記事のディレクトリ
1. JVMのメモリ構造からなります
2. JVMのガベージコレクション
前記ガベージコレクタおよびアルゴリズム
4. JDK1.6クラスファイル構造
比較の永久世代5. jdk1.8要素スペース
1. JVMのメモリ構造からなります
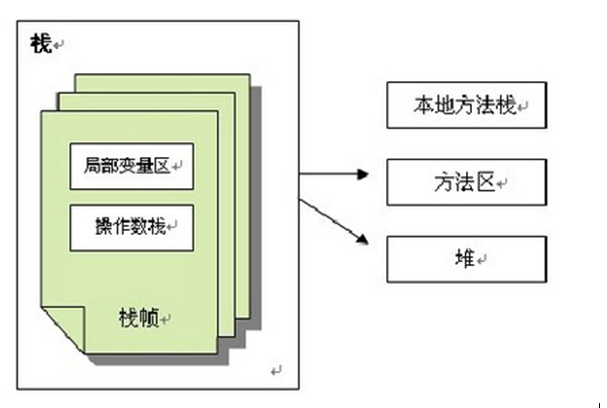
JVMの図に示されている構造からなるスタック、ヒープ、スタック、ローカルメソッド、メソッド領域部によるスタックは、以下:
2. JVMのガベージコレクション
SunのJVMGenerationalCollecting(ガベージコレクション)原則はこれです:異なるアルゴリズムを使用して、異なるライフサイクルの対象に新世代へのオブジェクト(ヤング)、古い年(終身在職権)、恒久的な世代(パーマ)、。(オブジェクトのライフサイクル分析に基づいて)、それは世代のコレクションアルゴリズムです。
A.ヤング(新世代)
新生代は、3つのゾーンに分かれています。エデンエリア、2つのサバイバーエリア。エデンエリアで発生したほとんどのオブジェクト。エデン領域がいっぱいになると、ライブオブジェクトもサバイバーエリア(1の2)にコピーされ、この領域がいっぱいになると、サバイバーは、この分野でのライブオブジェクトは別の領域サバイバーにコピーされ、そしてときサバイバー行きます最初のサバイバー領域からコピーされたフルタイムは、この時点で生きてくると、オブジェクトは古い地区(終身コピーされます。それは注意すべきである、二つのゾーンのサバイバーが対称である、関係はない持っているので、同じ面積オブジェクト上エデンからコピーされ、以前のサバイバーからのオブジェクトがコピーされ、オブジェクトの古い領域にコピーのみ最初のサバイバーから引き継ぐことです存在してもよい。また、チーフ・サバイバーが空であります。
エデン、フォーム、8へのデフォルト率:1:1
。終身B (歳):
生存の古い店の新世代からのオブジェクト。一般的に、古いストアは、オブジェクトの高い生存率、長寿命であるのです。
C.パーマ(永久世代)(jdk1.8で非推奨)
ように静的ファイル、および今のJavaクラス、メソッド、およびを格納するために使用されます。永久世代ガーベジコレクションに有意な効果が、一部のアプリケーションでは、この時点で新しいクラスで実行これらのプロセスを保存するために、比較的大きな永久世代のスペースを設定する必要がある、などHibernateは、として、いくつかまたは動的に生成されたクラスを呼び出すことができます。-XXによって永久的な世代のサイズ:MaxPermSizeを=設定。
例:プログラム内のオブジェクトを生成するとき、それはあまりにも大きなオブジェクトも(これは、プログラムが実行されるたびに10を生成することが観察された古い年に直接生成することができるであれば、通常の被験者は、新世代のスペースが割り当てられますスペースのメガバイト、このメモリ)を直接、古いのとのメッセージの送受信が割り当てられます。スペースの新しい世代は、ガベージコレクションを開始します終了時に、メモリの大部分を回収することができる、メモリの存続一部が回復も完成されたメモリ領域から割り当てられている場合、後の後に繰り返し、サバイバーからの領域にコピーされ、それはなりますが割り当てられますメモリはまた、回収された領域に残りのオブジェクトにコピー生じます。面積が一杯になるまで待つために、ガベージコレクションが再び起こると、古い地区へのオブジェクトのコピーを存続します。
通常、私たちが言う、JVMのガベージコレクションは、常にヒープメモリの回復を意味し、実際に、ヒープの内容のみが動的にアプリケーションに割り当てられているので、新しい世代と古い年の上記目的は、JVMヒープ・スペースを参照している、と恒久的な世代です以前MethodAreaを述べ、ヒープに属していません。
