図1に示すように、スパークシェルにウィンドウ
2、
ヴァルsqlContext =新しいorg.apache.spark.sql.SQLContext(SC)
3、
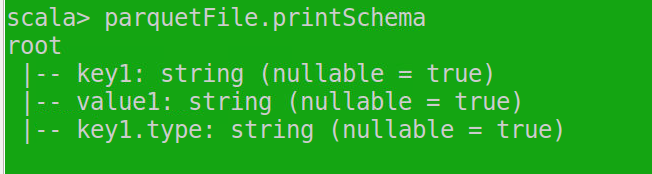
ヴァルparquetFile = sqlContext.parquetFile(" HDFS://cdp/user/az-user/sparkStreamingKafka2HdfsData/part-00000-ff60a7d3-bf91-4717-bd0b-6731a66b9904-c000.snappy.parquet ")
HDFS:// CDPはdefaultFSで次のように、あなたは、書くことはできません。
ヴァルparquetFile2 = sqlContext.parquetFile(" /user/az-user/sparkStreamingKafka2HdfsData/part-00000-ff60a7d3-bf91-4717-bd0b-6731a66b9904-c000.snappy.parquet ")
4、
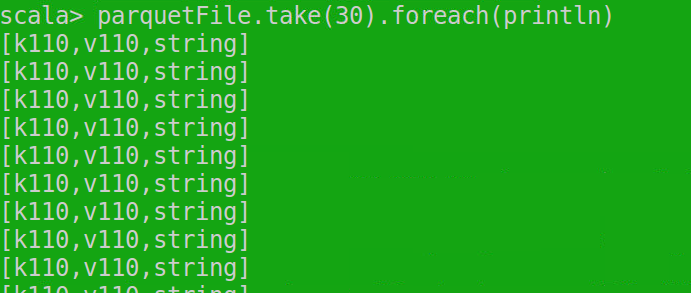
parquetFile.take(30).foreach(のprintln)