ファイルハンドル=オープン(「ファイルパス+ファイル名」、「モード」)
例
F =オープン( "test.txtの"、 "R"、エンコード=「UTF-8」)
分析:これは、Pythonのファイルが原因ではないと同じフォルダ内にあるtest.txtファイルを、絶対パスのテストを記述する必要
あなたは絶対パスを書きたい場合は書き込むことができます
F =オープン(ファイル= "D:/python/test.txt"、 "R"、エンコード=「UTF-8」)
複数のファイルオープンモードのモードがあります。
1、テキストファイルオープンモード
「R」、デフォルトモード[読み取り専用モード、ファイルが存在している必要があり、例外がスローされないがあります]
「W」、書き込み専用モード[読めないし、存在しない、作成してから、中身が空になっています]
「A」、唯一の追加書き込みモード[判読できないが、作成、存在しません。唯一の追加コンテンツがあります]
バイナリファイルで開かれ、読み取りバイトは、コンテンツの種類だけでなく、バイト型の書き込みを提供する必要がある、あなたはエンコーディングを指定することはできません
「+」ファイルを同時に読み書きできることを示し
"R +"、[リーダ読み取り可能、書き込み可能]
"W +"、[読み取り、書き込み、読み取り、書き込み}
"A +"、[読み取り、書き込み、読み取り、書き込み}
2)(読み取り可能、書き込み可能()
読みやすいのは()、ファイルの読み込みには、TrueまたはFalseを返すかどうかを決定します
、ファイルが書き込み可能なリターンTrueまたはFalseであるかどうか)(書き込み可能です
例
f.readable()
f.writable()
図3に示すように、READ()、readlineの()、readlines()
f.read()#は、ファイルの末尾にカーソルを移動し、すべてのコンテンツを読みます
文字列の結果を返し、read([size])いかなるサイズパラメータは、読み取りが終了するまでファイルに示していない場合、ファイルのサイズを読み取る方法は、現在の位置からのバイト
f.readline()#1行を読み取り、カーソルが第2の行ヘッダに移動します
結果は文字列として返されます
f.readlines()#は、リストに格納された各ラインの内容を読み取ります
すべてのテキストコンテンツは、リストの要素として、各ラインを読み、リスト形式で結果を返しますが、より多くのメモリの合計となり、大きなファイルを読み込みます。
図4に示すように、書き込み()、writelines()
書き込み()文字列を書くために
writelinesは()両方の文字列を渡すことができますし、文字列を渡すことができ、文字の順番にファイルを書き込みます。あなたは、文字列を渡す必要があり、それは数字の配列であることができないことに注意してください。
f.write( '1111 \ N222の\ nの ')#のテキストモード用の書き込み、あなたは自分の改行書く必要が f.write( '1111の\ N222用の\ n'.encode (' UTF-8「))#のBのモード書き込み、自分のニーズ改行書き込み f.writelines([ '333 \ n'は 、 '444 \ n'])#のファイルモード f.writelines([バイト( '333 \ n'は、符号化= 'UTF-8')、 '444 \ n'.encode(' UTF- 8「)])#Bのモード
5、f.close()#は、閉鎖されたファイルを表示するために、f.closed()#ファイルを閉じます
openメソッドを使用してファイルを開いた後、ファイルを閉じます()f.closeを使用する必要があります。
ファイルオブジェクトを開くことができるファイルの数が限られていると同時に、オペレーティングシステムおよびオペレーティングシステムのリソースを占有しますので、ファイルの後、使用後に閉じていなければなりません。
#は、ファイルが閉じられている表示)(f.closed、TrueまたはFalseを返すかどうか
6、openメソッドFとして有するオープン
これは、ファイルに書き込むことなく、ファイルを閉じるための道を開くf.closed
例
:( '/パス/ /ファイルに'、 'R')、Fなどのオープンと Fとして開く( "test.txtの"、 "R"、エンコーディング=「UTF-8」)。
