeDet
前書き
最先端の方法は、実質的にFCN、検出結果に最良の決定境界を学習することによって検出された変化に基づいて、FCNモデルをベースとしています。ノイズとエッジセマンティック変化を区別するために、一つの可能なアプローチは、屈折率変化、大きい値の意味論的変化、発生するノイズの分散の小さい値で測定可能な差異を提供することです。核となるアイデアは増加の間に、クラスの違い、クラスの違いに学習の深さ対策を軽減することです。距離特性の2件の定義済み距離関数評価の特徴抽出:論文は二つの部分を含んでいます。
主な貢献:最初のフレーム構造の様々な問題点を解決するために提案されている、最先端のために、3つ、2つの提案閾値比較損失閾値対照損失(TCL)は有意な変化点を克服します。第四に、距離メトリックベースのFCNは、ベースラインに統合されています。
関連作業
ほとんどの従来の方法は、低コスト、貧しい区別を算出有意差画像の閾値画素値に直接によるものです。このような画像配給、変化ベクトル・分析、マルコフランダムフィールド、およびdictionarylearningとして設計機能、マニュアルの方法があります。FCNに基づいた最先端の方法、CDへの境界決定を研究しています。著者の考え方が他の論文に基づいており、この論文の尺度は距離に変更されますが、区別は十分ではありません。変化検出光学aerialimagesための深いシャム畳み込みネットワークこの論文に基づいており、この論文は非常に似ていますが、著者らは様々な問題を解決するためのエンドツーエンドのアプローチことを示唆しています。
提案されたアプローチ
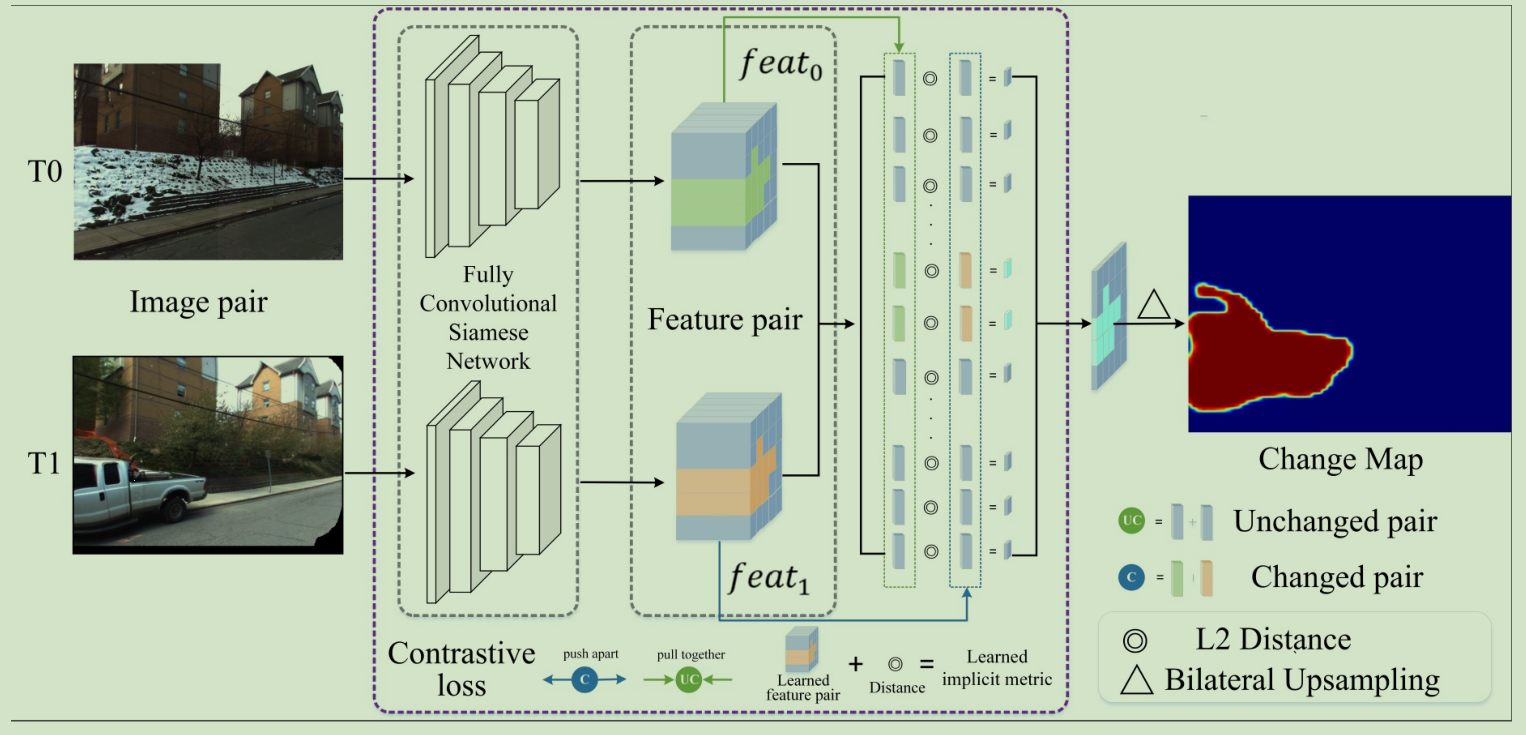
