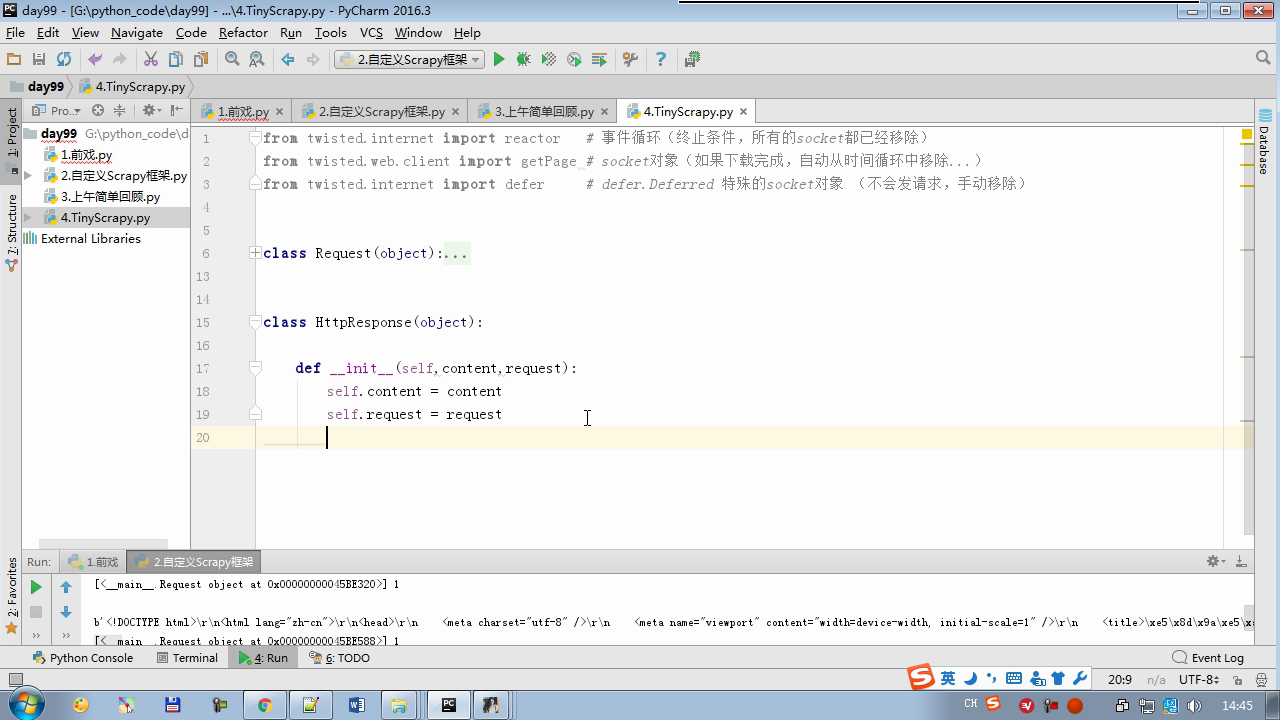
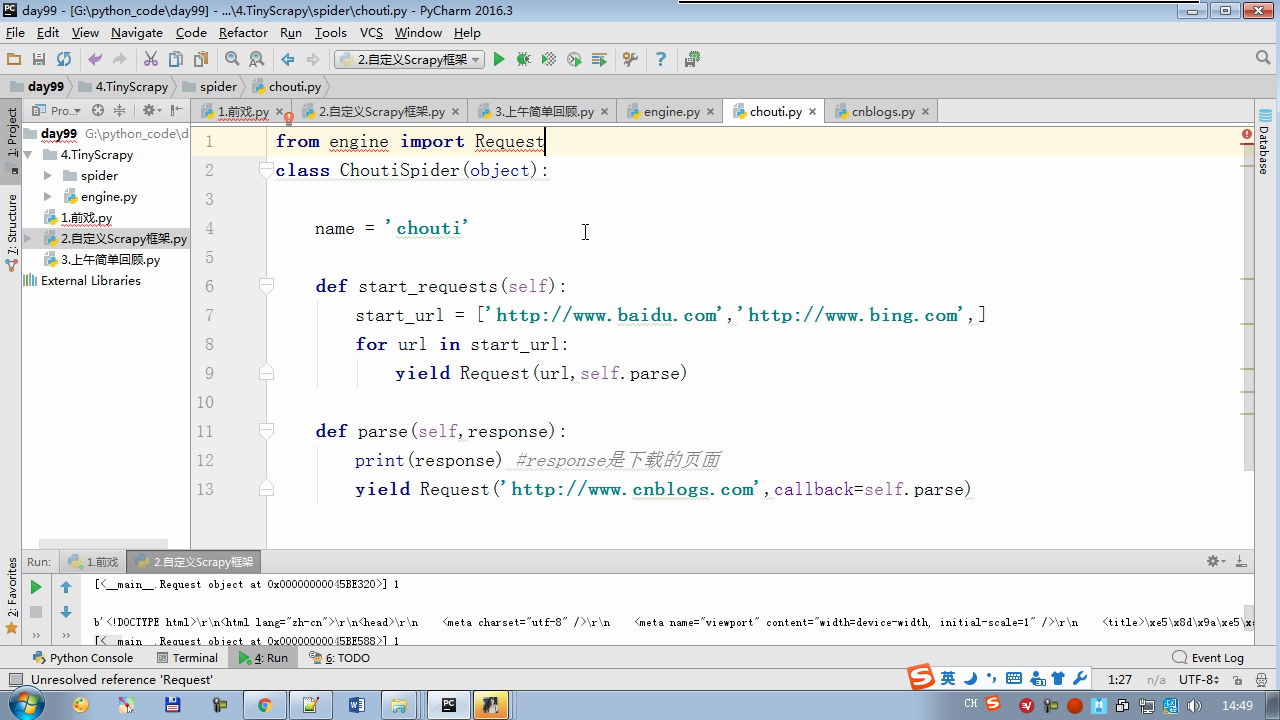
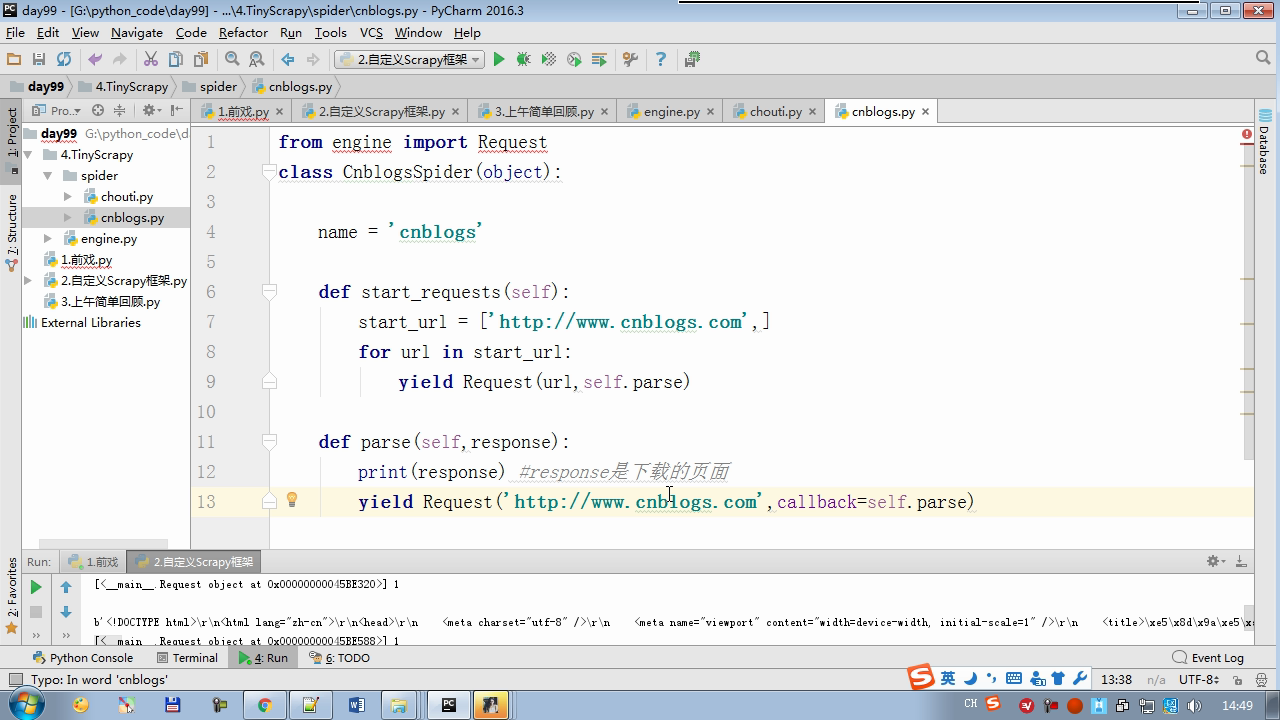
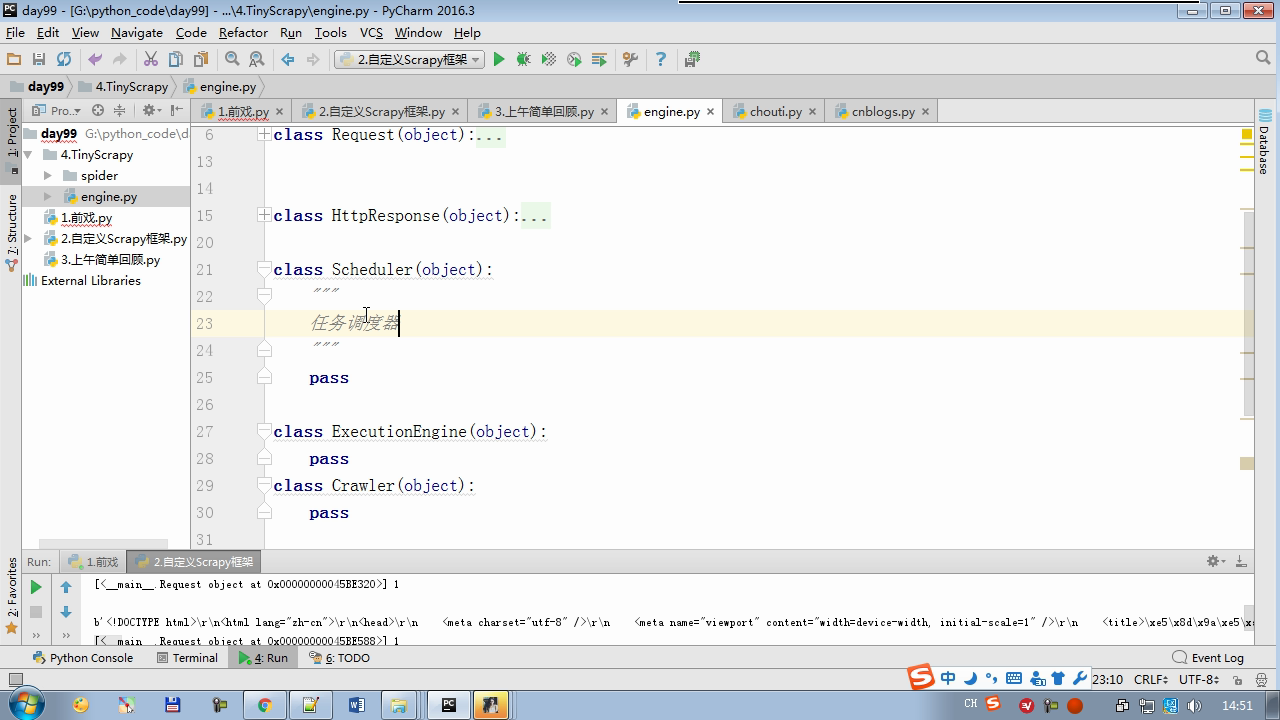
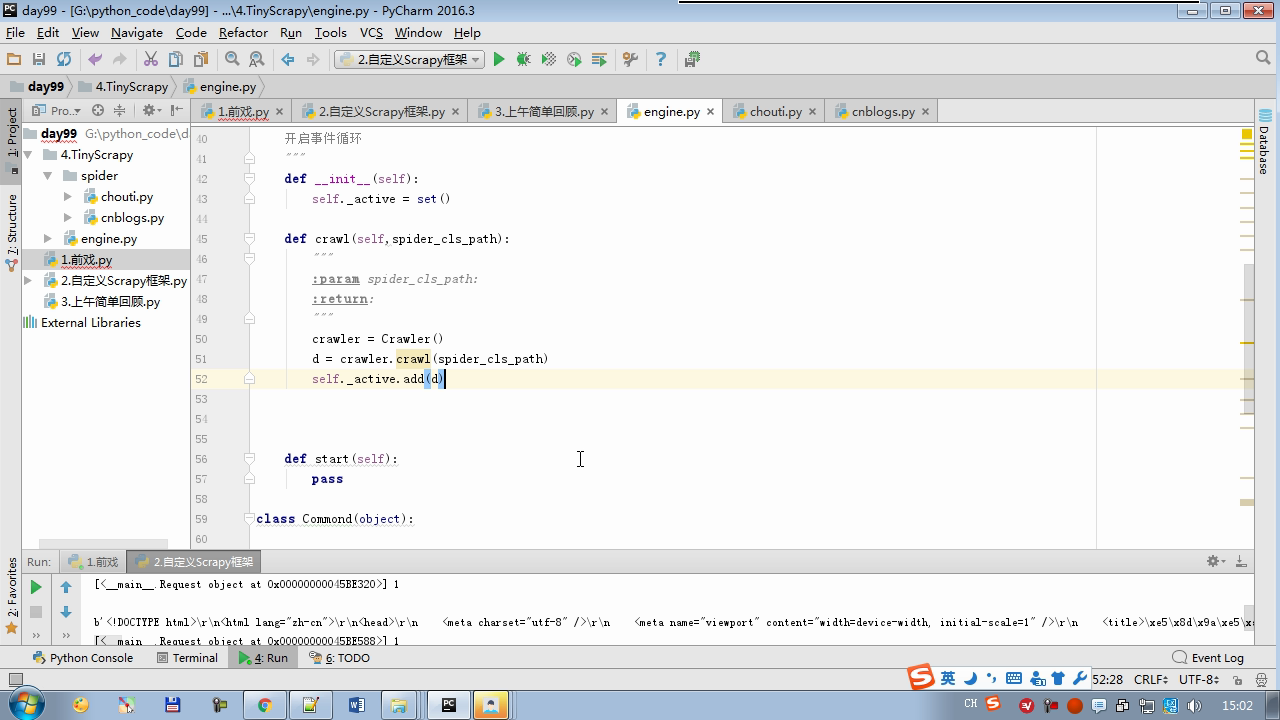
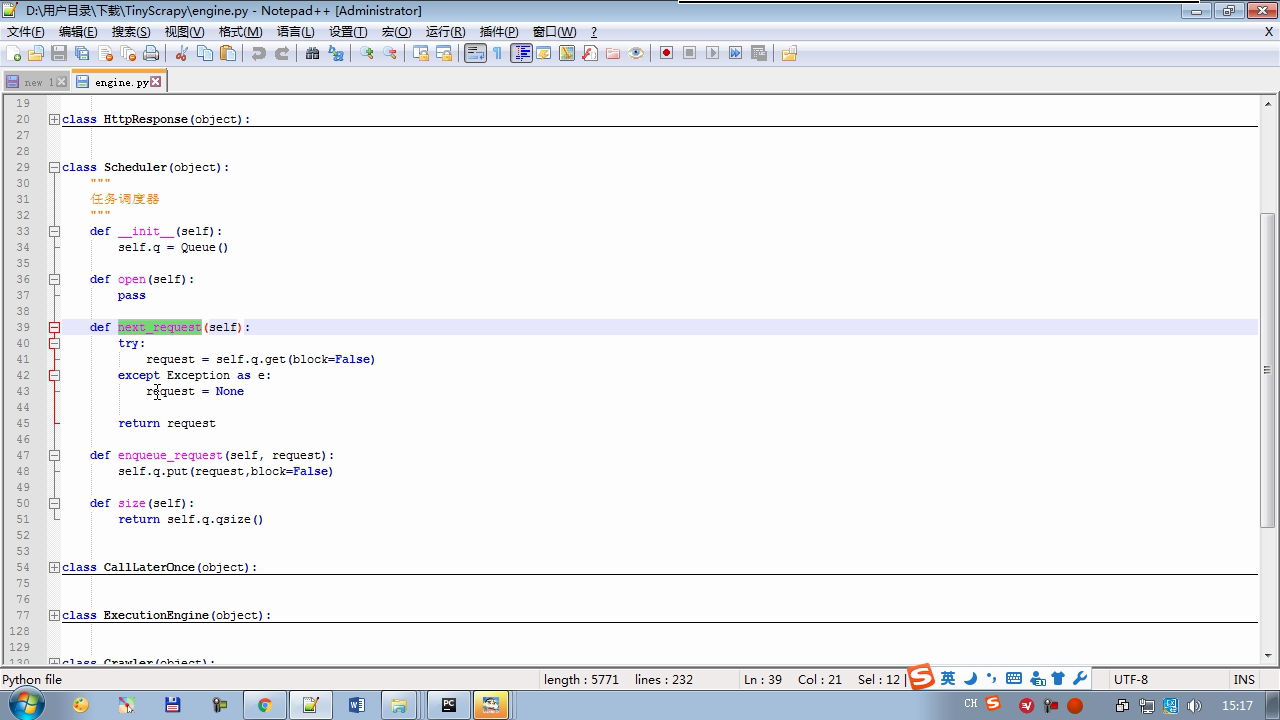
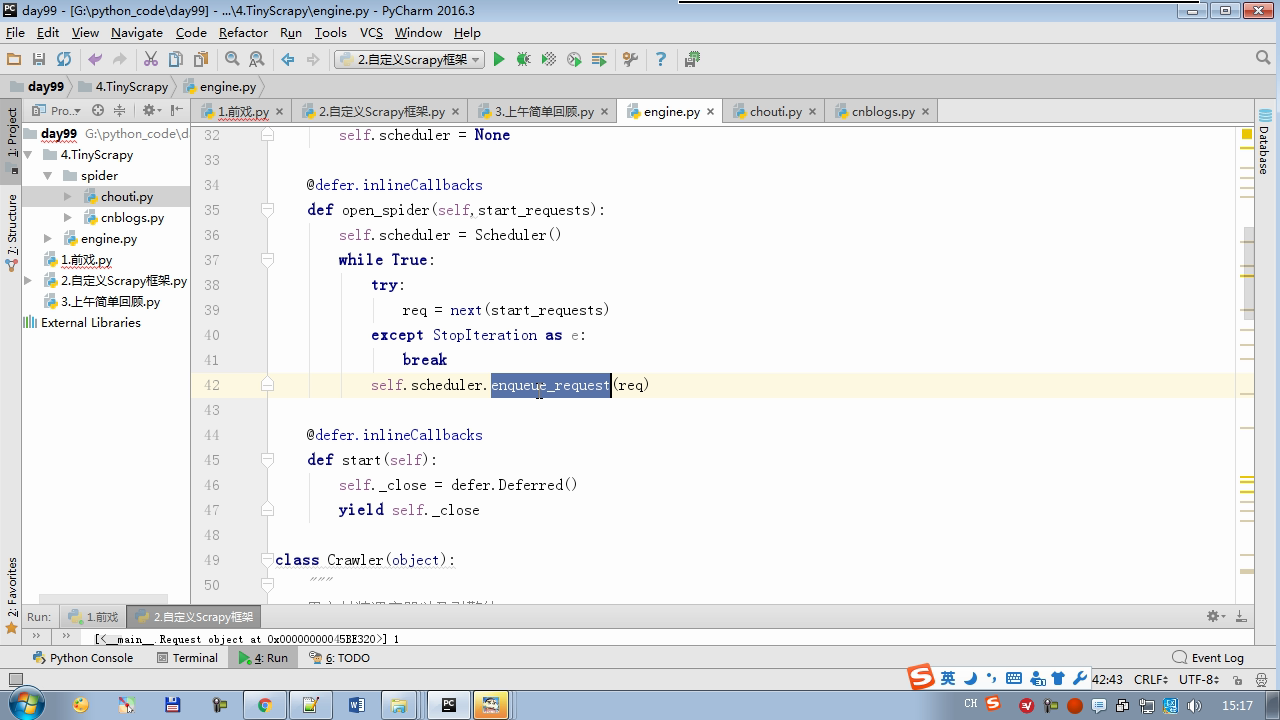
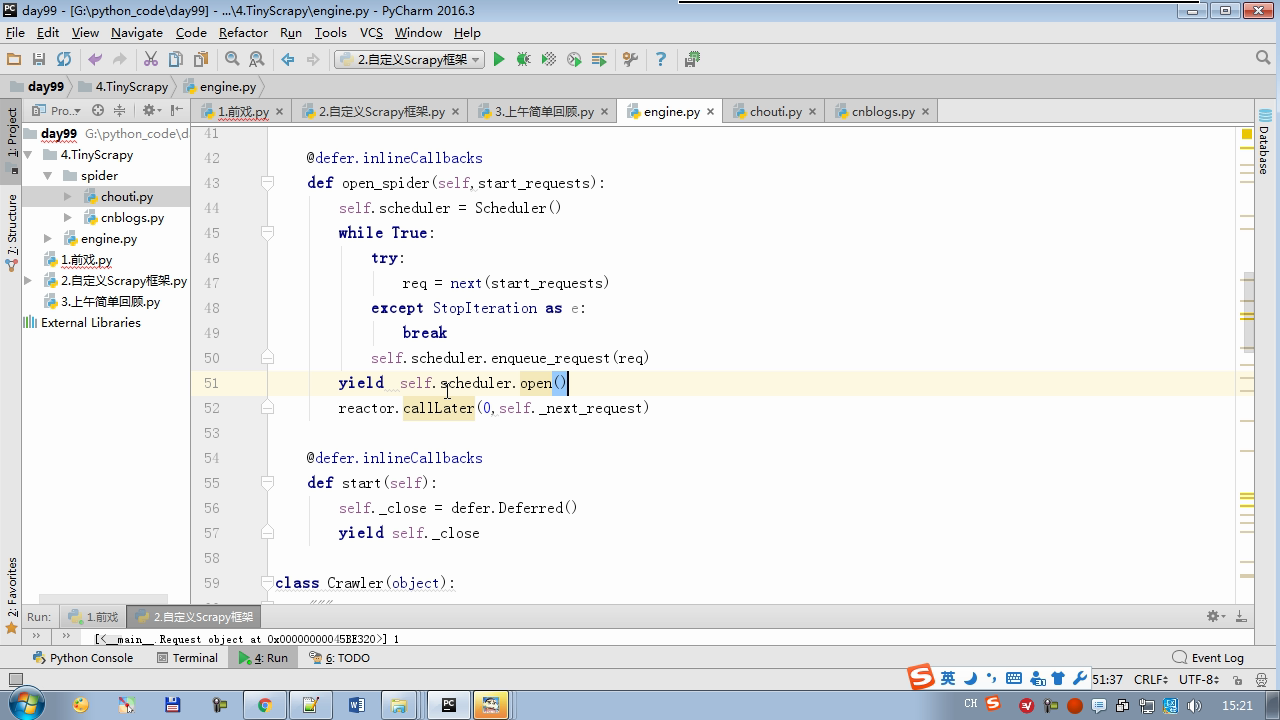
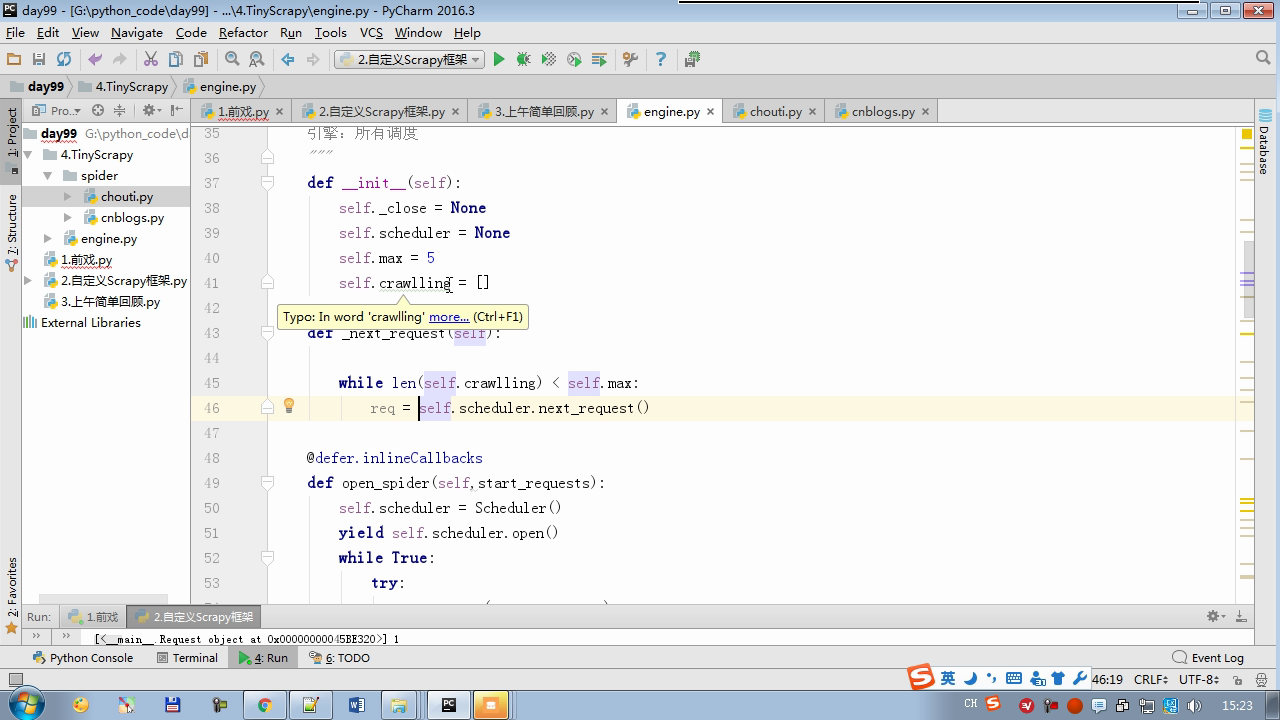
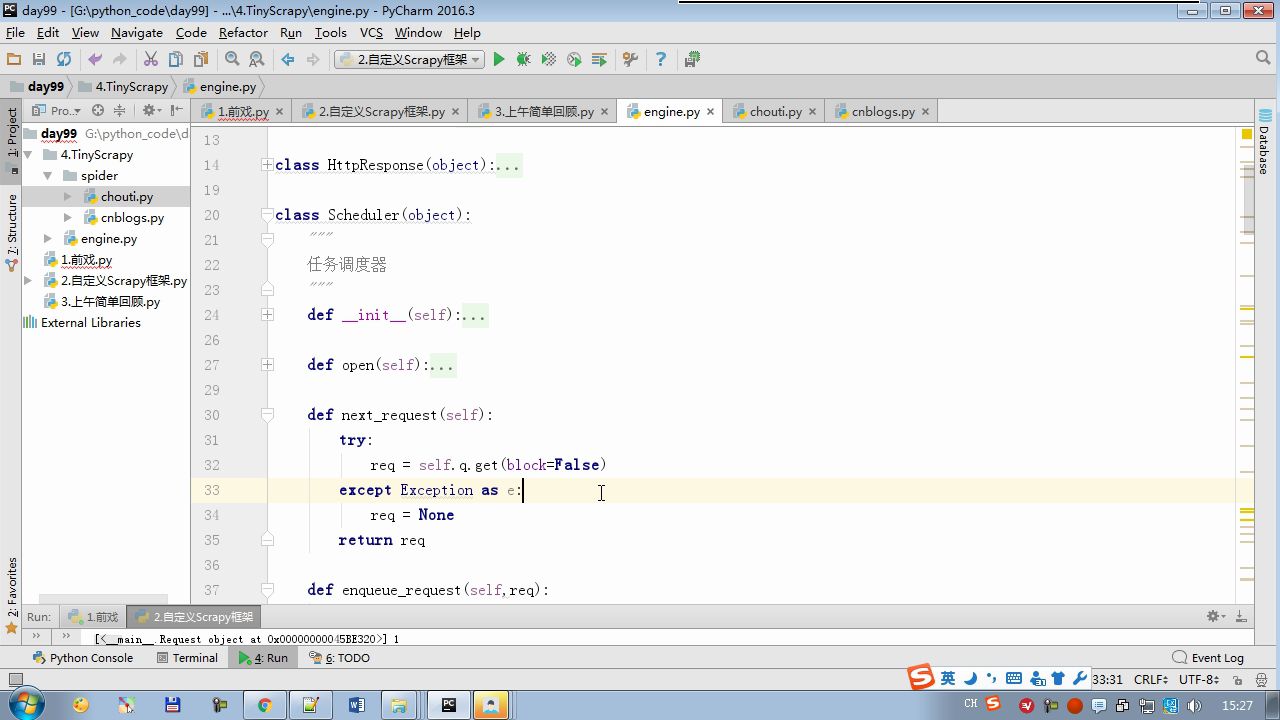
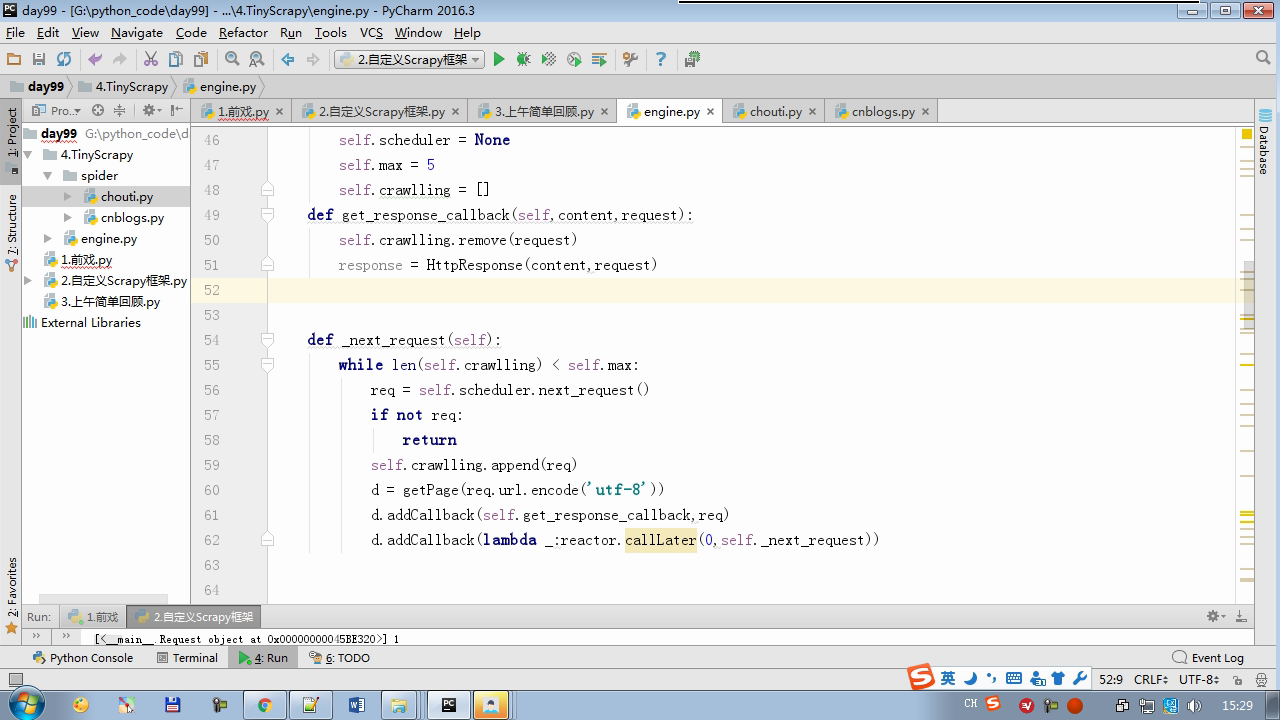