7、非テキストファイルのために、我々は唯一のBモードを使用することができます
非テキストファイルのオープンモードは、専用モードbは、「b」はバイト単位の仕方を表し(およびすべてのファイルがバイトの形式で保存され、エンコードされたテキスト文書の文字を考慮せずに、このモデルを使用すること、 JGP形式の画像ファイル、AVI形式のビデオファイル、Bモード、クロスプラットフォーム)
"RB"
"WB"
"AB"
F =オープン( "test.py"、 "RB")
分析:開かれたバイナリがあるので、オープンエンコーディングを設定する必要はありません、エンコーディングは=「UTF-8」、これが適用できないことに注意してください
例
F =オープン( "test.py"、 "RB") データ= f.read() 印刷(データ)
ファイルのtest.py内容:
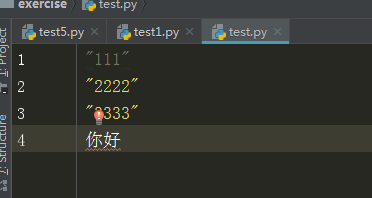
輸出
B ' "111" \ R \ n "2222" \ R \ n "3333" \ R \ n \ xe4 \ XBD \ XA0 \ xe5 xa5の\のXBD \'
分析:ここでは\ rを\ nは改行、Windowsプラットフォームで、Bで始まるが、出力バイト形式を表し
ここでは\ xe4 \ XBD \ XA0 \ xe5漢字に代わってxa5の\のXBD」\
F =オープン( "test.py"、 "RB") データ= f.read() プリント(data.decode( "UTF-8"))
出力
"111" "2222" "3333" 你好
分析:test.pyファイルストレージUTF-8が格納されている場合、本明細書で使用されるように「UTF-8」は出力プリントアウト時に復号することができます。
bで開いたときに、読み取りバイトは、コンテンツの種類だけでなく、バイト型の書き込みを提供する必要がある、あなたはエンコーディングを指定することはできません
例2
F =オープン( "test11.py"、 "WB")f.write( "111 \ n") f.close()
出力:代わりに、ここに書き込まれたバイトの文字列のエラー、ここで必要なバイトを示唆は、形式で記述する必要があります
変更することができます
F =オープン( "test11.py"、 "WB") f.write(バイト( "111 \ n"は、エンコード= "UTF-8")) f.close()
分析:ここにすることができます文字列「111 \ n」はバイト()のコードを割り当てなければならないファイルは、書かれています。
直接文字列ではなく、バイト()メソッドをコード
F =オープン( "test11.py"、 "WB") f.write( "222 \ n" .encode( "UTF-8")) f.close()
8、f.encoding
エンコードされたファイルを開いてください
例
F =オープン( "test11.py"、 "W"、エンコーディング= "GBK") f.write( "222 \ n") f.close() プリント(f.encoding)
輸出
GBK
分析:ファイルに関係なく、ソースファイルの実際の符号化、コードにステートメントを開く開放符号化です。
9、f.flush()、f.tell()
f.flush()すぐに(フラッシュする必要はありません、コマンドプロンプト操作を使用する必要は、ハードディスクpycharm年の内容を書くために直接書き込まれます硬いブラシ、にメモリの内容をファイル)
f.tell()現在のカーソル位置を取得します
10、紙のカーソル移動
(3)読み:
場合は、テキストモードでファイルを開くための方法として、3つの文字に代わって読んで
B、ファイルオープンモードがモードBであり、3バイトのデータの読み出しを表します
ファイル全体のデフォルトを読み込む)(読み
残りのファイルは、カーソル移動しているよう求めて、教えて、切り捨てるバイト
例
あるtest.txtファイルの内容
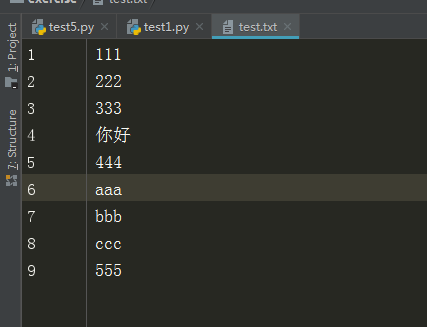
F =オープン( "test.txtの"、 "RB") データ= f.read(6) f.close() 印刷(データ)
出力
「B'111 \ rを\ N2
