テスト、分析、最適化の下でシステムを配置するパフォーマンスの問題のためだけでなく、パフォーマンステストプロセスは、プレスの大部分のため、多くの場合、責任のパフォーマンスのボトルネックのすべての種類を開始するための要求があります。結局のところ、数億のマシンに数千ドルではただの機械プレスの麻痺は、技術の少しでほしいです。
ここでは、ディスクIOの問題、不十分なCPUの問題、メモリの枯渇の問題、すなわちメソッドのパラメータ調整、これを克服するためのコードの調整までの期間をカバーする、典型的なプレスのパフォーマンスの最適化プロセスです。
まず、プレスディスクの問題がbusy100%
(A)の問題
重要な機能は、シャッターを押すことで、Bは、返信パケットに対応し、パケットAを受信しました。
パフォーマンステストは、ジャムのパケットを受信するためのローカルキューは、バック効率に処理、即ち低速パケットを完了するのに長い時間がシャッターの後のメッセージの数を受信したことを見出しました。例えば、受信パケット全てBパケットが返される17分前、10分の合計、共通のバッフル。
(B)ポジショニング分析
CPU、メモリ、ネットワーク、ディスクの分析から始まる>リソースモニタ、 - PCのタスクマネージャを初めて目
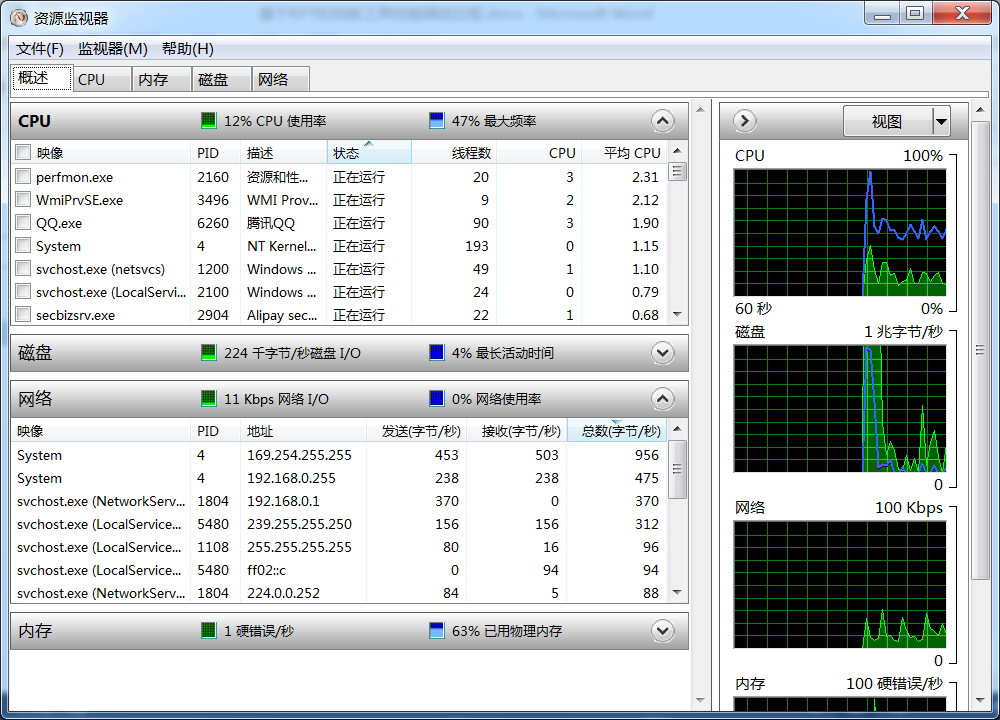
100%の長い期間のためのPC「ディスクの最長有効時間」ことがわかりました
そして、見つかったほとんどのディスクはJAVA、JAVAアプリケーションであるが、多くは、どのアプリケーションに固有の検索に必要な使用を処理する参照してください。
アプリケーション・プロセスに見られるタスクマネージャでは、プロセスをクリックし、右クリックして「開いているファイルの場所」;ほとんどを見つけるためにディスクを使用MQプログラムです。
(C)の解決
過度の書き込みディスクIOによるMQは、最も簡単な方法は、書き込みIOの数を減らすことです。ここでの書き込みIOテストを削減する方法を、メッセージを書き込む、ログディスクの書き込みを書くことよりも多くのMQのは何もMQのいくつかの知識を必要としません。
1.循環ロギングリニアログインVS
MQログ、線形および循環ログログには、それらのうちの2つを持っている:
1)であっても、リニアログメッセージの内容は、より多くのコンテンツの保存、すなわちリニアログ、メッセージが削除された場合、ログを復元することができたキュー、ログに保存されています。
2)メッセージログ・サイクル・保存しません
、代わりに、ログ・サイクルを緩和することが可能である場合は、チェックMQログログは、直線的ではありません。
それが動作しない場合は、次のステップ
VS 1書き換え書き換え2.3
MQ默认的日志写入是3重写入。改为1重写入
这样可以节省大量Disk IO
如果还没有达到效果,进入下一步
3. 持久消息VS非持久消息
持久消息是要写的磁盘的文件里,且记日志(两次写磁盘)
非持久消息,不记日志,一般不会写到磁盘里,除非mq buffer不够用,放不下当前的消息,才会进入磁盘,(非持久消息只有在发不出去的情况下才丢掉,一般情况不会丢失),即一般情况不写磁盘
对于测试压力机,可以容许异常情况下丢报文,所以可以改为非持久消息,这样,又少了一次写IO。
4. 增大MQ buffer
上面提到“非持久消息,不记日志,一般不会写到磁盘里,除非MQ buffer不够用,放不下当前的消息,才会进入磁盘”。因此增大MQ Buffer也可以在某些压力情况下减少一次写IO。
本场景中,我们调整MQ buffer为10M。
(四) 效果
最后“磁盘最长活动时间”由100%变为10%以下,TPS大幅提高。
二、 压力机CPU 80~90%
(一) 问题
