我々はすべて知っているように、サードパーティのPythonモジュールがある限り、これらのモジュールの巧みなアプリケーションは、さまざまなタスクを完了することとして、データを収集し、その後のPythonスクリプトの品質データの収集を使用するために開始する前に、標的部位の存在を必要とします。ウェブは、大量のHTTP要求のステータスコードを取得し、使用のPython pycurlモジュール、DNS解決時間、接続を確立するための時間、送信の終了の合計時間、パケット・サイズ・パラメータのダウンロード、HTTPヘッダサイズ、平均ダウンロード速度を検出するために必要。これらのパラメータからどのようにWebサービスの品質を理解し、運用を最適化することができます。取得したデータは、ここで使用するExcelスプレッドシートに書かれているアイデアを実現し、xlsxwriteのPythonモジュールです内のファイルに取得したデータを保存するために、その後、Excelの表を作成することで、データがテーブルに書き込まれた後、描画されますチャート、というように、ファイル内のデータが追加されます、Excelの表が完全にカバーされます作成した後に、当然のことながら、Excelのスプレッドシートモジュールを作成し、多くなり、それは手の込んだことはありません。
準備を書き込む前にPythonスクリプト:
- ダウンロード pycurlモジュールを、単にインストールするためにダブルクリックします。
- xlsxwriterは、環境変数が設定され、ここで注意することは、PIPを使用してインストールするコマンド。
pycurlによる1は、直接インストールダウンロードされ、ここに書いていない、それは比較的簡単です。
図2に示すように、取付xlsxwriterモジュール(インターネットに接続する必要があるかもしれません)
次のように3、スクリプトデータの収集は、以下のとおりです。
# _._ coding:utf-8 _._
import os,sys
import pycurl
import xlsxwriter
URL="www.baidu.com" #探测目标的url,需要探测哪个目标,这里改哪个即可
c = pycurl.Curl() #创建一个curl对象
c.setopt(pycurl.URL, URL) #定义请求的url常量
c.setopt(pycurl.CONNECTTIMEOUT, 10) #定义请求连接的等待时间
c.setopt(pycurl.TIMEOUT, 10) #定义请求超时时间
c.setopt(pycurl.NOPROGRESS, 1) #屏蔽下载进度条
c.setopt(pycurl.FORBID_REUSE, 1) #完成交互后强制断开连接,不重用
c.setopt(pycurl.MAXREDIRS, 1) #指定HTTP重定向的最大数为1
c.setopt(pycurl.DNS_CACHE_TIMEOUT, 30)
#创建一个文件对象,以’wb’方式打开,用来存储返回的http头部及页面内容
indexfile = open(os.path.dirname(os.path.realpath(__file__))+"/content.txt","wb")
c.setopt(pycurl.WRITEHEADER, indexfile) #将返回的http头部定向到indexfile文件
c.setopt(pycurl.WRITEDATA, indexfile) #将返回的html内容定向到indexfile文件
c.perform()
NAMELOOKUP_TIME = c.getinfo(c.NAMELOOKUP_TIME) #获取DNS解析时间
CONNECT_TIME = c.getinfo(c.CONNECT_TIME) #获取建立连接时间
