教師なし学習
相対教師あり学習(Xへの入力、対応するY)、マークされていません
クラスタリング
- K-手段
- 密度ベースのクラスタリング
- 予想される最大クラスター
次元削減
- 潜在意味解析(LSA)
- 主成分分析(PCA)
- 特異値分解(SVD)
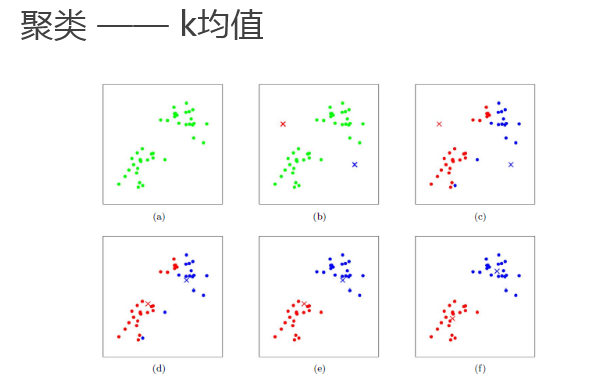
K-手段(k平均)クラスタリングアルゴリズムは、最も簡単な、効率的、教師なし学習アルゴリズムはに属している
核となるアイデア:カテゴリのクラスタ(クラスタ)として、ユーザにより指定されたkの初期重心(初期重心)、繰り返し反復アルゴリズムが収束するまで
、基本的なアルゴリズムのプロセスを:
- K初期重心(初期クラスタ)を選択します。
- 繰り返す:
;各サンプル点に対して最も近い重心、そのマークのカテゴリ対応するクラスタの重心を得るために計算された k個のcluser重心に対応する再計算; まで重心変動がもはや発生しないか、最大反復に達しました
関数kmeansコードの実装
インポートNP AS numpyの インポートは、PLTのAS matplotlib.pyplot #はsklearnから直接クラスタデータを生成 から sklearn.datasets.samples_generatorのインポート make_blobs
データのロード
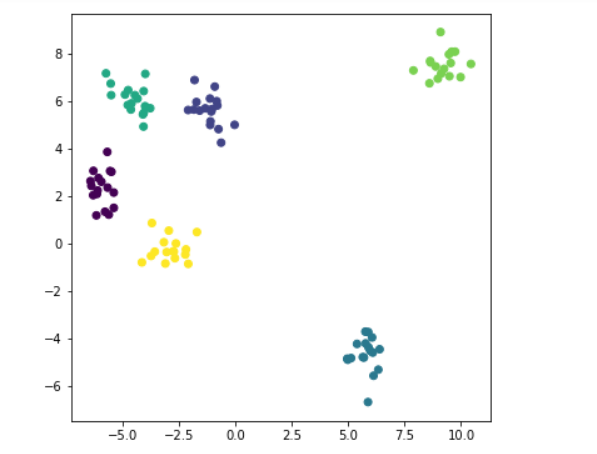
X、Y = make_blobs(N_SAMPLES = 100、センター= 6、random_state = 1234 cluster_std = 0.6 ) #100サンプル、生成されたサンプル(カテゴリ)数の中心を中心と; random_stateはによって使用される乱数発生器を--seed; #1 cluster_std各カテゴリの分散の異なるセット #x.shape番号(100 2) plt.figure(figsize =(6,6 )) plt.scatter(Xの[:0]、X [: 1]、C = Y) #1 C = Yクラス6、色となる (plt.show)
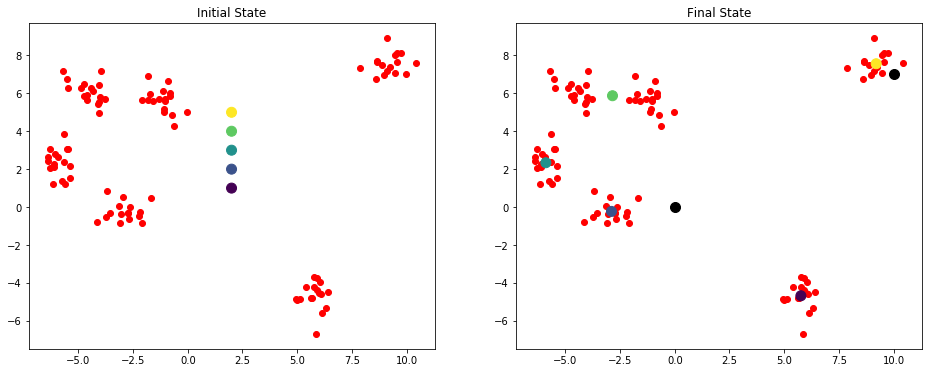
アルゴリズム
#距離関数scipyのダウンロード導入され、デフォルトは、ユークリッド距離計算される から scipy.spatial.distance インポートcdistの クラスK_Means(オブジェクト): #1 初期化、パラメータn_clusters(K)、max_iter反復の初期重心重心 DEF __init__。(セルフ、n_clusters 5 = =の、max_iterは= 300、重心:[]) self.n_clusters = n_clusters self.max_iter = max_iter self.centroids = np.array(DTYPE =、の重心np.float) #の学習モデル法、k平均クラスタリング処理、パス生データ DEF フィット(自己、データ): #初期の重心のデータに初期重心、ランダムに選択された点を指定しない場合 IF(== self.centroids.shape(0)): #指標値としてデータ線0から6まで番号データからランダムに生成された整数、 self.centroidsの=のデータ[np.random.randint(0、data.shape [0]、self.n_clusters) 、:] #反復 のために I における範囲(self.max_iter): #1は、取得した距離行列は100×6つの行列で算出 距離= cdist(データ、self.centroids) #2.ほぼ距離これまで現在のポイントを無料として最も近い重心点のカテゴリを選択、並べ替えに c_ind = np.argmin(距離、軸=を。1) #Axisは最新のものを保持します。