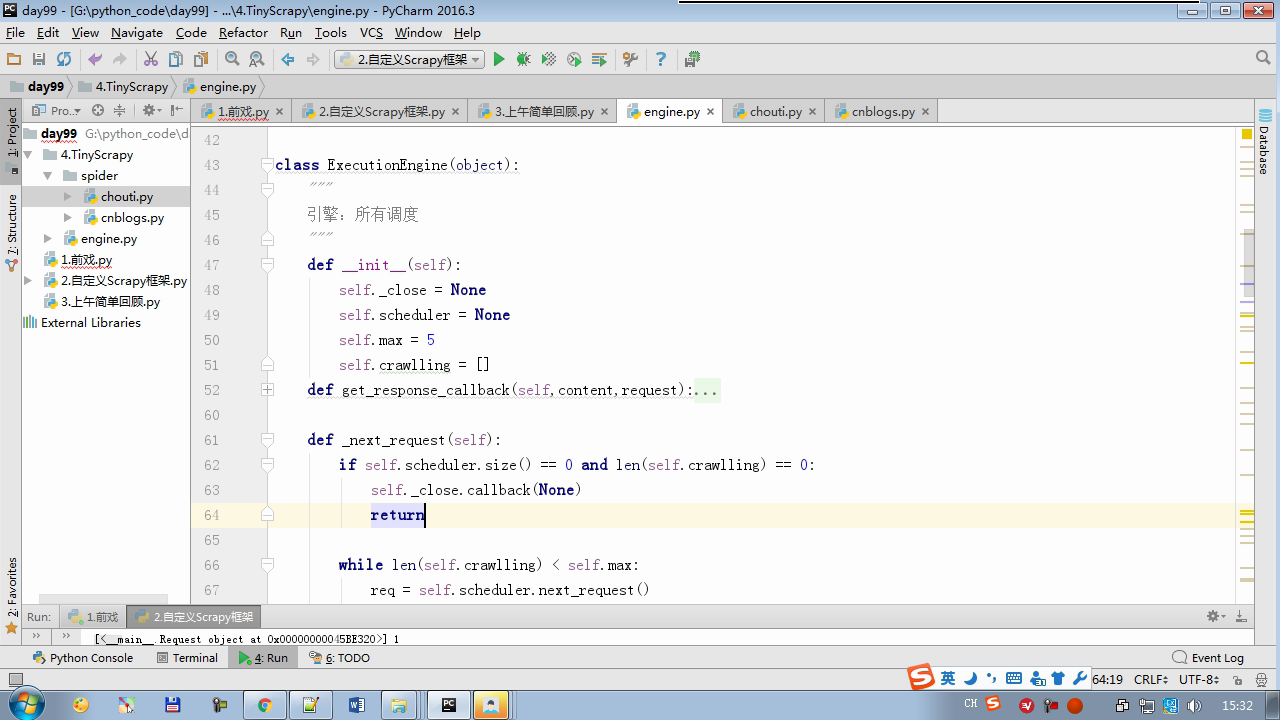
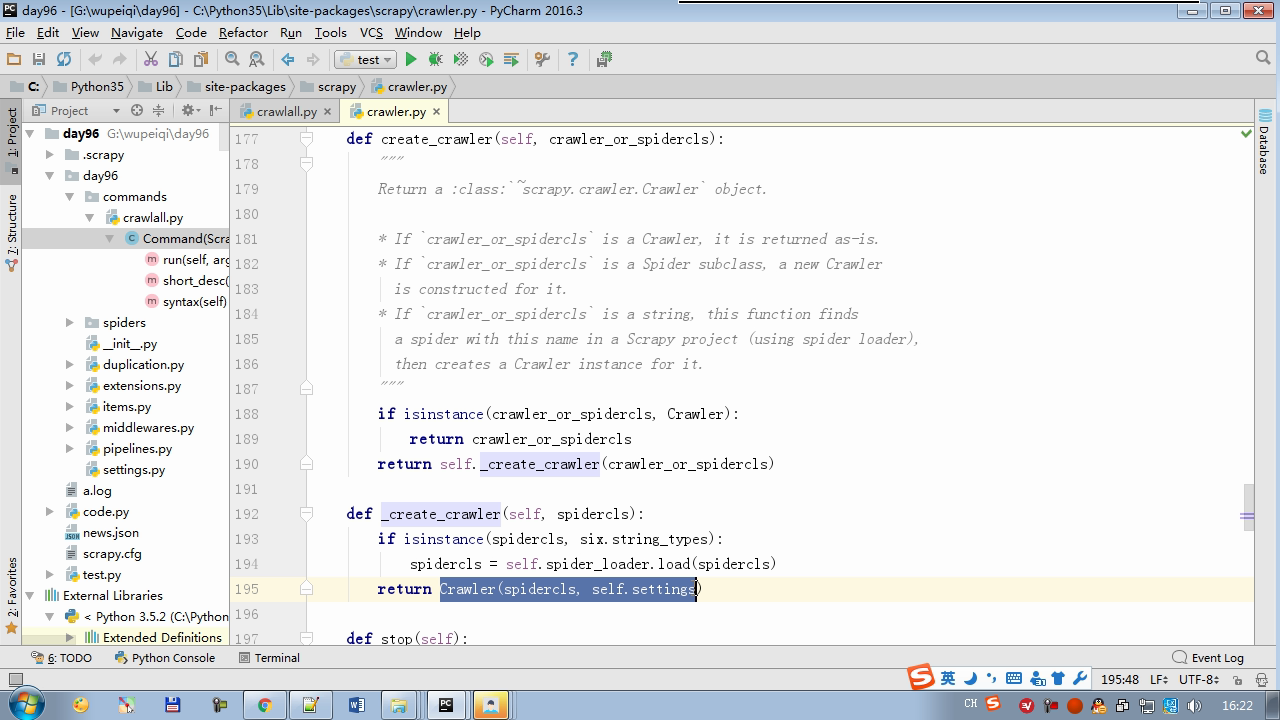
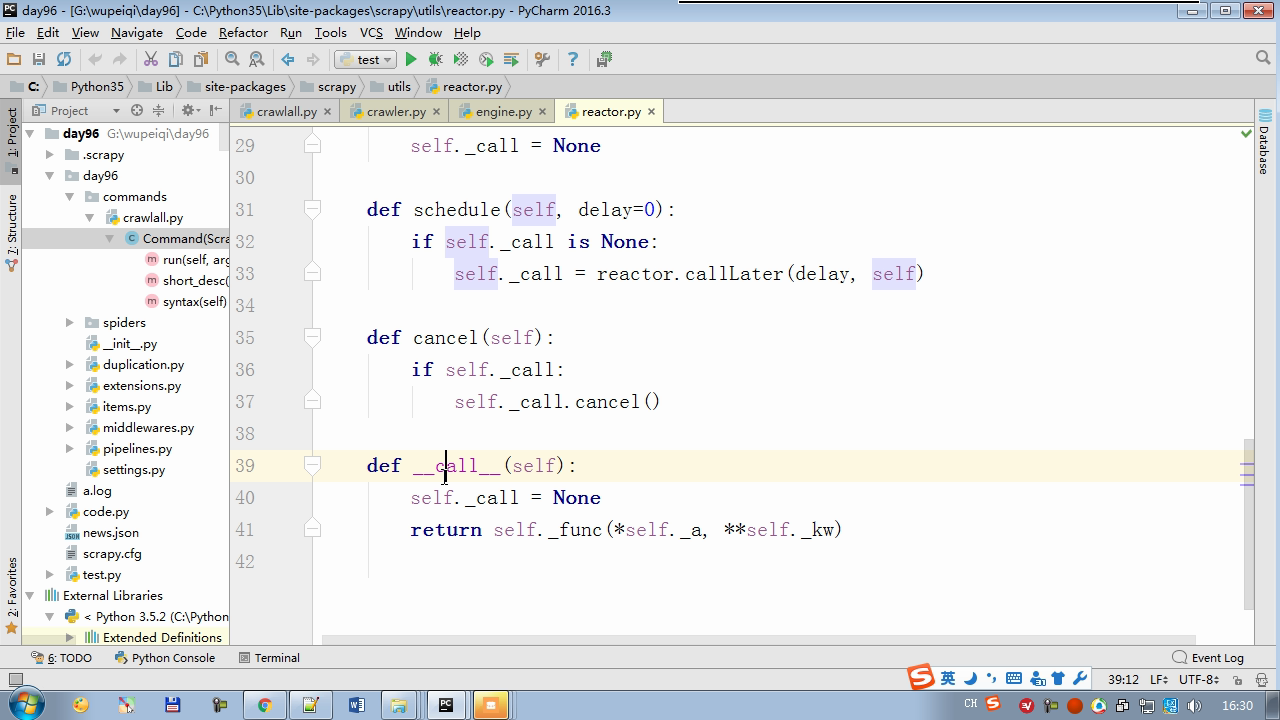
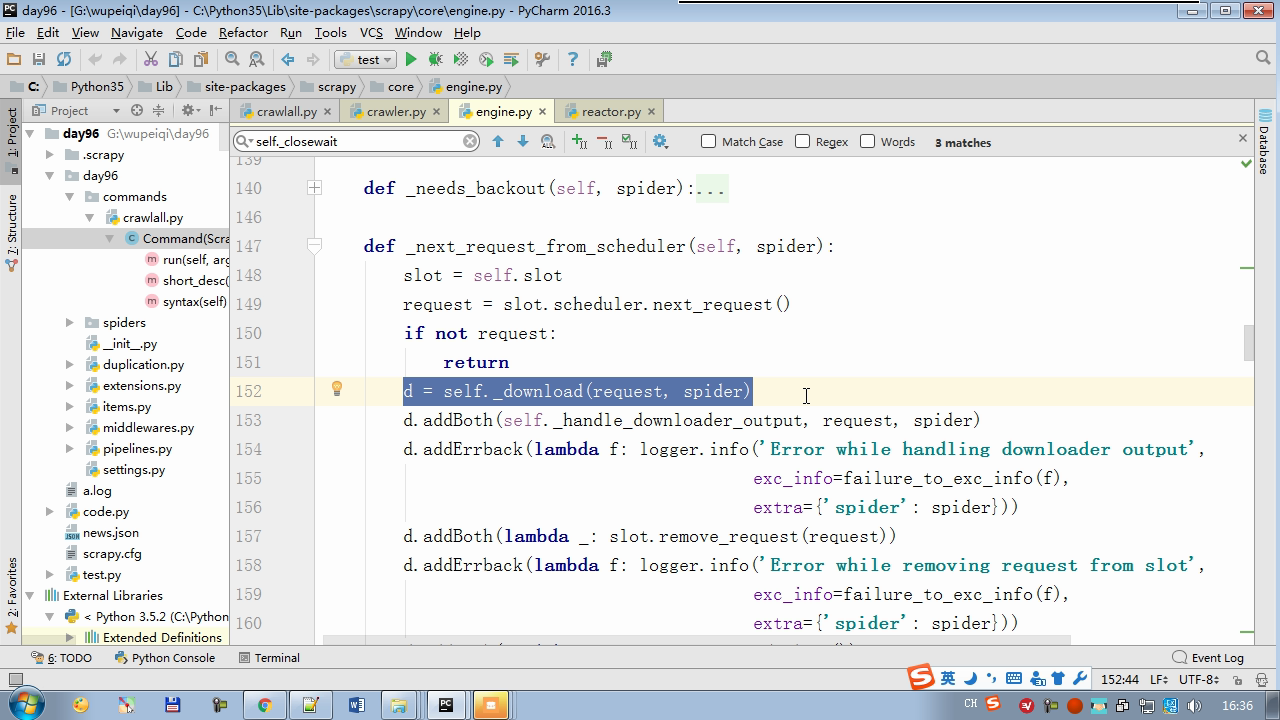
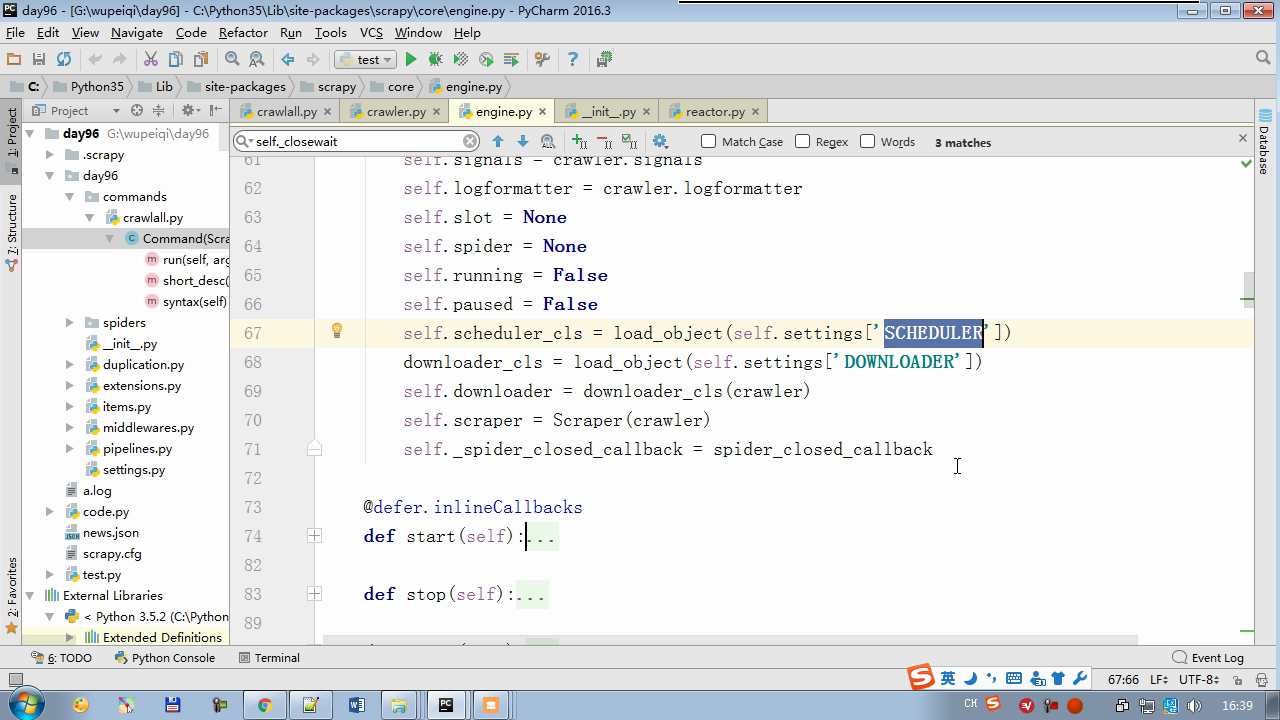
twisted.internet インポート原子炉 #のイベントループ(終了条件、ソケットのすべてが削除されている) から twisted.web.client インポート GETPAGE #のソケットオブジェクト(ダウンロードが完了している場合は、時間が自動的に循環から除去...) からツイスト.internet インポートは延期 #は特殊なソケットオブジェクト(再送要求が手動で削除されていない)defer.Deferred からキューのインポートキュー クラス要求(オブジェクト): 