7台压力机,总计预计发送750笔报文/秒,但发现只能发出来500多笔报文/秒。
继续从PC的任务管理器->资源监视器,CPU、内存、网络、磁盘的分析入手。
这次,我们发现每台压力机CPU 80~90%,也就是说,磁盘IO的问题解决之后,CPU又变成了下一个瓶颈。
(二) 分析
这种情况下,一般是代码占用了过多的CPU。
分析代码发现,每一次性能测试工具的迭代(线程被调用),这个线程只处理一个MQ消息,即处理一个MQ消息需要打开、关闭一次MQ队列,这个打开、关闭队列是非常消耗CPU的。
(三) 解决
每次性能测试工具的迭代(线程被调用),让这个线程处理多个MQ消息。
问题来了,并不是每次迭代处理的越多越好,每次处理多少个MQ消息合适?
我们采用了 “当前队列深度”和“指定参数”的最小值。
为什么不是“当前队列深度”:设置为“当前队列深度”即每次迭代处理这个队列中所有的报文。那么如果队列深度很大(比如深度是100),这个线程要顺序处理这些消息,比较慢,其他线程得不到消息去处理,性能测试工具发挥不了并发处理的优势。
如果设置一个参数(比如10),每个线程每次最多处理10个消息,那么其他线程就有机会得到消息去并发处理。
因此,我们采用了 “当前队列深度”和“指定参数”的最小值。
(四) 效果
调整代码之后,预计发送750笔报文/秒,实际也真的发出来750笔报文/秒,不但如此,CPU由80-90%变为了30-60%,节约一半的CPU资源。
TPS提升50%,CPU降低一半,里外里,意味着TPS提升了200%(以前40%的CPU利用率支撑250TPS,现在是750TPS)
三、 场景跑完后,压力机CPU变为100%。
(一) 问题
场景跑的时候压力机 CPU 60-70%,跑完后,压力机CPU变为100%。
(二) 分析
这种情况一定是循环没有设置间隔。
或者是线程里面没有设置间隔,或者是线程的两次迭代之间没有设置间隔。经分析是线程的两次迭代之间没有设置间隔。
为什么最初没有设置间隔呢?因为这段代码的作用是实时抓取到达的报文并处理,如果设置间隔了就不那么实时了。
(三) 解决
设置间隔一定能解决这个问题,那么怎么设置呢?
1) 如果线程的两次迭代之间设置间隔,那么接收报文处理的环节就有一定的延时。不是我们想要的(人为的延长了响应时间)。
2) 在应用线程里面设置间隔。
如果有报文需要处理的时候,不设置时间延迟,实时抓取,没有报文的时候延迟20ms后再次读取队列。
处理方法为,判断队列深度,如果深度为0,则延迟20ms,不为0则不延时。
(四) 效果
修改代码后,场景跑完后CPU自然回落(100%变为10%以下)。
四、 内存耗尽
(一) 问题
PC机(4G内存)执行测试时,只有200M剩余,鼠标键盘操作非常缓慢。
(二) 分析
JVMのパフォーマンスツールは、事前に割り当てられた1.5Gであるが、実際にはあまり使用しなかった
解決(c)の
パフォーマンスツールが1Gに調整1.5GからJVMメモリを共有します。
(IV)効果
調整後、システムは、840M、利用可能なメモリ、マウスやフレキシブルキーボードが表示されます
上記の4つの質問の説明から、分析して見ることができます解決、問題のいくつかは、これらの製品の知識が必要で、いくつかの問題は万能でなければならない性能試験のさまざまな側面に遭遇する性能試験を完了し、コードのいくつかの知識が必要。
著者:ヤンJianxu出典:のhttp://www.talkwithtrend.com/home/space.php P =ブログ&トン=&UID = 898849&ページ= 3この記事では、著者に属し、公園の合計をブログ、転載を歓迎するが、作者の同意なしにこれを保持しなければなりませんか?段落の文、および記事のページの見かけ上の位置に元の接続を与えられました。