ディレクトリ
1.web自然とカスタムWebフレームワークフレームワーク
我々は理解することができます:すべてのWebアプリケーションは、基本的にソケットサーバであり、ユーザのブラウザは、お客様のご要望に要求応答に基づいて、ソケットクライアントで、サーバーはhttpプロトコルに従って、対応する応答を行います要求プロトコルが要求、ネットワーク通信などの要求に応えるために、httpプロトコルによるサーバの応答プロトコルを送信し、我々は彼のWebフレームワークを実現することができるようになります。
ソケットの研究を通じて、ソケットは、ネットワーク通信を行うことですので、我々はそのネットワーク通信を知って、私たちは、自分自身を書くことができ、ここでは、ブラウザが要求できるように、Webサーバーを書き、Webフレームワークを実装するために自分自身にソケットに基づいていますそして彼らのサービスページの終了により、ブラウザに私たちが望む効果をレンダリングするためにブラウザを返しました。
test.htmlという名前の、次のようにHTML文書が読み取ります。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="test.css">
<link rel="icon" href="wechat.ico">
<!--直接写在html页面里面的css样式是直接可以在浏览器上显示的-->
<!--<style>-->
<!--h1{-->
<!--background-color: green;-->
<!--color: white;-->
<!--}-->
<!--</style>-->
</head>
<body>
<h1>姑娘,你好,我是Jaden,请问约吗?嘻嘻~~</h1>
<!--直接写在html页面里面的img标签的src属性值如果是别人网站的地址(网络地址)是直接可以在浏览器上显示的-->
<!--<img src="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1550395461724&di=c2b971db12eef5d85aba410d1e2e8568&imgtype=0&src=http%3A%2F%2Fy0.ifengimg.com%2Fifengimcp%2Fpic%2F20140822%2Fd69e0188b714ee789e97_size87_w800_h1227.jpg" alt="">--> <!--如果都是网络地址,那么只要你的电脑有网,就可以看到,不需要自己在后端写对应的读取文件,返回图片文件信息的代码,因为别人的网站就做了这个事情了-->
<img src="meinv.png" alt="" width="100" height="100"> <!--如果你是本地的图片想要返回给页面,你需要对页面上的关于这个图片的请求要自己做出响应,这个src就是来你本地请求这个图片,你只要将图片信息读取出来,返回给页面,页面拿到这个图片的数据,就能够渲染出来了,是不是很简单-->
<!--直接写在html页面里面的js操作是直接可以在浏览器上显示的-->
<!--<script>-->
<!--alert('这是我们第一个网页')-->
<!--</script>-->
<script src="test.js"></script>
</body>
</html>CSSファイルは、名前のtest.cssを、次のとおりです。
h1{
background-color: green;
color: white;
}次のようにJS文書は、名前のtest.jsを読み取ります。
alert('这是我们第一个网页');次に見ることができる、ブラウザの上部にある、絵、名前meinv.jpgが、その後、その後、マイクロチャンネルの公式ウェブサイトを開いて、実際には、画像ファイルをICOファイル、名前のwechat.icoを準備する準備
それを保存するために、
上記書類の準備ができたら、あなたはスペアを維持し、内部のフォルダに、ファイルを新しいプロジェクトをpycharm使用し、これは次のようになります。
2.シンプルなWebフレームワーク