TOTAL_TIME = c.getinfo(c.TOTAL_TIME) #获取传输的总时间
HTTP_CODE = c.getinfo(c.HTTP_CODE) #获取HTTP状态码
SIZE_DOWNLOAD = c.getinfo(c.SIZE_DOWNLOAD) #获取下载数据包大小
HEADER_SIZE = c.getinfo(c.HEADER_SIZE) #获取HTTP头部大小
SPEED_DOWNLOAD=c.getinfo(c.SPEED_DOWNLOAD) #获取平均下载速度
print u"HTTP状态码: %s" %(HTTP_CODE) #输出状态码
print u"DNS解析时间: %.2f ms" %(NAMELOOKUP_TIME*1000) #输出DNS解析时间
print u"建立连接时间: %.2f ms" %(CONNECT_TIME*1000) #输出建立连接时间
print u"传输结束总时间: %.2f ms" %(TOTAL_TIME*1000) #输出传输结束总时间
print u"下载数据包大小: %d bytes/s" %(SIZE_DOWNLOAD) #输出下载数据包大小
print u"HTTP头部大小: %d byte" %(HEADER_SIZE) #输出HTTP头部大小
print u"平均下载速度: %d bytes/s" %(SPEED_DOWNLOAD) #输出平均下载速度
indexfile.close() #关闭文件
c.close() #关闭curl对象
f = file('chart.txt','a') #打开一个chart.txt文件,以追加的方式
f.write(str(HTTP_CODE)+','+str(NAMELOOKUP_TIME*1000)+','+str(CONNECT_TIME*1000)+','+str(TOTAL_TIME*1000)+','+str(SIZE_DOWNLOAD/1024)+','+str(HEADER_SIZE)+','+str(SPEED_DOWNLOAD/1024)+'\n') #将上面输出的结果写入到chart.txt文件
f.close() #关闭chart.txt文件
workbook = xlsxwriter.Workbook('chart.xlsx') #创建一个chart.xlsx的excel文件
worksheet = workbook.add_worksheet() #创建一个工作表对象,默认为Sheet1
chart = workbook.add_chart({'type': 'column'}) #创建一个图表对象
title = [URL , u' HTTP状态码',u' DNS解析时间',u' 建立连接时间',u' 传输结束时间',u' 下载数据包大小',u' HTTP头部大小',u' 平均下载速度'] #定义数据表头列表
format=workbook.add_format() #定义format格式对象
format.set_border(1) #定义format对象单元格边框加粗(1像素)的格式
format_title=workbook.add_format() #定义format_title格式对象
format_title.set_border(1) #定义format_title对象单元格边框加粗(1像素)的格式
format_title.set_bg_color('#00FF00') #定义format_title对象单元格背景颜色为’#cccccc’
format_title.set_align('center') #定义format_title对象单元格居中对齐的格式
format_title.set_bold() #定义format_title对象单元格内容加粗的格式