「」「 ユーザーのための情報パッケージ要求 「」」 DEF __init__ (自己を、 URL、コールバック): self.url = URLの self.callback = コールバック クラスのHttpResponse(オブジェクト): デフ __init__ (自己、コンテンツ、リクエスト): self.content = コンテンツ self.request = リクエスト クラススケジューラ(オブジェクト): "" " 任务调度器 """ DEF __init__ (自己): self.q = キュー() デフオープン(自己): 渡す デフnext_request(自己): 試してください: REQ(ブロック= = self.q.get false)を 除き、Eなど例外: REQ =なし 戻りREQ デフenqueue_request(自己、REQ): self.q.put(REQ) デフサイズ(自己): 戻りself.q.qsize() クラスExecutionEngine(オブジェクト): "" " 引擎:所有调度 """ DEF __init__ (自己): self._close = なし self.scheduler = なし self.max = 5 self.crawlling = [] DEF get_response_callback(自己、コンテンツ、リクエスト): self.crawlling.remove(リクエスト) 応答 =HttpResponse(コンテンツ、リクエスト) 結果 = request.callback(応答) のインポートタイプ 場合でisinstance(その結果、types.GeneratorType) 用 REQ における結果: self.scheduler.enqueue_request(REQ) DEF _next_request(自己): もし self.scheduler。