基本フレームとして、次いで、特徴の抽出と、この距離尺度は、統合プロセス暗黙メトリックツインネットワークによって完全畳み込みユークリッド距離または距離のようなメトリックコサイン類似度と呼ばれ、上の特徴を抽出します。コントラスト損失の使用は、一対が大きく距離値を有する変更最適化するために、未変更の対が小さい距離値を有する、コントラスト閾値の使用の損失は重大な視点が変更解きます。
これは、非類似機能の尺度で、類似度として変更されません。特徴記述子と距離メトリック:この関数は、2つの部分からなります。特徴記述子は、実際には、ツイン、バックボーンネットワークを特徴とネットワークを介して取得されるか、またはGooglenet DeepLab缶を使用することができます。距離メトリックは、設計、閾値比較機能喪失の著者、および比較実験を行うには、ユークリッド距離メトリックとコサイン類似度尺度です。
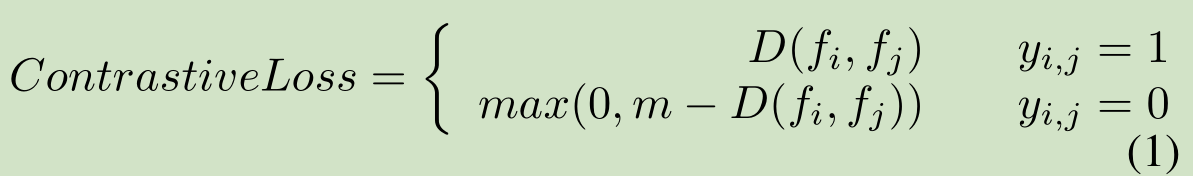
図ユークリッド距離を用いContrastiveLoss、ある\(Y_I、Jが= 1 \)は、この位置には変化がないことを示す\(D(F_iと、F_Jは)\)を表し\(F_iと\)と\(F_J \)固有ベクトルユークリッド距離、\(m個\)が最大距離であります
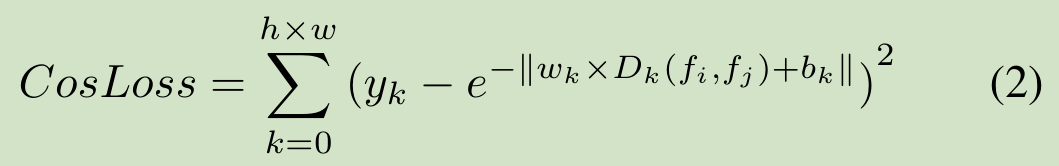
図CosLossは、コサイン類似度を利用して、\(D_kは\)コサイン類似度であり、\(W_k \)と\(\ b_k)ズームとパンのパラメータを学習します
