あなたがたBeanFactoryをリフレッシュし、前述のAbstractRefreshableApplicationContext、システムで定義された豆をロードするloadBeanDefinitionsメソッドを呼び出して、次のようにローディングプロセスBean定義を説明します。
A. XML定義
以下の方法を達成するために、XML設定AbstractXmlApplicationContextをロードすることによって実現しました。
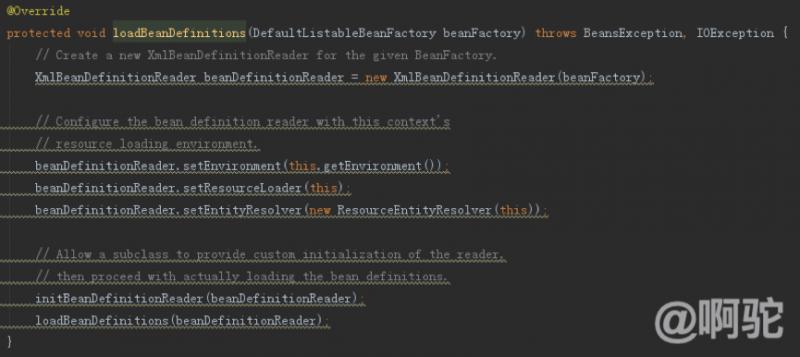
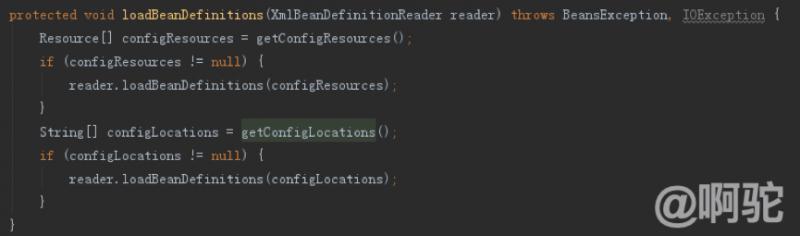
主にそれが環境オブジェクト(特定のプロセスであってもよい)、等を設定した後、XmlBeanDefinitionReader解像度を呼び出すXmlBeanDefinitionReaderオブジェクトをインスタンス化します。直接トラックに、以下のようになります。
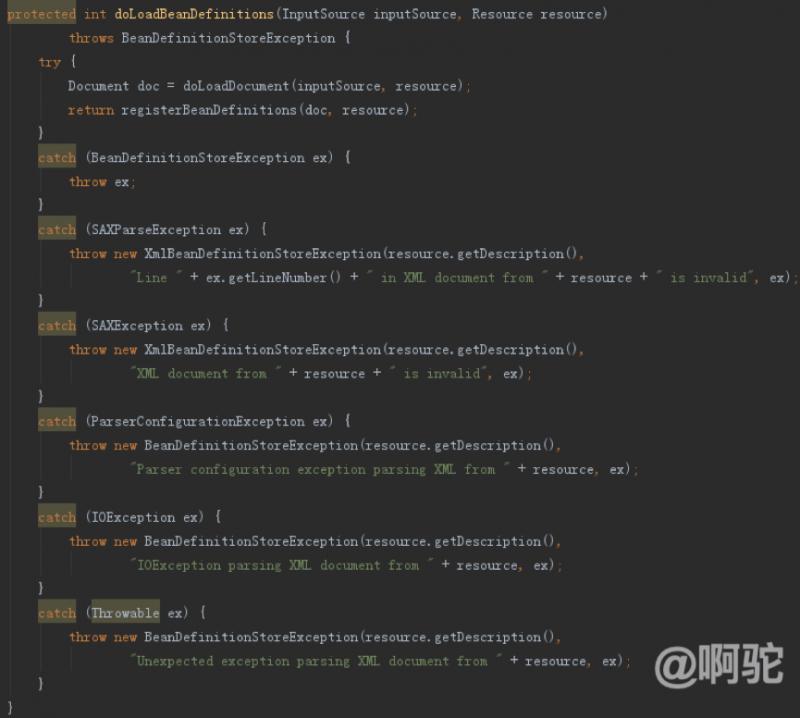
InputSourceのパラメータは、XML構成ファイル、リソースファイルに記載された構成であり、構成ファイルが場所を記述し、クラスパス・ローダーには、構成ファイルをロードするために使用されます。doLoadDocument方法は、主負荷指定された設定ファイルは比較的単純であり、組み込みのXML解析DocumentオブジェクトのXML DOMノードを解析するためにJDKを返します。
次のように、ルックregisterBeanDefinitions方法をフォーカス:

最終的にBeanDefinitonDocumentReaderに委託方法は、豆を解決するために行われます。これに先立ち、関連する一連のオブジェクトを初期化します。含みます:
BeanDefinitionDocumentReaderとしてインターフェイスのDefaultBeanDefinitionDocumentReader実装を使用します
XmlReaderContext種々の関連オブジェクトを作成すると、そのようなオブジェクトのリソース、ReaderEventListenerイベントリスナー、XmlBeanDefinitionReaderとNamespaceHandlerResolver名前空間パーサを記述するリソースとして、ために使用される解決プロセスを保持するために使用されます。どのDefaultNamespaceHandlerResolver、カスタムXMLフォーマットの解析を完了したクラスを計画の焦点である、後でについて説明します。
最初の関連オブジェクト次のように処理されるDefaultBeanDefinitionDocumentReaderに委託解像度処理後、クラスの焦点は、BeanDefinitionParserDelegateオブジェクトを初期化し、このメソッドを呼び出す前に、parseBeanDefinitions方法であって:
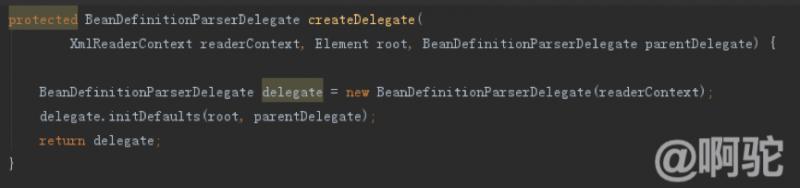
そして、デリゲートオブジェクトは、parseBeanDefinitionsメソッドに渡されます。BeanDefinitionParserDelegateは主に名前空間を提供http://www.springframework.org/schema/beansするXMLファイルの解析処理の(以下、豆スペースと略記します)。この名前空間は、それぞれ、4個の主要なXMLタグを定義しbeans、bean、importとaliasし、これらのタグに対応する属性は、名前空間、次の例については、基本的な豆を定義します。
上記の後に初期化BeanDefinitionParserDelegateは、最初のXML解析することに留意すべきである<beans>:を含む、ラベルにデフォルトのプロパティをdefault-lazy-init、default-merge、default-autowire、default-dependency-check、default-autowire-candidates、default-init-methodおよびdefault-destroy-methodこれらのグローバルプロパティ。
方法以下のparseBeanBefinitoinsを見て:
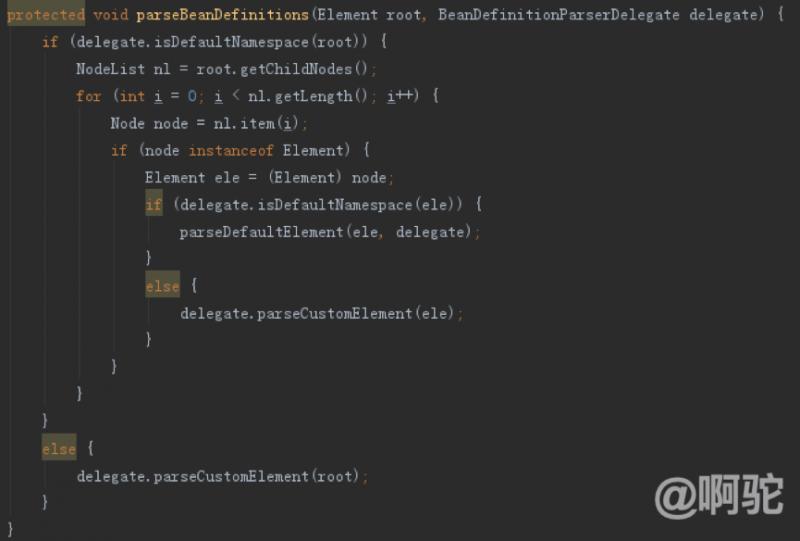
現在のノードの方法は、デフォルトの名前空間とデフォルト名前空間は、上述した豆空間をいい、ここでカスタムの名前空間、に決定される名前空間に属します。メソッドparseDefaultElementデフォルトの名前空間の取り扱いや処理方法parseClustomElementカスタム名前空間:デフォルトの名前空間の場合は、1つの決意名前空間DOM各子ノードによって1は、子ノードの2つの方法に、委任を決定しています。
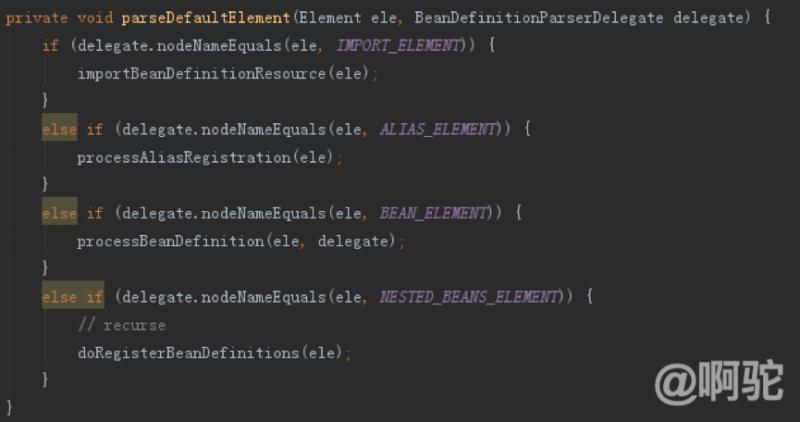
parseDefautlElement方法は、規定された空間豆が処理された各ラベルのために、前述しました:
- 輸入ラベルを解析すると、リソースの属性が設定ファイルを指定して、ファイルをロードするためにBean定義を解析読み込みます。
- エイリアスタグの読み取りタグ名とエイリアス属性の解析、BeanRegistryはキャッシュに追加しました。
豆のラベルを解析するとき、直接、プロセスを処理するためにBeanDefinitionParserDelegateに委託:
1)のbeanNameとしてid属性の値を取得
別名としてname属性の値を取得2)、属性値を複数に設定することができ、又は、文字切り出しは、Beanの別名として使用され、IDの値がnullの場合、名前が空でない場合、最初名前値の値idとして
一意3)エイリアスとのbeanNameをチェック