、名前のtest.pyを次のように、Pythonのファイルを作成します。
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
conn,addr = sk.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
#socket是应用层和传输层之间的抽象层,每次都有协议,协议就是消息格式,那么传输层的消息格式我们不用管,因为socket帮我们搞定了,但是应用层的协议还是需要咱们自己遵守的,所以再给浏览器发送消息的时候,如果没有按照应用层的消息格式来写,那么你返回给浏览器的信息,浏览器是没法识别的。而应用层的协议就是我们的HTTP协议,所以我们按照HTTP协议规定的消息格式来给浏览器返回消息就没有问题了,关于HTTP我们会细说,首先看一下直接写conn.send(b'hello')的效果,然后运行代码,通过浏览器来访问一下,然后再看这一句conn.send(b'HTTP/1.1 200 ok \r\n\r\nhello')的效果
#下面这句就是按照http协议来写的
# conn.send(b'HTTP/1.1 200 ok \r\n\r\nhello')
#上面这句还可以分成下面两句来写
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(b'hello')ブラウザから送信されるブラウザ要求に関する視点はしてみましょう:
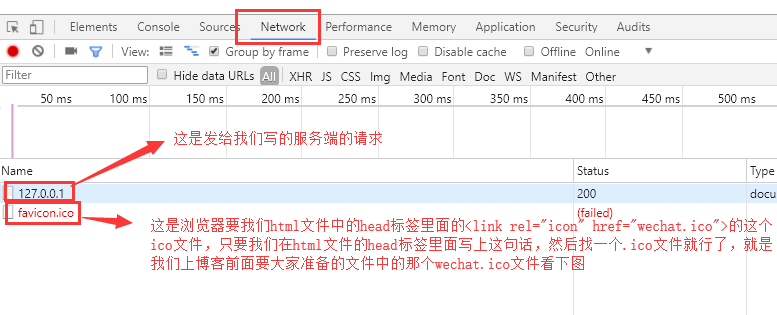
我々は、我々はこの127.0.0.1を見るために開くことがポイント、ブラウザにHTMLファイルを返す方法を記述する必要はありませんので、一時的にここでそれを無視しないでください。

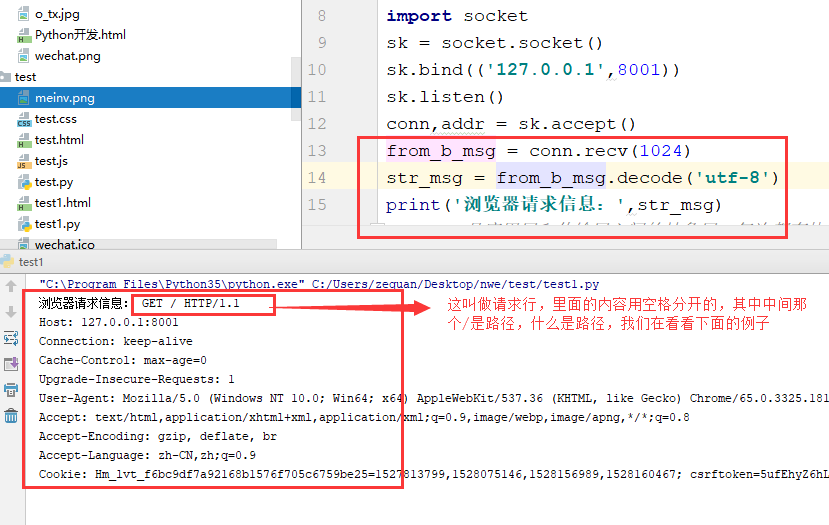
私たちは、Pythonのファイルブラウザが要求が終わっ有効な情報を送信し、印刷しました:
このURLに入力した後、私たちのコードを再起動します。
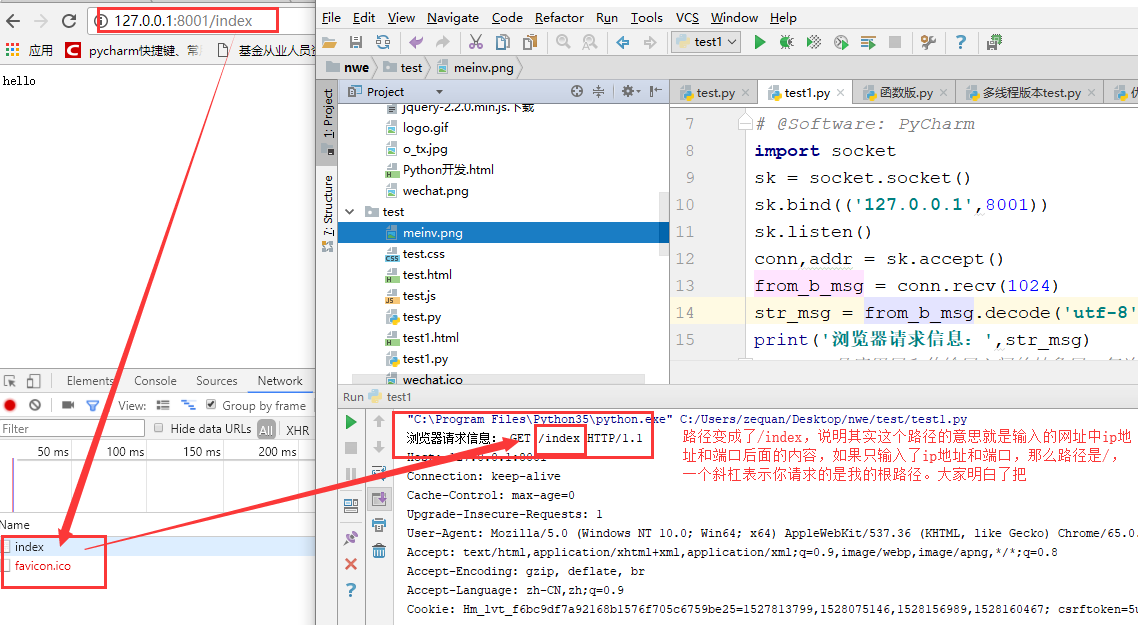
このURLに入力した後、私たちのコードを再起動します。

ブラウザが私にメッセージの束を送信し、我々はブラウザに戻る(応答)メッセージは、それはhttpプロトコル、これらが指定されたメッセージを書き込むためのフォーマットに従わなければならないので、我々はhttpプロトコルについて学ばなければならない、として続行します当社のWebフレームワークを向上させます:
HTTPプロトコルます。https://www.cnblogs.com/clschao/articles/9230431.html
3.戻りウェブフレームワークのHTMLファイル
まず、次のようにtest.htmlという名前の、htmlファイルを記述します。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title><link rel="stylesheet" href="test.css">
<!--直接写在html页面里面的css样式是直接可以在浏览器上显示的-->
<style>
h1{
background-color: green;
color: white;
}
</style>
</head>
<body>
<h1>姑娘,你好,我是Jaden,请问约吗?嘻嘻~~</h1>
<!--直接写在html页面里面的img标签的src属性值如果是别人网站的地址(网络地址)是直接可以在浏览器上显示的-->
<img src="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1550395461724&di=c2b971db12eef5d85aba410d1e2e8568&imgtype=0&src=http%3A%2F%2Fy0.ifengimg.com%2Fifengimcp%2Fpic%2F20140822%2Fd69e0188b714ee789e97_size87_w800_h1227.jpg" alt="">