サイズ()== 0 と LEN(self.crawlling)== 0: self._close.callback(なし) 戻り つつ LEN(self.crawlling)< self.max: REQ = self.scheduler.next_request() なりません REQ: 戻り self.crawlling.append(REQ) D = GETPAGE(req.url.encode(' UTF-8 ' )) d.addCallback(self.get_response_callback、REQ) d.addCallback(ラムダ_:reactor.callLater(0 、self._next_request)) defer.inlineCallbacks @ デフopen_spider(自己、start_requests): self.scheduler = スケジューラ() 降伏self.scheduler.open() しながら、真は: 試す: REQが = 次の(start_requests) 以外を呼び出すとStopIteration eと: 破る self.scheduler.enqueue_request(REQ) reactor.callLater(0、self._next_request)を defer.inlineCallbacks @ デフを開始(自己): self._close = defer.Deferred() 降伏self._closeの クラスクローラ(オブジェクト): "" " 用户封装调度器以及引擎的... """ DEF _create_engine(自己): 戻りExecutionEngine() デフ_create_spider(自己 、spider_cls_path):""」 :のparam spider_cls_path:spider.chouti.ChoutiSpider :戻ります: 「」」 module_path、cls_name = spider_cls_path.rsplit(' '、maxsplit個= 1 ) 輸入のimportlib M = importlib.import_module(module_path) CLS = GETATTR(M、cls_name) リターンCLS() defer.inlineCallbacks @ DEF (自己、spider_cls_path)をクロール: エンジン = self._create_engine() クモ = self._create_spider(spider_cls_path) start_requests = ITER(spider.start_requests()) 収率 engine.open_spider(start_requests) 収率engine.start() クラスCrawlerProcess(オブジェクト): "" " 开启事件循环 """ DEF __init__ (自己): self._active = セット() デフクロール(自己、spider_cls_path): "" " :PARAM spider_cls_path: :リターン :""" クローラー = クローラー() D = crawler.crawl(spider_cls_path) self._active.add(D) DEF (自己)開始: DD = defer.DeferredList(self._active) dd.addBoth(ラムダ_:reactor.stop()) reactor.run() クラスCommond(オブジェクト): DEF 実行(自己): crawl_process = CrawlerProcess() spider_cls_path_list = [ ' spider.chouti.ChoutiSpider '、' spider.cnblogs.CnblogsSpider ' 、] 用 spider_cls_path でspider_cls_path_list: crawl_process.crawl(spider_cls_path) crawl_process.start() の場合 __name__ == ' __main__ ' : CMD Commond()= cmd.run()