前記ガベージコレクタおよびアルゴリズム
以下の3つのアルゴリズムの選択を行う最初のJVM世代コレクションアルゴリズム、:
| アルゴリズム |
長年 |
機能 |
| マーク - クリア |
歳 |
高い生存率を目標、保証の余分なスペースがありません 低効率、不連続フラグメントの多くを生成します |
| コピー |
新生代 |
利用できるバイナリメモリは、低い生存率の半分のみを使用します |
| マーク - 仕上げ |
歳 |
高い生存率を目標、保証の余分なスペースがありません |
コレクターの概要:
| コレクター名 |
長年 |
アルゴリズム |
シングルスレッド/マルチ |
クライアント/サービス |
シリアル/パラレル/同時 |
機能 |
| シリアル |
新生代 |
レプリケーションのアルゴリズム |
シングル |
クライアント |
シリアル |
チェンインタラクティブ無線、高効率シングルスレッド |
| 新しいのために |
新生代 |
レプリケーションのアルゴリズム |
もっと |
サーバー |
パラレル |
シリアルマルチスレッドバージョン、選択したサーバー、CMSで使用することができます |
| パラレル清掃を |
新生代 |
レプリケーションのアルゴリズム |
もっと
|
サーバー |
パラレル |
スループットは、多くの相互作用を必要としないバックグラウンド動作では機会のために、制御することができます |
| 古いシリアル |
歳 |
マーク - 仕上げ |
シングル |
クライアント |
シリアル |
シリアル歳 |
| 古いパラレル |
歳 |
整理するタグ |
もっと |
サーバー |
パラレル |
パラレルSCAV古いバージョン、PS + PS古い組み合わせ |
| CMS |
歳 |
マーク - クリア |
もっと |
サーバー |
によって複雑 |
最短休止時間を取得し、サービスの応答速度に注意を払います。 ワークフロー: 初期マーク>並行マーク>ラベル変更>同時クリア |
| G-ファースト |
独立した地域の地域 |
マーク - 仕上げ+コピー |
もっと |
サーバー |
並列並行 |
|
4. JDK1.6クラスファイル構造
符号なしと表:Java仮想マシン仕様の下で、クラスファイル形式は、C言語の構造を格納するダミーデータと同様の構造を使用して、データは、2つのタイプに分けられます。
符号なし:1、2、4、8バイトを表すU1 / U2 / U4 / U8に属する基本データ型、主に図面、参照インデックス、値およびストリング値の数を記述するために使用されます。
表:_infoの最後に符号なしの数またはテーブル構成データ項目として他の複合データ型の複数の複合構造の階層関係を記述するためのデータ、クラス全体に対応するテーブル。
テーブル組成物に分けられます。
。マジックナンバーとクラスファイルのバージョン:クラスファイルは、仮想マシンを受け入れることができるかどうかを区別するために使用マジックナンバー。
定数プールB:リテラルの記号によって参照
B.1リテラル:ジャワの一定のレベルと同様に
B.2のシンボル参照:完全修飾名、フィールド名と一致方式記述子の名前と説明。
「」:完全修飾クラスパス、になるだろう「場所に」/;
記述子:実際には、フィールドの型とメソッドのパラメータや戻り値;
。Cのアクセスフラグ:パブリックかどうか、クラスまたはインタフェースを区別し、静的、抽象。
。Dインデックス:インデックスのクラスに分け、親インデックスインデックスセットをインタフェースされ、クラス階層を決定します。
。Eテーブルのフィールド:またはクラス宣言の変数インタフェースはローカル変数の方法に含まれていない説明。