それらの領域に変化が持っているとみなされますが存在しない、一方で起因する角度の変更は、追加情報の活性化につながる大きな視野に、関係ありません:損失関数の上記の欠点を無効と遅い収束があり、著者はそこに矛盾があると信じて一方、それほど訓練の最適化に対応する距離は以下のように低減される場合、原因視点の変化に生成された差分領域に変化がなかった;変更、絡み合っ変化しない情報を変更があります0は、減少傾向があり、この傾向は、私たちが望む結果を生成しません。しかし、重要な問題は、この傾向が0に減少している意味距離特性にすることはできないということで、著者は、TCLの損失を提案しました

この定義は、ゼロに、距離メトリックに対する耐性との距離を最小化する必要がないことを意味します。この損失の有効性を証明するために、著者はCD2014に比較実験を行いました
トレーニング戦略は、多層サイド出力(MLSO)方式を採用し、この方法は図の二点に基づいている:(1)中間傾斜層のバックプロパゲーションに移し消えることがあり、中間層につながる区別する特性能力を有していません。 (2)上部容量は、中間層の特徴を区別する能力に依存しています。
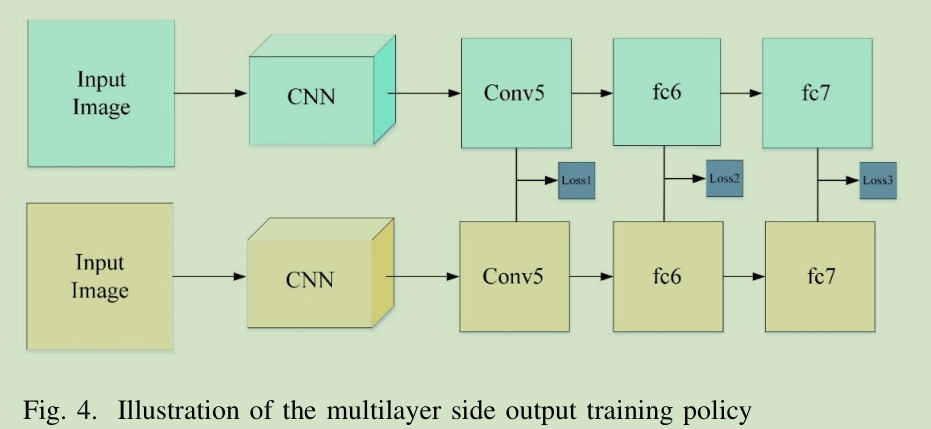
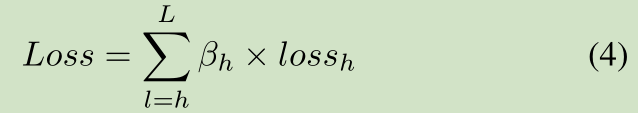
グランドトゥルース需要と算出された特徴距離のそれぞれの出力特性に示す描画層に\(\ loss_h) 、次いで式に従って、最終的な損失を算出\(損失\)、\ (\ beta_h \)であり、対応する重み。異なる層は、最終的な予測結果を出力異なる信頼度閾値を、使用する予測段階では、個々の層を平均することによって得られます。
実験と議論