4)解析ビーン他の構成は、オブジェクトがGenericBeanDefinitionを生成します
5)のbeanNameが空の場合、割り当てます
ステップのために
3.d、プロセスは次のとおりです。1)クラス属性の値を取得
2)親プロパティ値を取得します。
3)初期例GenericBeanDefinition
4)解析ノードビーンプロパティは、BeanDefinitionに提供され
scopeあってabstract、lazy-init、autowired、dependency-check、autowire-candidate、primary、init-method、destroy-method、factory-method、、factory-bean5)が設けられ豆記述の値を取得し、記述子ノードを解析
子ノードの6)分析メタリスト、アクセスキー、値追加のメタデータ情報値
7)分析ルックアップ方式の子ノードリスト取得名、噴射情報の豆値設定方法
8)分析交換法子ノードリストには、情報取得方法は、動的プロキシの値を設定する必要があります
パラメータ情報の値を取得するように構成された子ノードの9)分析コンストラクタ、引数リスト、
子ノードの10)分析プロパティリストには、情報の属性値を取得し、
子ノードの11)分析修飾子リスト、値のセットを取得します
構成上に豆を解析した後、子ノードは、コンテンツを変更する飾る方法NamespaceHandler、ビーン定義を使用して構成された他の名前空間を処理し、このセクションは、以下を使用し、背面に一緒に話します。
- 豆のラベルを解析する際には、再帰的に処理されます
上記のように、主にBean定義を解決するために使用されるデフォルトの名前空間は、上記のプロセスを経て、定義された豆の解析が完了している、それはコンテキストを保存するために、インスタンスオブジェクトを登録します
名前が示すように、この方法は主にXMLタグのカスタム名前空間を処理するために使用される、それは次のようにコンテンツの方法のために、春のXML構成プロセスを拡張するための手段として使用することができますここでparseClustomElement方法であって、
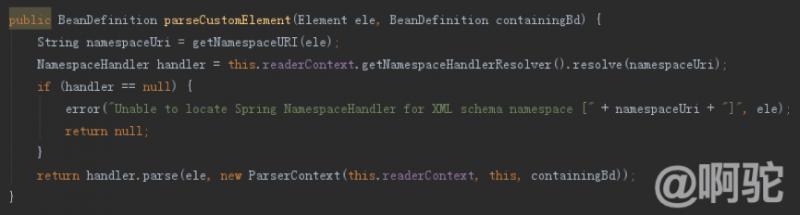
主NamespaceHandlerResolverに委託し、対応するノードに見ることによって処理ハンドラの解析メソッドを呼び出し、ハンドラの名前空間に対応します。
上述したように、NamespaceHandlerResolverを用いDefaultNamespaceHandlerResolver、以下に実装追跡方法の解決として:
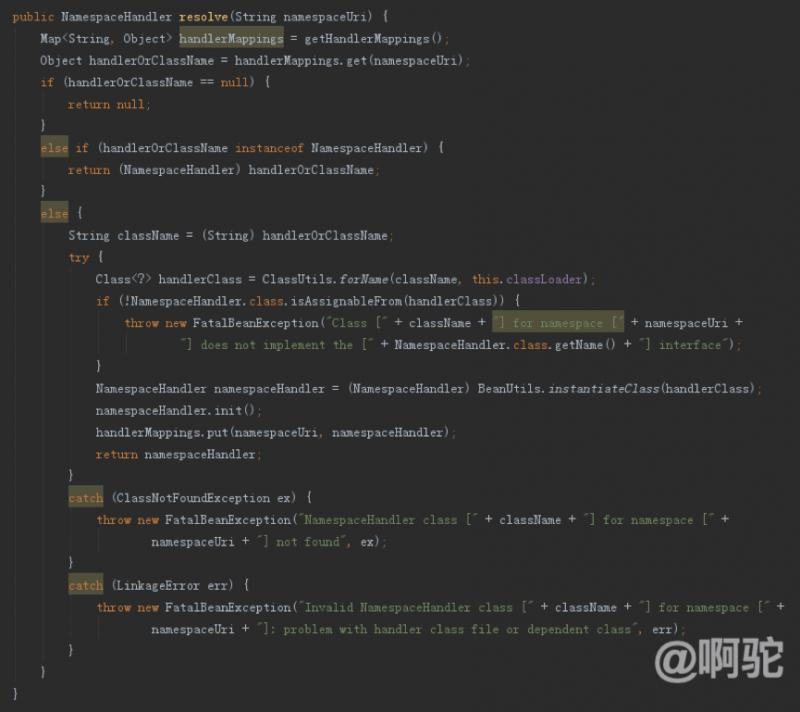
プロセスは以下のとおりです。
利用可能な治療ハンドラリストへのアクセス、XML名前空間値のマップキーは、オブジェクトのか、Handlerオブジェクトの代わりに春ハンドラの種類を対応させることができるように、結果を返しますが前に電話をかけたかどうかに応じて、インスタンス化されます