。Fメソッド表:アクセスフラグ、インデックス、記述子属性テーブルの名前が含まれています。
G属性テーブル:コード属性が含まれている、例外の性質、一定値プロパティ、メソッドコードが例外は、例外文をスロー表し、バイトコードにコンパイルされた店舗コードに使用され、一定値静的変数が変更されます。
比較の永久世代5. jdk1.8要素スペース
移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。我们可以通过一段程序来比较 JDK 1.6 与 JDK 1.7及 JDK 1.8 的区别,以字符串常量为例:
package com.xs.test.memory; import java.util.ArrayList; import java.util.List; public class StringOomMock { static String base = "string"; public static void main(String[] args) { List<String> list = new ArrayList<String>(); for (int i=0;i< Integer.MAX_VALUE;i++){ String str = base + base; base = str; list.add(str.intern()); } } }
这段程序以2的指数级不断的生成新的字符串,这样可以比较快速的消耗内存。我们通过 JDK 1.6、JDK 1.7 和 JDK 1.8 分别运行:
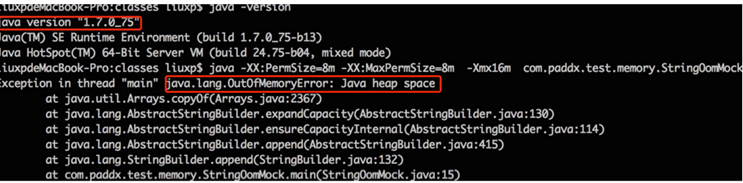
JDK 1.6 的运行结果:

JDK 1.7的运行结果:
JDK 1.8的运行结果:
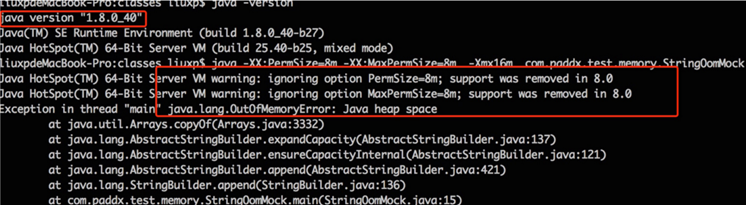
从上述结果可以看出,JDK 1.6下,会出现“PermGen Space”的内存溢出,而在 JDK 1.7和 JDK 1.8 中,会出现堆内存溢出,并且 JDK 1.8中 PermSize 和 MaxPermGen 已经无效。因此,可以大致验证 JDK 1.7 和 1.8 将字符串常量由永久代转移到堆中,并且 JDK 1.8 中已经不存在永久代的结论。现在我们看看元空间到底是一个什么东西?
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与 GC 相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
现在我们在 JDK 8下重新运行一下代码段 4,不过这次不再指定 PermSize 和 MaxPermSize。而是指定 MetaSpaceSize 和 MaxMetaSpaceSize的大小。输出结果如下:
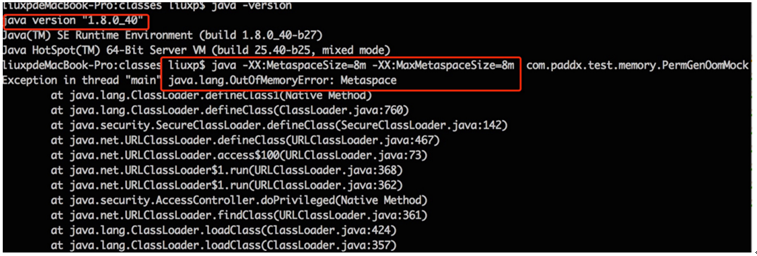
从输出结果,我们可以看出,这次不再出现永久代溢出,而是出现了元空间的溢出。
总结
通过上面分析,大家应该大致了解了 JVM 的内存划分,也清楚了 JDK 8 中永久代向元空间的转换。不过大家应该都有一个疑问,就是为什么要做这个转换?所以,最后给大家总结以下几点原因:
1、字符串存在永久代中,容易出现性能问题和内存溢出。
2、类及方法的信息等比较难确定其大小,因此对于永久代的大小指定比较困难,太小容易出现永久代溢出,太大则容易导致老年代溢出。
3、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低。
4、Oracle 可能会将HotSpot 与 JRockit 合二为一。
本文为博主原创,转载请注明:https://www.cnblogs.com/jiangds/p/11425602.html