<!--如果都是网络地址,那么只要你的电脑有网,就可以看到,不需要自己在后端写对应的读取文件,返回图片文件信息的代码,因为别人的网站就做了这个事情了-->
<!--直接写在html页面里面的js操作是直接可以在浏览器上显示的-->
<script>
alert('这是我们第一个网页')
</script>
</body>
</html>次のように私たちのPythonコード、サーバプログラムを準備し、文書には、ファイル名がtest.pyで、読み取ります。
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
conn,addr = sk.accept()
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
print('浏览器请求信息:',str_msg)
# conn.send(b'HTTP/1.1 200 ok \r\ncontent-type:text/html;charset=utf-8;\r\n')
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
with open('test1.html','rb') as f:
f_data = f.read()
conn.send(f_data)、そこに実際には非常に良い結果、CSSやJSコードを見るためにページのURLを入力します。
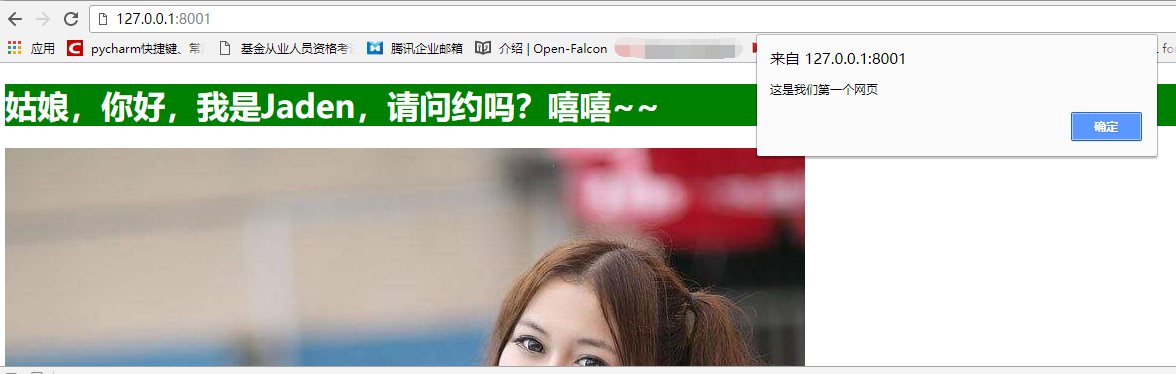
しかし、それがある準備JSとCSS、事前に私たちは、ああ内側に、当社のCSSやJSは基本的にローカルファイルに書かれていることを知っている、だけでなく、私たちの基本的な絵が何をどのように、私たち自身のローカルああ、私たちは私たちの上になります画像ファイルの準備ができているの終わり.ICO、我々はWebフレームワークのアップグレード版に来て、実際には、CSS、JS、画像やその他の文書は、サイト内の静的ファイルと呼ばれます。
我々は書かCSSやJSや写真だけでなく、HTMLファイルを下回っている私たちのHTMLページに.ICOファイルを指示した場合に最初に我々は、1つの効果を見て
次のように読み込むという名前のtest.htmlという、:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<link rel="stylesheet" href="test.css">
<!--加上下面这句,那么我们看浏览器调试窗口中的那个network里面就没有那个favicon.ico的请求了,其实这就是页面title标签文字左边的那个页面图标,但是这个文件是我们自己本地的,所以我们需要在后端代码里面将这个文件数据读取出来返回给前端-->
<link rel="icon" href="wechat.ico">
<!--直接写在html页面里面的css样式是直接可以在浏览器上显示的-->
<!--<style>-->
<!--h1{-->
<!--background-color: green;-->
<!--color: white;-->
<!--}-->
<!--</style>-->
</head>
<body>
<h1>姑娘,你好,我是Jaden,请问约吗?嘻嘻~~</h1>
<!--直接写在html页面里面的img标签的src属性值如果是别人网站的地址(网络地址)是直接可以在浏览器上显示的-->
<!--<img src="https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1550395461724&di=c2b971db12eef5d85aba410d1e2e8568&imgtype=0&src=http%3A%2F%2Fy0.ifengimg.com%2Fifengimcp%2Fpic%2F20140822%2Fd69e0188b714ee789e97_size87_w800_h1227.jpg" alt="">--> <!--如果都是网络地址,那么只要你的电脑有网,就可以看到,不需要自己在后端写对应的读取文件,返回图片文件信息的代码,因为别人的网站就做了这个事情了-->