Handlerオブジェクトのための手段は、直接返す場合
それは非初期化を示す、Stringオブジェクトである場合は、初期化して、地図に戻るには、クラス、およびinitメソッドを初期化します
処理リスト取得ハンドラの最初のステップ(1)のために、スプリングのクラスパスは、すべての内容を読み取るために、META-INF spring.handlersに位置するすべてのコンフィギュレーション・ファイルをスキャンし、マップを返します。

春・コンテキストモジュール用として提供しspring.handlersたファイルを、モジュールは、カスタム名前空間のラベルのサポートを提供します。以下は、カスタム名前空間の例です。
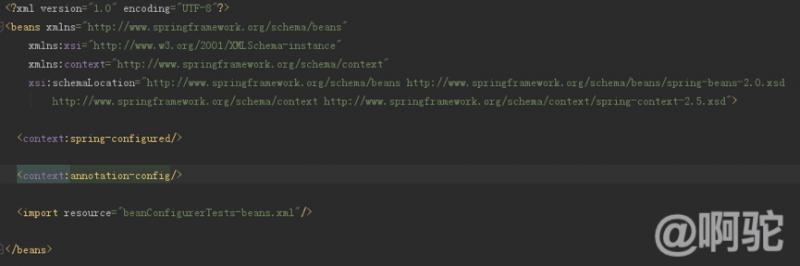
コンテキストの導入の主なスペースspring-configuredタグやannotation-configラベル。
これまでのところ、それは下の豆解析XML構成を導入しました。
第二に、コンフィギュレーションノート
次のようにここに注釈をロードするために必要な構成は、方法春豆ローディングプロセスで注釈します:
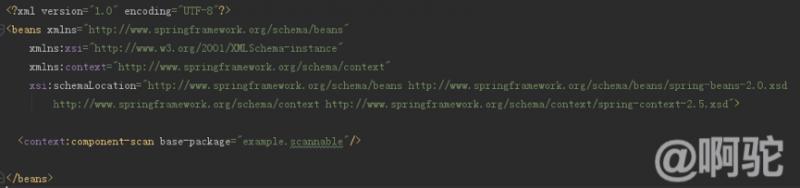
前述の概要は、component-scanのようにhttp://www.springframework.org/schema/context名前空間タグ、処理対象がspring.handlersスプリングコンテキスト・ファイル・モジュールで定義され、以下のように、それは、クラスorg.springframework.context.config.ContextNamespaceHandlerに相当します。
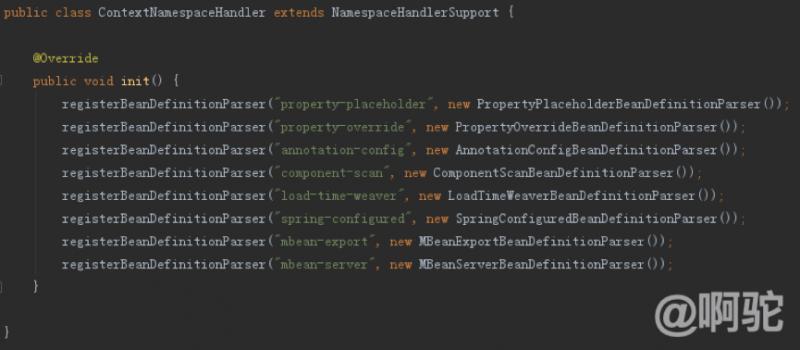
次のようにクラスは、コンポーネント・スキャンがComponentScanBeanDefinitionParserによって処理され、知っているかもしれない見ます:

メインプロセスは以下のとおりです。
取得
base-packageプロパティ値はbasePackageに割り当てられましたbasePackageのプレースホルダの内容を交換してください
係る,; \ T \ nパッケージパスの複数を得るために、basePackage区切って分割
コンポーネント・スキャンの構成を解析するコンテンツ、オブジェクトがClassPathBeanDefinitionScannerを返します。
1)分析を使用 - デフォルト・フィルタのパラメータを提供しました
2)分析リソースパターンパラメータセット
3)分析パラメータ名・発電機セット
4)解析はスコープレゾルバ、スコーププロキシパラメータを配置しました
5)解析が提供され