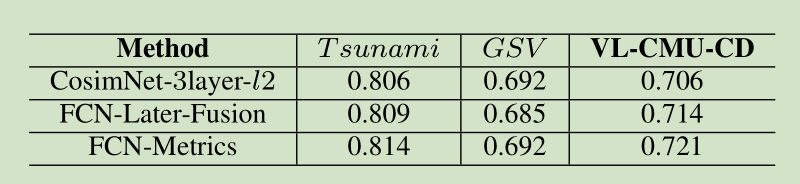
データ収集:VL-CMU-CDデータセット PCD2015データセット CDnetデータセット CDnet ON評価

1.MLSOトレーニング戦略は、本当に効果を高めることができ、ユークリッド距離効果コサイン類似度よりも2パフォーマンスが向上
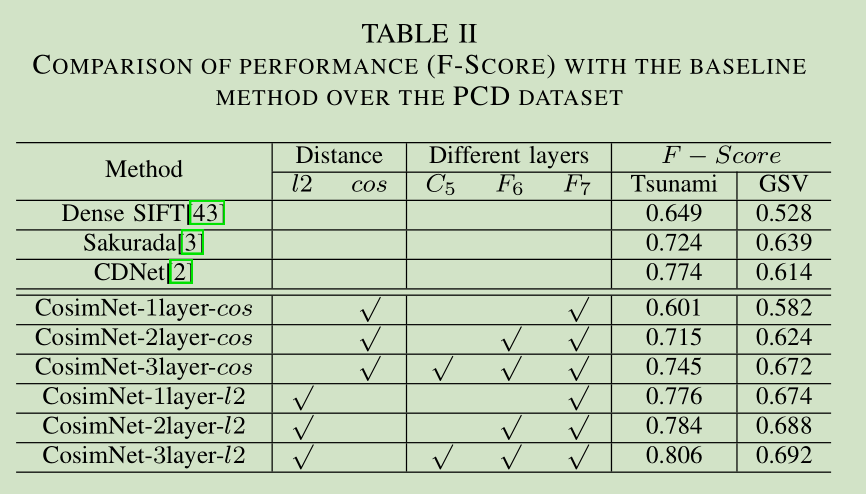
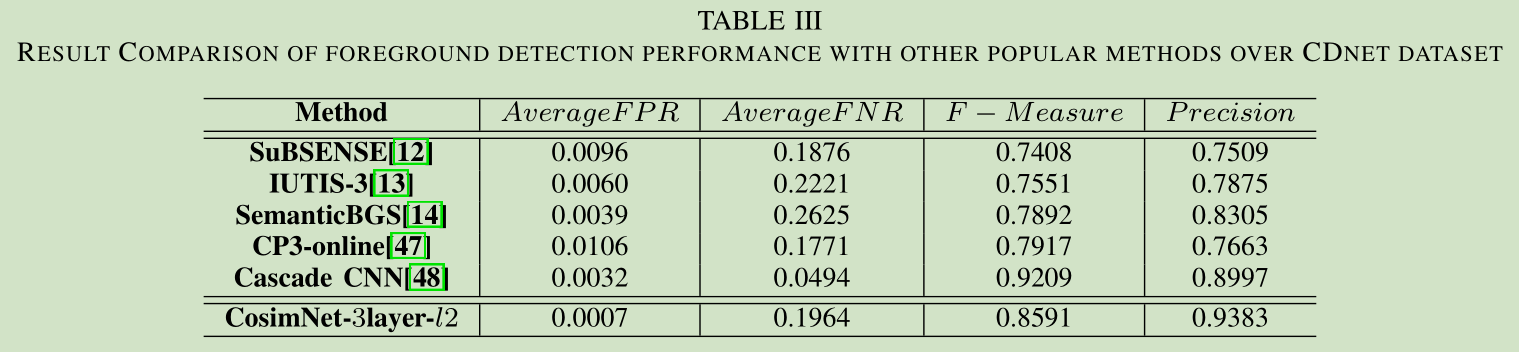
データの第三のセットを比較すると、著者は競争力を達成する方法を示すが、指標の不十分な数があります。一つは、変更セマンティックタスクにある程度の分割方法を用いて、最先端の方法です。私の理解では、セマンティック分割方法は、前景と背景を区別するのが得意なので、ちょうど実際には、ネットワークは変化がない最後のブロックエリアに知られないことがあり、私たちに必要なフォアグラウンドのゴールでセマンティックセグメンテーションを分割するが、分割訓練することができるということですターゲットを移動させ、従って、視点の変化による影響を受けません。一方、著者の方法は、実際の画像差分の方法であり、精度の点で必然的な意味論的分割方法と一定の隙間があり、セマンティックセグメンテーション自体は、問題のピクセル・レベルの分類です。
討論
我々は3つの問題を議論:(1)ネットワークモデルは、大規模な堅牢なの視点を変更することが提案されていますか?(2)場合はモデルの性能は、しきい値の影響を受けやすいのですか?(3)損失の方法を学習し、コントラスト強化策の使用は、本当に多くの機能を持っている能力を区別するために学ぶのか?