worksheet.write_row(0, 0,title,format_title) #将title的内容写入到第一行
f = open('chart.txt','r') #以只读的方式打开chart.txt文件
line = 1 #定义变量line等于1
for i in f: #开启for循环读文件
head = [line] #定义变量head等于line
lineList = i.split(',') #将字符串转化为列表形式
lineList = map(lambda i2:int(float(i2.replace("\n", ''))), lineList) #将列表中的最后\n删除,将小数点后面的数字删除,将浮点型转换成整型
lineList = head + lineList #两个列表相加
worksheet.write_row(line, 0, lineList, format) #将数据写入到execl表格中
line += 1
average = [u'平均值', '=AVERAGE(B2:B' + str((line - 1)) +')', '=AVERAGE(C2:C' + str((line - 1)) +')', '=AVERAGE(D2:D' + str((line - 1)) +')', '=AVERAGE(E2:E' + str((line - 1)) +')', '=AVERAGE(F2:F' + str((line - 1)) +')', '=AVERAGE(G2:G' + str((line - 1)) +')', '=AVERAGE(H2:H' + str((line - 1)) +')'] #求每一列的平均值
worksheet.write_row(line, 0, average, format) #在最后一行数据下面写入平均值
f.close() #关闭文件
def chart_series(cur_row, line): #定义一个函数
chart.add_series({
'categories': '=Sheet1!$B$1:$H$1', #将要输出的参数作为图表数据标签(X轴)
'values': '=Sheet1!$B$'+cur_row+':$H$'+cur_row, #获取B列到H列的数据
'line': {'color': 'black'}, #线条颜色定义为black
'name': '=Sheet1!$A'+ cur_row, #引用业务名称为图例项
})
for row in range(2, line + 1): #从第二行开始到最后一次取文本中的行的数据系列函数调用
chart_series(str(row), line)
chart.set_size({'width':876,'height':287}) #定义图表的宽度及高度
worksheet.insert_chart(line + 2, 0, chart) #在最后一行数据下面的两行处插入图表
workbook.close() #关闭execl文档
4は、スクリプトを実行した後、スクリプトは、スクリプトは、以下の情報が表示されます実行し、TXTテキストファイルですそのうち2つ3つの文書、一つのExcelファイルのディレクトリに生成されます。
5、次のように現在のディレクトリの下に結果のファイル:
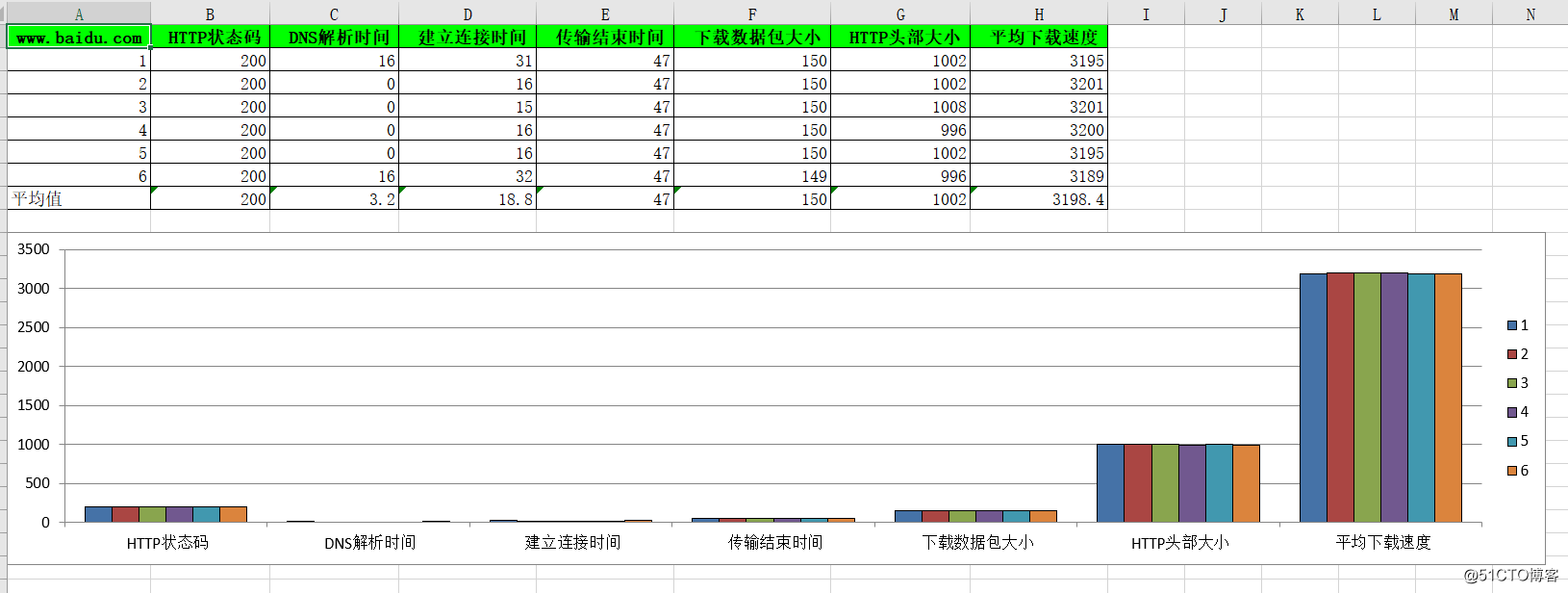
このうち、2つのtxtファイル形式がExcelの基礎を築くことを目的としている、選択的にExcelのデータを参照するために主に、無視することが可能です。Excelでデータを以下のように(次のスクリプト6回の実施結果であり、それが6回プロービングされます):
--------この記事の最後に、これまで、読んでくれてありがとう--------