<img src="meinv.png" alt="" width="100" height="100"> <!--如果你是本地的图片想要返回给页面,你需要对页面上的关于这个图片的请求要自己做出响应,这个src就是来你本地请求这个图片,你只要将图片信息读取出来,返回给页面,页面拿到这个图片的数据,就能够渲染出来了,是不是很简单-->
<!--直接写在html页面里面的js操作是直接可以在浏览器上显示的-->
<!--<script>-->
<!--alert('这是我们第一个网页')-->
<!--</script>-->
<script src="test.js"></script>
</body>
</html>我々はまたの効果を見て、前のpythonプログラムを使用します。
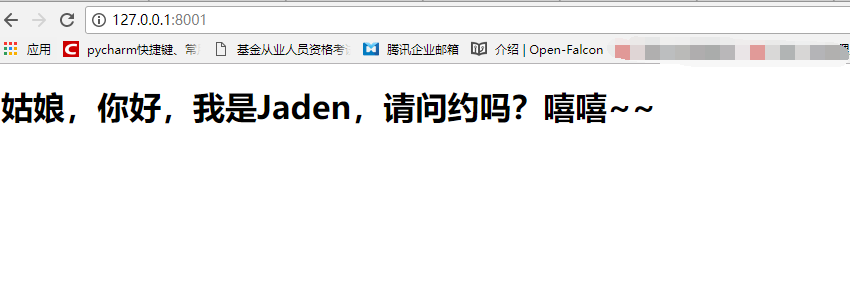
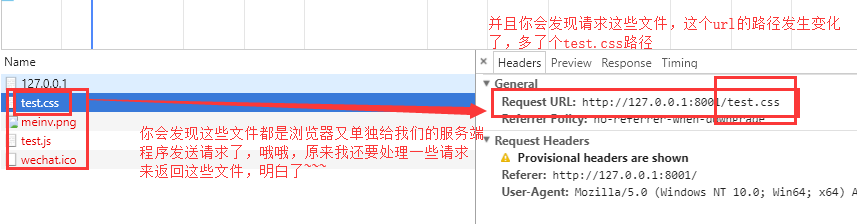
発見JSとCSSの効果は出ていない、と私たちは、ネットワークのデバッグブラウザのウィンドウを見て
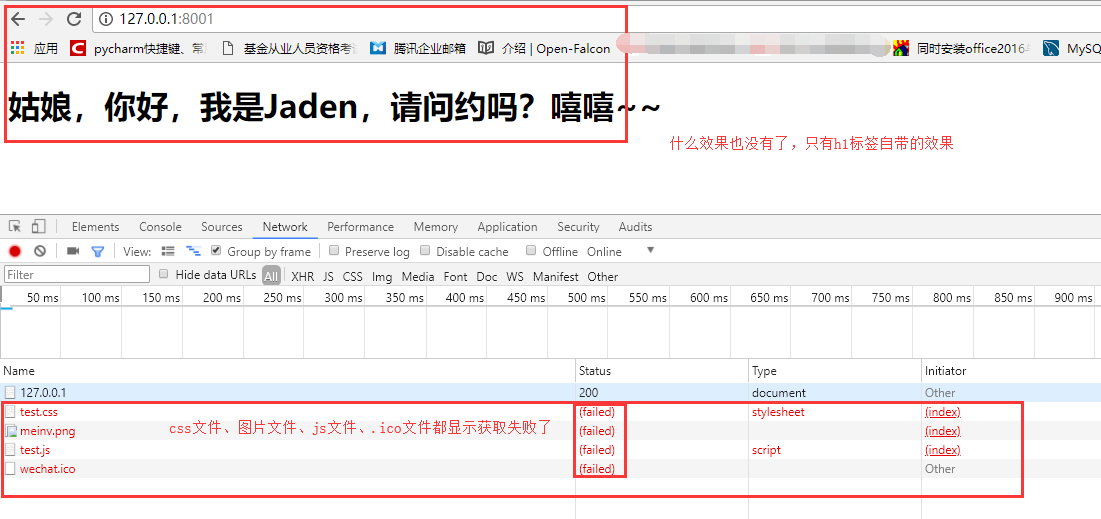
ダウンでは、内部ネットワークtest.css内のファイルをクリックすると、要求が何であるかを参照してください。
私たちは、直接ブラウザでページを保存する場合があり、単にページ、私たちは、あなたがこのページのHTML、CSSを見つけるだろう、ページとして保存右クリックする必要がありますし、ローカルディレクトリに保存しますJS、写真や他のファイルが一緒に保存されているが、私が見る、少しブログの庭のホーム・ページを保存し、htmlファイルとフォルダです。

私たちは、あるものを見るために、そのフォルダ内のブログパークを命じました。
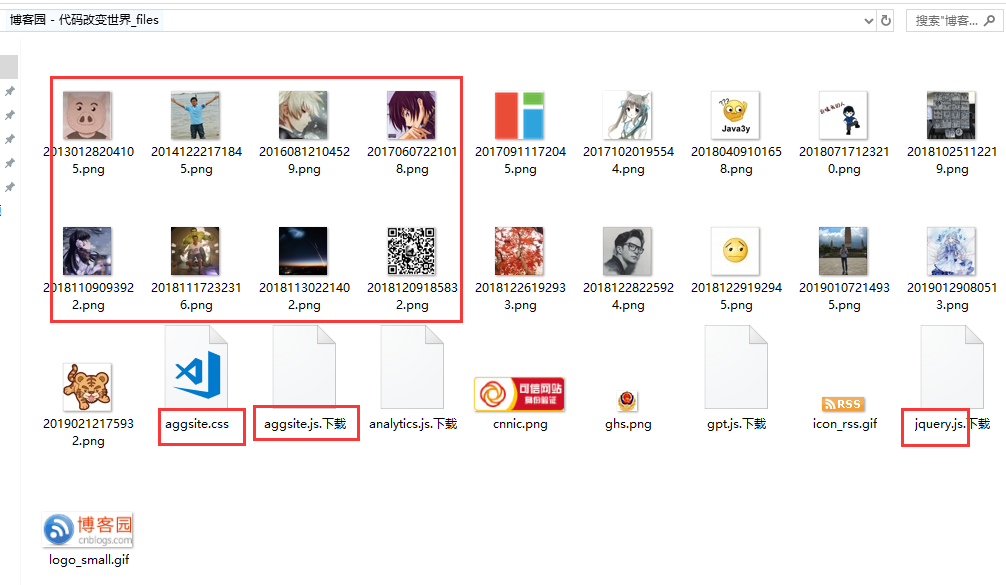
発見JS、CSSだけでなく、保存されているものの写真を、何の説明ファイルはブラウザ自体、ああ、ブラウザに送信されたCSS、JS、写真や他のファイルが必要になります元のHTMLページ上に存在することを示しますCSSファイルは、リンクタグのhref属性で、その上にあり、これらは別のブラウザ要求を超える静的ファイルであり、実際にラベルの関係プロパティがあります:
、JSファイルには、スクリプトタグのsrc属性です:画像ファイルがありますimgタグのsrc属性: リンクタグの属性です.ICOファイル:
実際には、これらのプロパティは、個々の要求に対応するファイルデータを取るために内側に対応するプロパティの値を所有するために、ページのロード時になり、私たちは内側に書かれた値があればそれは必要なファイルを見つけるために、我々は相対パスを記述する場合、それは私たち自身のウェブサイト+ファイル名を意志、独自のローカルパスにパスを来る、独自のローカルパスなので、私達はちょうどに必要これらの要求は応答して何かを、それをブラウザに対応し、対応するファイルデータ!そして、我々の以前のビューを介して、リクエストパスブラウザのURLを発見するために、私たちはよく、我々はそれが異なるパスに異なるファイルを返す与えた、このような要求を持っていない、それが何であるか静的ファイルを知っている、
リンクタグの属性です.ICOファイル:
実際には、これらのプロパティは、個々の要求に対応するファイルデータを取るために内側に対応するプロパティの値を所有するために、ページのロード時になり、私たちは内側に書かれた値があればそれは必要なファイルを見つけるために、我々は相対パスを記述する場合、それは私たち自身のウェブサイト+ファイル名を意志、独自のローカルパスにパスを来る、独自のローカルパスなので、私達はちょうどに必要これらの要求は応答して何かを、それをブラウザに対応し、対応するファイルデータ!そして、我々の以前のビューを介して、リクエストパスブラウザのURLを発見するために、私たちはよく、我々はそれが異なるパスに異なるファイルを返す与えた、このような要求を持っていない、それが何であるか静的ファイルを知っている、
非常に良いです!のは、それを試してみましょう!