include-filter、exclude-filterそして他のパラメータ、オブジェクトClassPathBeanDefinitionScanner再初期化デフォルトorg.springframework.stereotype。コンポーネント、javax.annotation.ManagedBeanおよびいくつかの注釈を増加するときjavax.inject.Namedクラスを満たすために、登録して、コンテキストに戻ります、スキャンを実行するClassPathBeanDefinitionScanner doScanメソッドを呼び出します
分析注釈設定パラメータ、注釈のシリーズは自動的に定義されたコンテキスト内(デフォルトは真である)真後処理クラス解析のために登録されている場合
、本明細書にDIRは、ステップ(5)及び(6)のステップを参照してフォーカス
最初の(5)実行スキャンが、横断される(3)ステップは、各パスのすべてのパスを返し、我々は次のようにすべての適格ビーンこのパスを返すClassPathScanningCandidateComponentProvider親クラスfindCandidateComponentsを呼び出します。
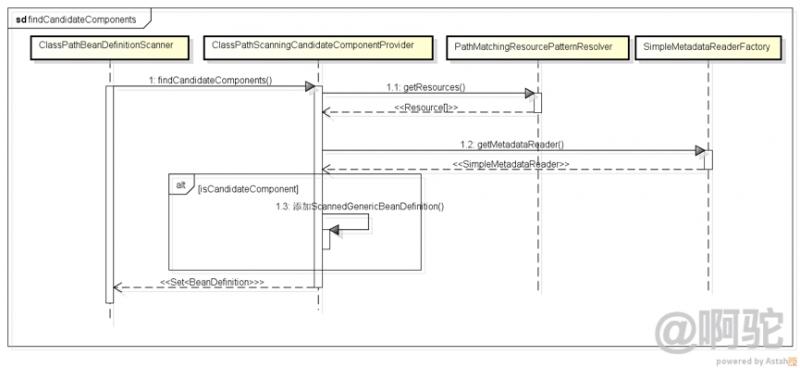
ClassPathScanningCandidateComponentProviderが指定したパスのすべて、資源のそれぞれのリソース[]オブジェクトのパッケージを見つけるだろう、SimpleMetadataReaderFactoryは、情報分析のために、各SimpleMetadataReader Resouceオブジェクトクラスの新しいクラスファクトリオブジェクトを使用することに留意すべきですSimpleMetadataReader初期化は、オブジェクトの分析動作の時に実行され、結果は、インターフェース等が全て含まれている属性情報に含まれるか否かを、クラス名を含む前者のクラスを定義するための情報を格納し、データ及びAnnotationMetadata ClassMetadataデータとして格納されます注釈情報。SimpleMetadataReaderオブジェクトを取得した後、クラスかどうかを判断しますcomponent-scanner定義include-filterとexclude-filterコンテンツがデフォルトで含まノートに定義されている@Componentと他のオブジェクトなので、デフォルトではすべてが持っているロードされます@Componentノートとすべてが持っている@Componentメタアノテーションの注釈(例えば@Service、)@Repositoryクラスを。彼らは要件を満たしている場合には、ScannedGenericBeanDefinitionオブジェクトをパッケージ化し、それがインターフェイスとしてクラスをチェックしませんし、内部の非静的クラスに依存することはできませんの種類は、彼らが会う場合は、返されるリストに追加します。