最初の質問については、小規模および大規模な視野角の視点を変更します。TCL損失関数の使用、\(スレッド= 0 \)はコントラストの損失、0.1最良であります
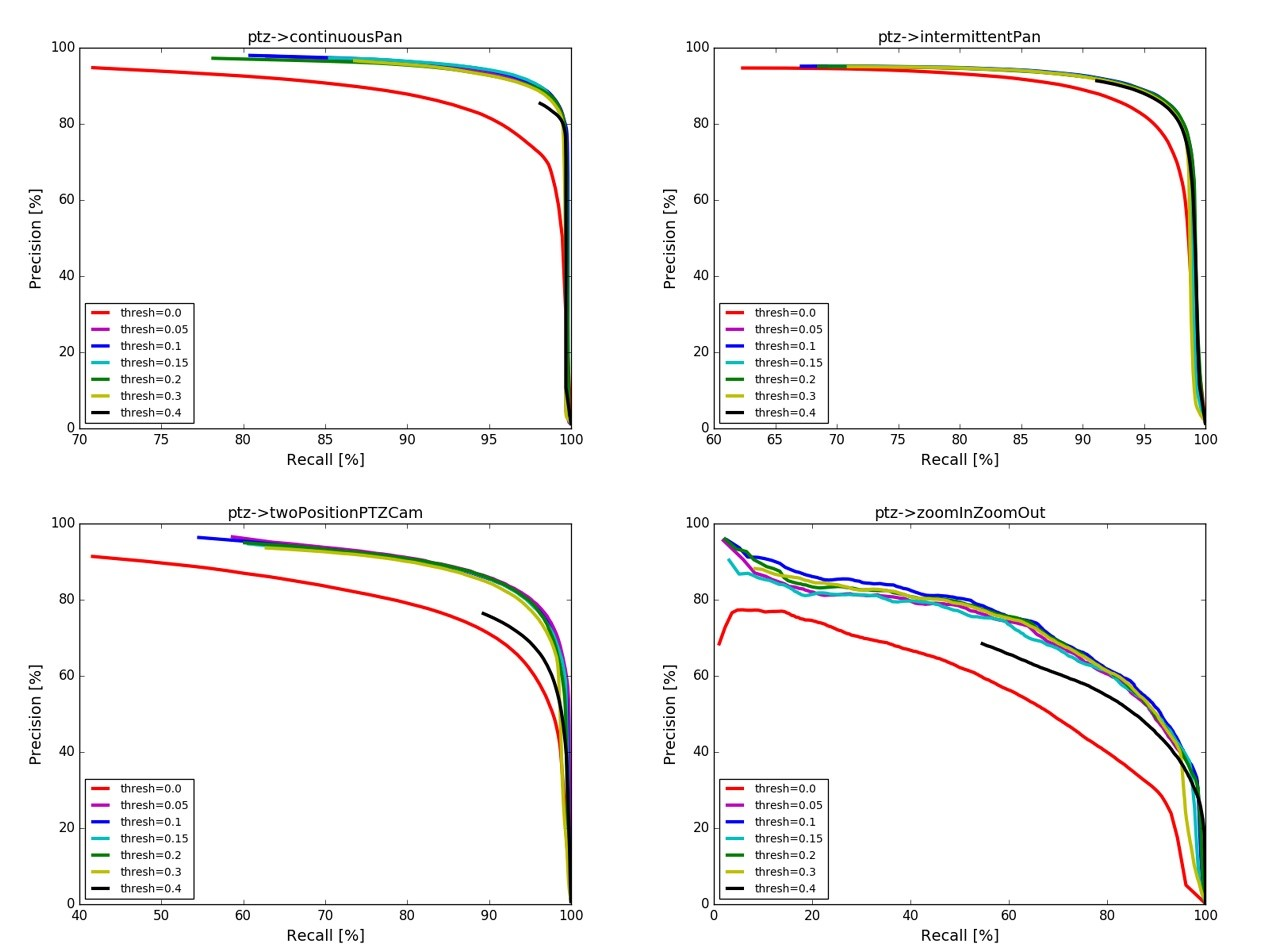
2番目の質問のために、上記のモデルは既に二乗平均値RMSコントラストを用いて比較した異なる距離関数のために、変化の見込みを最大にするために、コントラストと背景の変化を必要とする、感受性の閾値を知って、それは需要の特性であるべきです画像の距離の後に乗平均値

結果は、ユークリッド距離によって生成された画像は、大きなコントラスト比を有し、そして背景のユークリッド距離の変化とを区別することがよりできることを示している。セマンティック情報、図形に由来する強力な機能を区別するための強力な能力を持つ深い豊富な機能を良好
クロスエントロピー損失用いた第3の質問、FCNを用いた学習のコントラスト方法の損失の尺度については、\(Loss_class \)およびコントラスト損失\(Loss_featを\) 、結果は、小リフトがあることを示し