高度なWebフレームワークの静的ファイルに4.戻ります
次のようにHTMLファイルまたは第二のWebフレームワークの内部を使用するには、私たちは、その上に私たちのサーバー・プログラム、同じtest.pyファイルのいくつかを記述します。
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
#首先浏览器相当于给我们发送了多个请求,一个是请求我们的html文件,而我们的html文件里面的引入文件的标签又给我们这个网站发送了请求静态文件的请求,所以我们要将建立连接的过程循环起来,才能接受多个请求,没毛病
while 1:
conn,addr = sk.accept()
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
#通过http协议我们知道,浏览器请求的时候,有一个请求内容的路径,通过对请求信息的分析,这个路径我们在请求的所有请求信息中可以提炼出来,下面的path就是我们提炼出来的路径
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
#由于整个页面需要html、css、js、图片等一系列的文件,所以我们都需要给人家浏览器发送过去,浏览器才能有这些文件,才能很好的渲染你的页面
#根据不同的路径来返回响应的内容
if path == '/': #返回html文件
print(from_b_msg)
with open('test.html','rb') as f:
# with open('Python开发.html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
elif path == '/meinv.png': #返回图片
with open('meinv.png','rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
elif path == '/test.css': #返回css文件
with open('test.css','rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
elif path == '/wechat.ico':#返回页面的ico图标
with open('wechat.ico','rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
elif path == '/test.js': #返回js文件
with open('test.js','rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
#注意:上面每一个请求处理完之后,都有一个conn.close()是因为,HTTP协议是短链接的,一次请求对应一次响应,这个请求就结束了,所以我们需要写上close,不然浏览器自己断了,你自己写的服务端没有断,就会出问题。結果を確認するために、当社のサーバーにブラウザでアクセスした後、当社のPYファイルを実行し、そして:
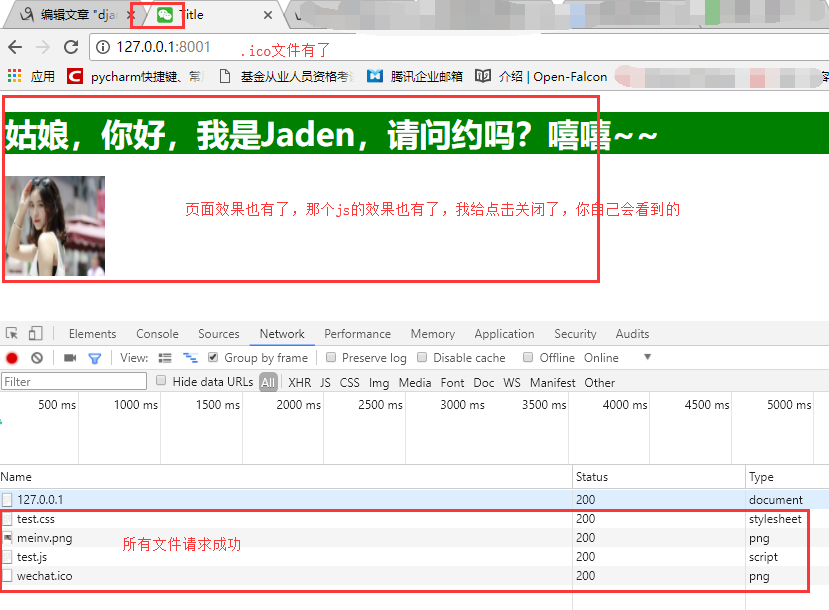
高度なWebフレームワークの機能バージョン
我々は上記使用されるHTMLファイルやその他の静的ファイルか
次のようにPythonのコードは次のとおりです。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2019/2/17 14:06
# @Author : wuchao
# @Site :
# @File : test.py
# @Software: PyCharm
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
#处理页面请求的函数
def func1(conn):
with open('test.html', 'rb') as f:
# with open('Python开发.html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
#处理页面img标签src属性值是本地路径的时候的请求
def func2(conn):
with open('meinv.png', 'rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
#处理页面link( <link rel="stylesheet" href="test.css">)标签href属性值是本地路径的时候的请求
def func3(conn):
with open('test.css', 'rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
#处理页面link(<link rel="icon" href="wechat.ico">)标签href属性值是本地路径的时候的请求
def func4(conn):
with open('wechat.ico', 'rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
#处理页面script(<script src="test.js"></script>)标签src属性值是本地路径的时候的请求
def func5(conn):
with open('test.js', 'rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
while 1:
conn,addr = sk.accept()
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(from_b_msg)
if path == '/':
func1(conn)
elif path == '/meinv.png':
func2(conn)
elif path == '/test.css':
func3(conn)
elif path == '/wechat.ico':
func4(conn)
elif path == '/test.js':
func5(conn)
6.より高度なバージョン(マルチスレッド)Webフレームワーク
上記ブラウザ、そして誰も並行処理、htmlファイルと静的ファイルまたは直接私たちの番組コンテンツ、とにかく、htmlファイルと静的ファイルの同時アプリケーション
次のようにPythonのコードは次のとおりです。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# @Time : 2019/2/17 14:06
# @Author : wuchao
# @Site :
# @File : test.py
# @Software: PyCharm
import socket
from threading import Thread
#注意一点,不开多线程完全是可以搞定的,在这里只是教大家要有并发编程的思想,所以我使用了多线程
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
def func1(conn):
with open('test.html', 'rb') as f:
# with open('Python开发.html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
def func2(conn):
with open('meinv.png', 'rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
def func3(conn):
with open('test.css', 'rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
def func4(conn):
with open('wechat.ico', 'rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
def func5(conn):
with open('test.js', 'rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
while 1:
conn,addr = sk.accept()
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
print(from_b_msg)
if path == '/':
# func1(conn)
t = Thread(target=func1,args=(conn,))
t.start()
elif path == '/meinv.png':
# func2(conn)
t = Thread(target=func2, args=(conn,))