上記findCandidateComponents方法を実行した後、これを含むのbeanNameは、内部使用のために、次に基本的な性質の上方BeanDefinitionう解析方法にprocessCommonDefinitionAnnotationsのAnnotationConfigUtils方法復帰を呼び出し、注釈セットが割り当てられ@Lazy、@Primary、@DependsOn、@Roleそして、@Description。この手順の完了後豆が既にない場合、それはコンテキストに追加され、存在するか否かを判定する。
次のように(6)ステップのコードがあります:
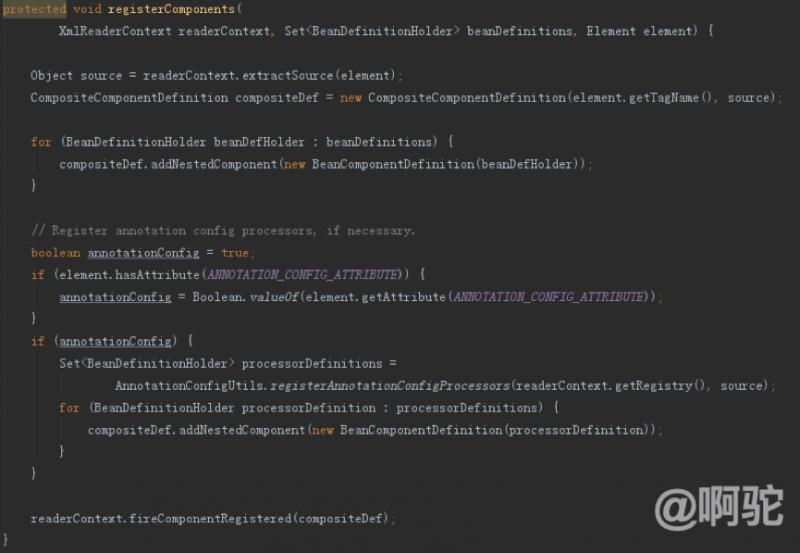
後半のキーは、registerAnnotationConfigProcessorsのAnnotationConfigUtilsメソッドを呼び出しますが、この方法であって、コンテキストを解決するために後処理クラス定義のためのアノテーションのシリーズを追加します。
ConfigurationClassPostProcessorプロセッサ(BeanDefinitionRegistryPostProcessor)を追加し、追加
@Configuration対応するBean org.springframework.context.annotation.internalConfigurationAnnotationProcessorに機能をAutowiredAnnotationBeanPostProcessorプロセッサ(SmartInstantiationAwareBeanPostProcessor、MergedBeanDefinitionPostProcessor)を追加し、追加し
@Autowired、@ValueBeanに対応する機能をorg.springframework.context.annotation.internalAutowiredAnnotationProcessor(SmartInstantiationAwareBeanPostProcessor、MergedBeanDefinitionPostProcessor)RequiredAnnotationBeanPostProcessorプロセッサを追加し、追加
@Required対応するBean org.springframework.context.annotation.internalRequiredAnnotationProcessorに機能を(InstantiationAwareBeanPostProcessor、DestructionAwareBeanPostProcessor、MergedBeanDefinitionPostProcessor、BeanPostProcessor CommonAnnotationBeanPostProcessorプロセッサを追加 ) を添加し