分析:この3バイト・カウント111、\ R \ N bは、計算バイトモードである2バイトカウント、バイトカウント2、すなわち符号化が指定することはできません書き込むことができないエンコーディング=「XX 」、それ以外の場合はエラーになります
例2
上記と同じファイルの内容
F =オープン( "test.txtの"、 "R +"、エンコーディング= "UTF-8") データ= f.read(6) f.close() 印刷(データ)
出力
111 22
分析:これは、オペレータ3 111、改行\ rをする\ n文字カウントは、2つの22文字、6つの文字の総数をカウントするテキストモード、です。
11、(シーク)
シーク()指定された場所にファイルにカーソルを移動。
()構文を求めます
f.seek(オフセット[、そこ])
即ち、バイト数はデフォルトは0であり、運動は、3つのモードがある0,1,2そこから、0はファイルカウントの開始は、カウントは、現在の位置を表すファイル・カウントの開始終了を表しオフセット。1とBモードが実行されなければならない2、しかし、モバイル・ユニットは、バイトでラップモードであるかにかかわらずは、Widnowsシステムのサイズは2バイト(\ Rの\ n)です。
例
あるtest.txtファイルの内容
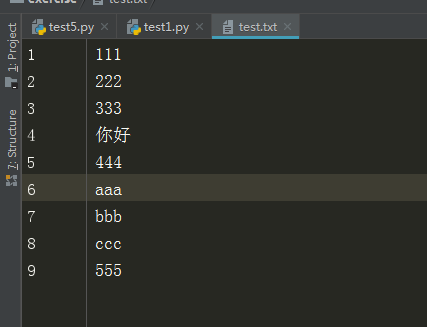
F =オープン( "test.txtの"、 "R +"、エンコーディング= "UTF-8") f.seek(3,0) データ= f.read() f.close() 印刷(データ)
出力

222 333 こんにちは 444 のAAA のBBB CCC 555
例2
上記と同じファイルの内容
F =オープン( "test.txtの"、 "RB") f.seek(5) f.seek(11,1) プリント(f.tell()) データ= f.read() f.close() 印刷(データ)
出力
16 B '\ XBD \ XA0 \ xe5 \ xa5 \ XBD \ R \ N444 \ R \ NAAA \ R \ nbbb \ R \ NCCC \ R \ n555'
分析

ここで、バイナリオープンで、目に見えない\ rをする\ n改行の後ろに3バイト・カウント111は、従って、(5)最初の行の位置が最後のシーク
seek(11,1)是从当前位置继续移动光标,即222\r\n算5个字节,同理333\r\n算5个字节,“你好”(文本文件是utf-8编码的)算6个字节,因此这时只取“你”这个字的3个字节的第一个字节,光标移动到你的第一个字节之后,所以最后输出了\xbd\xa0\xe5\xa5\xbd共5个字节。
注意这里的光标操作要用seek()方法,直接用鼠标移动光标是无效的。
例子3
文件内容
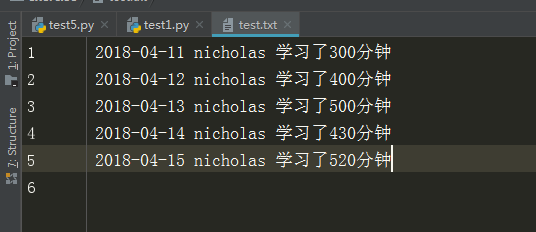
f = open("test.txt","rb")
offs = -20
while True:
f.seek(offs,2)
data = f.readlines()
if len(data) > 1:
print("文件的最后一行是%s"%data[-1].decode("utf-8"))
breakf = open("test.txt","rb")
offs = -20
while True:
f.seek(offs,2)
data = f.readlines()
if len(data) > 1:
print("文件的最后一行是%s"%data[-1].decode("utf-8"))
break
这里目的是在不知道一行是多少字节的情况下输入最后一行
输出结果
文件的最后一行是2018-04-15 nicholas 学习了520分钟
分析:seek(-20,2)是从文件的最后开始计算的,必须以b模式进行。
12、 truncate()
truncate() 方法用于从文件的首行首字节开始截断,截断文件为 size 个字节,无 size 表示从当前位置截断;截断后面的所有字节被删除,其中 Widnows 系统下的换行代表2个字节大小。
例子
文件内容
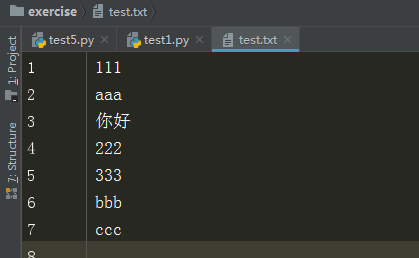
f = open("test.txt","r+")
f.truncate(10)
data = f.read()
print(data)
输出结果
111 aaa