t.start()
elif path == '/test.css':
# func3(conn)
t = Thread(target=func3, args=(conn,))
t.start()
elif path == '/wechat.ico':
# func4(conn)
t = Thread(target=func4, args=(conn,))
t.start()
elif path == '/test.js':
# func5(conn)
t = Thread(target=func5, args=(conn,))
t.start()
Webフレームワークの7より多くの高度なバージョン
裁判官が多すぎる場合には、方法は、よりオープンスレッド吐き気は、裁判官の数は、それを簡単にするためにスレッドを作成するために、何度も書いてあれば、また次のとおりです。
import socket
from threading import Thread
sk = socket.socket()
sk.bind(('127.0.0.1',8001))
sk.listen()
def func1(conn):
conn.send(b'HTTP/1.1 200 ok\r\ncontent-type:text/html\r\ncharset:utf-8\r\n\r\n')
with open('test.html', 'rb') as f:
# with open('Python开发.html','rb') as f:
data = f.read()
conn.send(data)
conn.close()
def func2(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('meinv.png', 'rb') as f:
pic_data = f.read()
# conn.send(b'HTTP/1.1 200 ok \r\n\r\n')
conn.send(pic_data)
conn.close()
def func3(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('test.css', 'rb') as f:
css_data = f.read()
conn.send(css_data)
conn.close()
def func4(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('wechat.ico', 'rb') as f:
ico_data = f.read()
conn.send(ico_data)
conn.close()
def func5(conn):
conn.send(b'HTTP/1.1 200 ok\r\n\r\n')
with open('test.js', 'rb') as f:
js_data = f.read()
conn.send(js_data)
conn.close()
#定义一个路径和执行函数的对应关系,不再写一堆的if判断了
l1 = [
('/',func1),
('/meinv.png',func2),
('/test.css',func3),
('/wechat.ico',func4),
('/test.js',func5),
]
#遍历路径和函数的对应关系列表,并开多线程高效的去执行路径对应的函数,
def fun(path,conn):
for i in l1:
if i[0] == path:
t = Thread(target=i[1],args=(conn,))
t.start()
# else:
# conn.send(b'sorry')
while 1:
conn,addr = sk.accept()
#看完这里面的代码之后,你就可以思考一个问题了,很多人要同时访问你的网站,你在请求这里是不是可以开起并发编程的思想了,多进程+多线程+协程,妥妥的支持高并发,再配合服务器集群,这个网页就支持大量的高并发了,有没有很激动,哈哈,但是咱们写的太low了,而且功能很差,容错能力也很差,当然了,如果你有能力,你现在完全可以自己写web框架了,写一个nb的,如果现在没有这个能力,那么我们就来好好学学别人写好的框架把,首先第一个就是咱们的django框架了,其实就是将这些功能封装起来,并且容错能力强,抗压能力强,总之一个字:吊。
# while 1:
from_b_msg = conn.recv(1024)
str_msg = from_b_msg.decode('utf-8')
path = str_msg.split('\r\n')[0].split(' ')[1]
print('path>>>',path)
# 注意:因为开启的线程很快,可能导致你的文件还没有发送过去,其他文件的请求已经来了,导致你文件信息没有被浏览器正确的认识,所以需要将发送请求行和请求头的部分写道前面的每一个函数里面去,并且防止出现浏览器可能不能识别你的html文件的情况,需要在发送html文件的那个函数里面的发送请求行和请求头的部分加上两个请求头content-type:text/html\r\ncharset:utf-8\r\n
# conn.send(b'HTTP/1.1 200 ok\r\n\r\n') 不这样写了
# conn.send(b'HTTP/1.1 200 ok\r\ncontent-type:text/html\r\ncharset:utf-8\r\n\r\n') 不这样写了
print(from_b_msg)
#执行这个fun函数并将路径和conn管道都作为参数传给他
fun(path,conn)
別のページの異なるパスに記載のリターンのWebフレーム
今、あなたは我々が要求の内容に応じて、別のパスに戻ることができますので、私たちは、ユーザーのアクセス経路に応じて、えー、ああ別のページに戻ることができることを知っていること、それは可能なはず
次の2つを作成したHTMLファイルには、index.htmlを名付け、内側にいくつかのラベルを書き、home.html、その後、別のパスに基づいて別のページに戻り、私はあなたがそれにPythonコードを書くために与えました:
"""
根据URL中不同的路径返回不同的内容
返回独立的HTML页面
"""
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
# 读取index.html页面的内容
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
# 返回字节数据
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
9.リターン動的なWebページフレーム
このページには表示されますが、静的ああしていることができます。ページの内容は、私は、動的Webサイトになりたい、変わりません、動的なウェブサイトは、私たちが注意ああを支払う必要があることを、代わりに動的な効果を持っているページの、動的に変化するデータがあることを意味します。
問題ありません、私は解決策を持っていません。私はこの要求を実現するために文字列置換を使用することにしました。(タイムスタンプは、動的データをシミュレートするために、ここで使用される、またはちょうど私達にPythonのバーコードを与えます)
"""
根据URL中不同的路径返回不同的内容
返回HTML页面
让网页动态起来
"""
import socket
import time
sk = socket.socket()
sk.bind(("127.0.0.1", 8080)) # 绑定IP和端口
sk.listen() # 监听
# 将返回不同的内容部分封装成函数
def index(url):
with open("index.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.time())
s = s.replace("@@oo@@", now) # 在网页中定义好特殊符号,用动态的数据去替换提前定义好的特殊符号
return bytes(s, encoding="utf8")
def home(url):
with open("home.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/index/", index),
("/home/", home),
]
while 1:
# 等待连接
conn, add = sk.accept()
data = conn.recv(8096) # 接收客户端发来的消息
# 从data中取到路径
data = str(data, encoding="utf8") # 把收到的字节类型的数据转换成字符串
# 按\r\n分割
data1 = data.split("\r\n")[0]