1 = #3は、データの種類ごとに算出した平均値、重心を更新座標 のために私にレンジ(self.n_clusters): #はカテゴリにc_indに表示されていない除外する 場合私でc_ind: #は、i点は、平均値がi番目の重心更新の内部データ座標取っているすべてのカテゴリを選択 #1 のデータを[I == c_ind]ブール指標の真の値を取得 self.centroidsを[I] = np.mean(DATA [c_ind == I]、Axisは= 0) #実装予測方法は、 DEF 予測(セルフ、サンプル): #上記、第一算出された距離マトリックスと、次に最も近い重心を選択し、そのカテゴリの 距離は= cdist (試料、self.centroids) c_ind = np.argmin(距離、軸= 1 ) を返すc_ind #のいくつかの点は行数を表すがあり、テストでは4 * 5(4重心点)の2次元アレイを#を、行番号であります各重心の距離 DIST = np.array([121,221,32,43 ]、 [ 121,1,12,23 ] [65,21,2,43 ]、 [ 1,221,32,43 ]、 [ 21,11,22,3 ]]) c_ind = np.argmin(DIST、軸= 1 ) プリント(c_ind) #各要素と最近、どのような[2 0 2. 3. 1] x_new = X [0 :. 5 ] 印刷(x_new) #の 印刷(c_ind == 2)#1 [真偽真偽偽] 印刷(x_new [c_ind == 2 ]) NP .mean(x_new [c_ind == 2]、軸= 0) #各々は、各列の平均値に対応する座標
----- >>
[2 1 2 0 3 ] [[ -0.02708305 5.0215929 ] [ -5.49252256 6.27366991 ] [ -5.37691608 1.51403209 ] [ -5.37872006 2.16059225 ] [ 9.58333171 8.10916554 ] [真FALSE TRUE FALSE FALSE] [ -0.02708305 5.0215929 ] [ -5.37691608 1.51403209 ] OUT [ 14 ]: 配列([ -2.70199956、3.26781249])
テスト
#は、関数は、図サブにプロット定義 DEF plotKMeans(X、Y、サブプロット、タイトル、の重心): #図の割当サブビュー121 1は、最初のサブ行2を示している。 plt.subplot(サブプロット) plt.scatterを( X [:0]、X [: 1]、C = ' R&LT ' ) #1 ドロー重心 plt.scatter(重心[:0] 、重心[:1]、C = np.array(範囲(5))、S = 100 ) plt.title(タイトル) #の初期指定された点の重心 関数kmeans = K_Means(max_iter = 300、重心= np.array([2,1]、[2,2]、[2,1 3]、[2,4]、[2,5 ])) plt.figure(figsize =(16 ,. 6 )) #図の初期状態 plotKMeans(X、Y、kmeans.centroids、121、' 初期状態') #のスタートクラスタ kmeans.fit(X) plotKMeans(X、Y、kmeans.centroids、 122、' 最終状態' ) #は、新しいデータポイントカテゴリを予測 x_new = np.array([0,0] 、[10 、7。]]) y_pred = kmeans.predict(x_new) プリント(kmeans.centroids) プリント(y_pred) plt.scatter(x_new [:0]、[x_new: 1] = 100 S、C = ' ブラック' ) ---- >> [ 5.76444812 -4.67941789 ] [ -2.89174024 -0.22808556 ] [ -5.89115978 2.33887408 ] [-2.8455246 5.87376915 ] [ 9.20551979 7.56124841 ] [ 1 4]