@PostConstruct、@PreDestroy関数は、Bean org.springframework.context.annotation.internalCommonAnnotationProcessorに対応(InstantiationAwareBeanPostProcessor、DestructionAwareBeanPostProcessor、MergedBeanDefinitionPostProcessor)をPersistenceAnnotationBeanPostProcessorプロセッサを追加し、追加し
@PersistenceUnit、@PersistenceContext豆org.springframework.context.annotation.internalPersistenceAnnotationProcessorに対応する機能をEventListenerMethodProcessorを追加し、追加
@EventListener対応するBean org.springframework.context.event.internalEventListenerProcessorに機能をDefaultEventListenerFactoryを追加し、Beanはorg.springframework.context.event.internalEventListenerFactoryに対応します
豆を添加する前に、上記のそれぞれは、第一の増加があった場合、変更するが定義されているかどうかを決定するには、処理機能に対応する適切な豆、変更を加えることによって可能です。
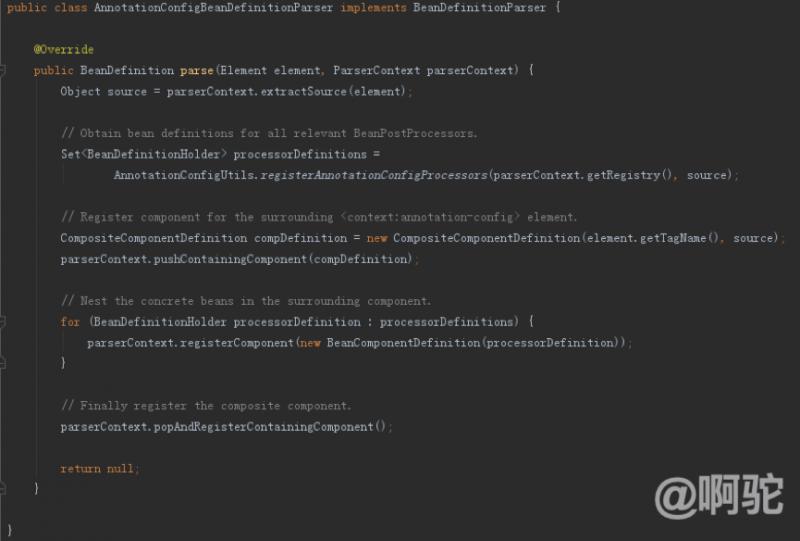
PS:(6)さらに注釈後処理方法は、実際には、注釈-CONFIGラベルアプローチの主な機能です。注釈-config設定方法は、上記のクラスのAnnotationConfigBeanDefinitionParserから知られている、次のように実際にこのような方法の内側に、我々は、注釈機能を完了するために、特定のコードをregisterAnnotationConfigProcessorsのAnnotationConfigUtilsを呼び出します。
第三に、コールバックインタフェース
上記に接続開始前のコンテンツとばね組み合わせは、我々は以下の配列コールバックインターフェースを得ます

DestructionAwareBeanPostProcessor MergedBeanDefinitionPostProcessor他のインターフェイスがインターフェイスから継承InstantiationAwareBeanPostProcessorは、インターフェースがMergedBeanDefinitionPostProcessor BeanPostrProcessorから継承するため、最初に説明した順序に従ってソートオーバーラップに基づいて実施しました。

個人公開番号:ああラクダ