url = data1.split()[1] # url是我们从浏览器发过来的消息中分离出的访问路径
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 因为要遵循HTTP协议,所以回复的消息也要加状态行
# 根据不同的路径返回不同内容
func = None # 定义一个保存将要执行的函数名的变量
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
# 返回具体的响应消息
conn.send(response)
conn.close()
8つのフレームハハ、全体のWebフレームワークの原則を理解して噴出したが、我々はフレームワークがまだ低すぎる、およびない十分に強い、などのような多くの良いNBフレームワークを開発したことを書いている今、誰も幸せになるように:Djangoは、フラスコ、トルネードなどは、私たちはパスを分離するためにそれを使用しますが、問題に注意を払う、我々は内部のパスを取得し、私たちが\ r \ nに従っている方法を学び、その後に取得するためのスペースで分割することができますない場合は、その後、httpプロトコル、メッセージ形式に注意を払う必要があります。
次に、我々は書かれて他の人が彼のモジュールを実行するWebフレームワークを見て、このモジュールはwsgirefと呼ばれています
10.wsgirefモジュールバージョンのWebフレームワーク
wsgirefモジュールは、実際にパッケージ全体までの要求メッセージである、あなたは自分自身に対処する必要はありません、それは情報要求がすべてと呼ばれるオブジェクトパッケージになりました要求されます場合は、ユーザーに直接request.path得ることができるようになります要求パス、ユーザーリクエスト(GETまたはPOST)、などの要求に取得することができrequest.method方法は、このモジュールのアップは、我々は、Webフレームワークは、単にああの多くではありません書きます。
サーバーとアプリケーション:PythonのWebプログラムで実際の開発では、一般的には二つの部分に分割されます。
サーバープログラムは、ソケットサーバーパッケージを担当し、リクエストが来ると、各種データをソートを要求しました。
アプリケーションは、特定のロジックを担当しています。その上ジャンゴ、フラスコ、web.pyと:アプリケーションの開発を容易にするために、のような数多くのWebフレームワークがありました。異なるフレームワークは、開発のさまざまな方法を持っていますが、いずれにしても、アプリケーションやサーバープログラムの開発は、ユーザーにサービスを提供するために協力しなければなりません。
このように、サーバプログラムは、異なるフレームの異なるサポートを提供する必要があります。このような混沌とした状況の両方のサーバーやフレームワークのために、良いものではありません。サーバーの場合は、異なるフレームワークの様々なフレームワーク、アプリケーションを開発するために、そのサーバーに対してのみサポートをサポートする必要があります。最も単純なWebアプリケーションでは、ユーザーは、要求を受信したHTMLファイルとリターンから読み込み、最初のHTMLファイルは、既存のHTTPサーバソフトウェアで、良いで保存されています。あなたが動的にHTMLを生成したい場合は、自分自身を達成するためにこれらのステップを配置する必要があります。しかし、HTTPリクエストを受け付け、解析HTTPリクエスト、HTTPレスポンスが送信されクーリーは、私たち自身が、これらの基礎となるコードを記述する場合、それはまだ、ダイナミックHTMLを記述するために開始されていない、生きる、あなたはHTTPの仕様を読み取るために月を過ごす必要があります。
正しいアプローチは、専用サーバー・ソフトウェアによって実現される基本的なコードで、我々は、HTML文書を生成するのPythonに焦点を当てます。私たちは、TCP接続、HTTPリクエストと、元の応答形式なので、そのようなプロトコル・サーバ・ソフトウェアを実装するための統一されたインタフェースの必要性へのアクセスをしたくないので、私たちは、Pythonを使用してWebサービスを書くことに集中しましょう。
このとき、標準化が特に重要になります。私たちは、限り、サーバーがこの標準をサポートしているように、フレームワークはまた、彼らは一緒に使用することができ、この標準をサポートして、標準を設定することができます。標準が決定されると、当事者のそれぞれが実現しています。このように、サーバはより標準的なフレームワークをサポートしてサポートすることができ、フレームワークはまた、より多くの規格をサポートするためにサーバーを使用することができます。
WSGI(Webサーバゲートウェイインターフェース)は、WebアプリケーションやWebサーバプログラムとの間にデカップリング、PythonのWebアプリケーションとウェブサーバプログラムに書き込まれたフォーマットとの間のインターフェースを定義する仕様です。
一般的に使用されるWSGIサーバはGunicorn、uwsgiています。wsgirefと呼ばれるWSGIサーバの独立したPythonの標準ライブラリには、Djangoの開発環境は、このモジュールのサーバーを行うために使用されます。
wsfiref使用
from wsgiref.simple_server import make_server
# wsgiref本身就是个web框架,提供了一些固定的功能(请求和响应信息的封装,不需要我们自己写原生的socket了也不需要咱们自己来完成请求信息的提取了,提取起来很方便)
#函数名字随便起
def application(environ, start_response):
'''
:param environ: 是全部加工好的请求信息,加工成了一个字典,通过字典取值的方式就能拿到很多你想要拿到的信息
:param start_response: 帮你封装响应信息的(响应行和响应头),注意下面的参数
:return:
'''
start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')])
print(environ)
print(environ['PATH_INFO']) #输入地址127.0.0.1:8000,这个打印的是'/',输入的是127.0.0.1:8000/index,打印结果是'/index'
return [b'<h1>Hello, web!</h1>']
#和咱们学的socketserver那个模块很像啊
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
完全なWebプロジェクト、ユーザログイン認証プログラムのために、我々は、テーブル内のデータベースので、最初-mysqlのデータベースに接続し、いくつかのデータを準備する必要があります
mysql> create database db1;
Query OK, 1 row affected (0.00 sec)
mysql> use db1;
Database changed
mysql> create table userinfo(id int primary key auto_increment,username char(20) not null unique,password char(20) not null);
Query OK, 0 rows affected (0.23 sec)
mysql> insert into userinfo(username,password) values('chao','666'),('sb1','222');
Query OK, 2 rows affected (0.03 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from userinfo;
+----+----------+----------+
| id | username | password |
+----+----------+----------+
| 1 | chao | 666 |
| 2 | sb1 | 222 |
+----+----------+----------+
2 rows in set (0.00 sec)
そして、このようなファイルを作成します。
Pythonのファイル名webmodel.py
#创建表,插入数据
def createtable():
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='666',
database='db1',
charset='utf8'
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = '''
-- 创建表
create table userinfo(id int primary key auto_increment,username char(20) not null unique,password char(20) not null);
-- 插入数据
insert into userinfo(username,password) values('chao','666'),('sb1','222');
'''
cursor.execute(sql)
conn.commit()
cursor.close()
conn.close()
webauthのと呼ばれるPythonのファイル
#对用户名和密码进行验证
def auth(username,password):
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123',
database='db1',
charset='utf8'
)
print('userinfo',username,password)
cursor = conn.cursor(pymysql.cursors.DictCursor)
sql = 'select * from userinfo where username=%s and password=%s;'
res = cursor.execute(sql, [username, password])
if res:
return True
else:
return False
ユーザーは、指定したユーザー名とパスワードファイルweb.htmlを入力します
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<!--如果form表单里面的action什么值也没给,默认是往当前页面的url上提交你的数据,所以我们可以自己指定数据的提交路径-->
<!--<form action="http://127.0.0.1:8080/auth/" method="post">-->
<form action="http://127.0.0.1:8080/auth/" method="get">
用户名<input type="text" name="username">
密码 <input type="password" name="password">
<input type="submit">
</form>
<script>
</script>
</body>
</html>
ユーザー認証が成功したジャンプページ、ショーの成功、と呼ばれるwebsuccess.htmlです
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<style>
h1{
color:red;
}
</style>
</head>
<body>
<h1>宝贝儿,恭喜你登陆成功啦</h1>
</body>
</html>
Pythonのサーバコード(メインロジックコード)と呼ばれるweb_python.py
from urllib.parse import parse_qs
from wsgiref.simple_server import make_server
import webauth
def application(environ, start_response):
# start_response('200 OK', [('Content-Type', 'text/html'),('k1','v1')])
# start_response('200 OK', [('Content-Type', 'text/html'),('charset','utf-8')])
start_response('200 OK', [('Content-Type', 'text/html')])
print(environ)
print(environ['PATH_INFO'])
path = environ['PATH_INFO']
#用户获取login页面的请求路径
if path == '/login':
with open('web.html','rb') as f:
data = f.read()
#针对form表单提交的auth路径,进行对应的逻辑处理
elif path == '/auth/':
#登陆认证
#1.获取用户输入的用户名和密码
#2.去数据库做数据的校验,查看用户提交的是否合法
# user_information = environ['']
if environ.get("REQUEST_METHOD") == "POST":
#获取请求体数据的长度,因为提交过来的数据需要用它来提取,注意POST请求和GET请求的获取数据的方式不同
try:
request_body_size = int(environ.get('CONTENT_LENGTH', 0))
except (ValueError):
request_body_size = 0
#POST请求获取数据的方式
request_data = environ['wsgi.input'].read(request_body_size)
print('>>>>>',request_data) # >>>>> b'username=chao&password=123',是个bytes类型数据
print('?????',environ['QUERY_STRING']) #????? 空的,因为post请求只能按照上面这种方式取数据
#parse_qs可以帮我们解析数据
re_data = parse_qs(request_data)
print('拆解后的数据',re_data) #拆解后的数据 {b'password': [b'123'], b'username': [b'chao']} #post请求的返回数据我就不写啦 pass
if environ.get("REQUEST_METHOD") == "GET":
#GET请求获取数据的方式,只能按照这种方式取
print('?????',environ['QUERY_STRING']) #????? username=chao&password=123,是个字符串类型数据
request_data = environ['QUERY_STRING']
# parse_qs可以帮我们解析数据
re_data = parse_qs(request_data)
print('拆解后的数据', re_data) #拆解后的数据 {'password': ['123'], 'username': ['chao']}
username = re_data['username'][0]
password = re_data['password'][0]
print(username,password)
#进行验证:
status = webauth.auth(username,password)
if status:
# 3.将相应内容返回
with open('websuccess.html','rb') as f:
data = f.read()
else:
data = b'auth error'
# 但是不管是post还是get请求都不能直接拿到数据,拿到的数据还需要我们来进行分解提取,所以我们引入urllib模块来帮我们分解
#注意昂,我们如果直接返回中文,没有给浏览器指定编码格式,默认是gbk,所以我们需要gbk来编码一下,浏览器才能识别
# data='登陆成功!'.encode('gbk')
else:
data = b'sorry 404!,not found the page'
return [data]
#和咱们学的socketserver那个模块很像啊
httpd = make_server('127.0.0.1', 8080, application)
print('Serving HTTP on port 8080...')
# 开始监听HTTP请求:
httpd.serve_forever()
下では、効果を見ることができるコードwe_python.pyファイルを実行し、同じディレクトリにファイルを作成します127.0.0.1:8080/loginされる入力するURLに注意し、また、あなたのMySQLデータベースに注意を払うことは問題ではありません
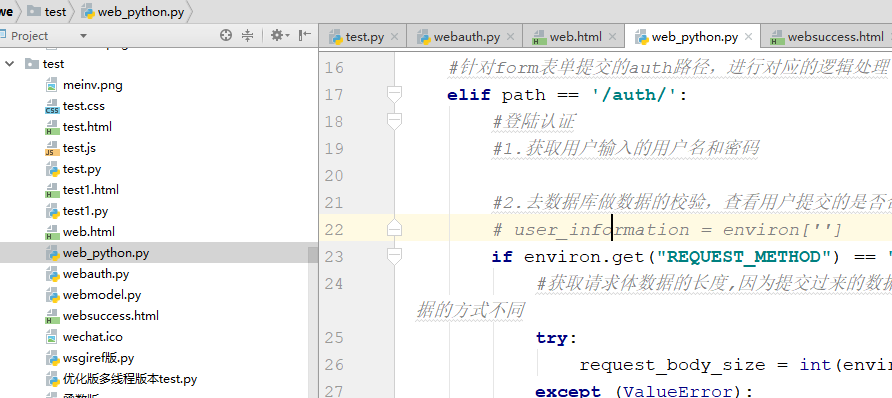
Webフレームワークの11離陸バージョン
我々は、我々は他のファイル内に行くために分割PYファイルに書かれたすべてのコードのためのWebフレームワークの上に置くと、未使用時のパスの要求を配布するには、多くの最適化の恩恵を受けるかどうかを判断するために使用されていますまあ、我々はいくつかのファイルとフォルダに、私たちは見ての利点を最適化するために、いくつかのバージョンを組み合わせました
コードは、ブログに掲載されていないが、私はBaiduのクラウド上に詰め、我々はダウンロードして見ます。https://pan.baidu.com/s/1Ns5QHFpZGusGHuHzrCto3A