主なアイデア:
(1)は、対応するWebページから、「すべての画像タグ」を見つけて
、URLに対応することにより、HTMLコンテンツを取得します。通過した後
BeautifulSoupツリーHTML要素に解析します。
すべての「画像タグ」を検索
(2)画像のダウンロード
、SRCが得るラベルで抽出した画像のアドレスを取得し、画像をダウンロードしてください。

(3)抽出メタ情報EXIF
EXIFに適したライブラリによって達成画像のEXIF情報抽出辞書変数に格納されているトラバース。
これはそこか否かのEXIF情報を判断する(一部は抽出することはできません)、GPSInfo情報(一部の圧縮がかどうかを
紛失したり、持っていたことがありません情報の)、それは満たしていない場合は、画像を削除します。
(4)画像を削除
remove関数のOSを使用して。限り対応するディレクトリがあるとして。これは、削除を達成することができます。
実際にはosモジュールは、WindowsとLinuxの多くの自動化を達成するために使用することができます。

3.まとめモジュールとメソッド
urlparseモジュールは、
このモジュールは、成分ストリングにURL(Uniform Resource Locator)を解析するための標準インタフェースを規定する、コンポーネントバックURL文字列の組み合わせ、および「相対URL(スキーム、ネットワーク上の場所、経路、等をアドレッシング)基本的なURL「は、与えられた絶対URLに変換し、」。」
urlsplitは、同様の機能がurlparse
URL 6つの成分、6タプルリターンを解決します。これは、URLの一般的な構造に対応する:スキーム:// netloc /パス;パラメータ?クエリ#フラグメント。各タプル項目は、おそらく空の文字列です。構成要素は、(例えば、ネットワーク上の場所が単一の文字列である)より小さな部分に分解されず、%エスケープを展開しません。デリミタは、先頭のスラッシュパス成分に加えて、存在する場合、保持され、上記の結果の一部ではありません。
os.path.basename(パス)
パス名pathのベース名を返します。ここで、「/ FOO /バー/」戻り「バー」、ベース名()関数は、空の文字列を返す(「」)のためのベース名。
美しいスープは、
HTMLやXMLファイルPythonライブラリからデータを抽出することができます。あなたが時間または数日を救うために文書を修正お気に入りのコンバータの通常の文書のナビゲーション、検索、道.Beautifulスープを介して達成することができます作業時間
の公式文書ます。https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
一般に、画像処理として使用PILライブラリ公式文書、EXIFを抽出するために、このImage_getexifに使用するプログラム()メソッドが、唯一のJPGとJPEG画像の処理のために
、ケースのサフィックスを特定できない
http://effbot.org/imagingbook/
exiftags .tags(のTagName = TAGS.get(タグ、タグ))
辞書ですが。同様に、このような、あなたが使用してTAGS.get(キー)によって、キーの値で与え得ることができます。存在しない場合、あなたはそれができる持っていることの場合にキーあなたにデフォルト値はSECONDを渡すことによって返し、引数TAGS.get(キー、ヴァル)
出典:http://www.tutorialspoint.com/python/dictionary_get.htm
PIP用いて、exifread、本PNG画像のEXIF情報処理プログラムをインストール
exifread.process_file(画像ファイル)メソッドを
=タグによってexifread.process_fileを(FD)この関数は、形式、EXIFであるEXIFの画像情報を読み出し、
{「イメージImageLength ':(0x0101)3024 = @ 42が短い、
......
'画像GPSInfo '(0x8825)ロング= 792 114 @、
'サムネイルjpeginterchangeformat「(0x0201)ロング@ 808 = 928、
.... ..
}
溶液4.エラー
「STR」オブジェクトが属性が「が読まない」
、実際にはそれ自体が文字列パラメータであり、パラメータ要件はバイナリファイルである
ことにより、(送信される参考ファイル名を渡しますファイルではなく、)ファイル名を開き、
「PngImageFile」オブジェクトが「何の属性がありません _getexif」
_getexifは.PNGファイルの解凍ではないため、エラーがある
解決策を:
あなたが読むためにexifreadモジュールを使用することができますが、しかし、モジュールは、ファイルを.pngを読み取ることができます
そこでは、他のバグが存在し、まだ解決されるが、基本的な使用には影響しません。まだ言わなければならない、
元の著者は、現在のサイトが使用できないため、コードの一部は本当に悪いです書きました
まとめと考え5.
(1)。最終結果は依然としてEXIF情報が不足していないが、そこに暗号化されてもよい、又は
画像自体の一部は、EXIF情報が格納されていません。
(2)一部の画像フォーマット自体は等GIF、JPG、SVGを有し、厳密なフィルタリングを行っていません。
(3)。いくつかのサイトでは、独自の抗登るメカニズムを持って、絵はあなたwww.qq.comとして、クロールすることはできません
II。コード
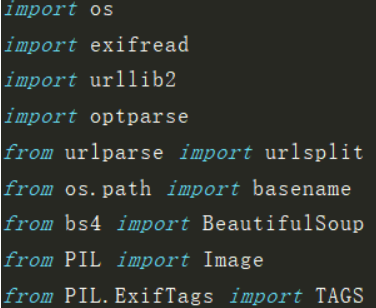
#!/usr/bin/python
# coding: utf-8
import os
import exifread
import urllib2
import optparse
from urlparse import urlsplit
from os.path import basename
from bs4 import BeautifulSoup
from PIL import Image
from PIL.ExifTags import TAGS
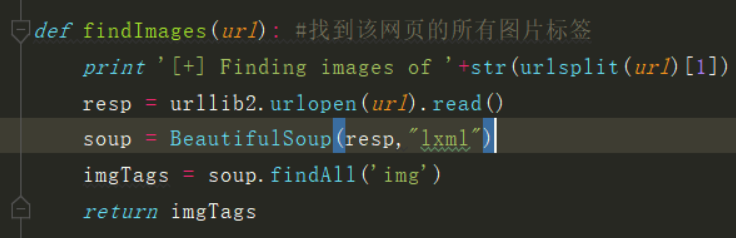
def findImages(url): #找到该网页的所有图片标签
print '[+] Finding images of '+str(urlsplit(url)[1])
resp = urllib2.urlopen(url).read()
soup = BeautifulSoup(resp,"lxml")
imgTags = soup.findAll('img')
return imgTags
def downloadImage(imgTag): #根据标签从该网页下载图片
try:
print '[+] Downloading image...'
imgSrc = imgTag['src']
imgContent = urllib2.urlopen(imgSrc).read()
imgName = basename(urlsplit(imgSrc)[2])
f = open(imgName,'wb')
f.write(imgContent)
f.close()
return imgName
except:
return ''
def delFile(imgName): #删除该目录下下载的文件
os.remove('/mnt/hgfs/temp/temp/python/exercise/'+str(imgName))
print "[+] Del File"
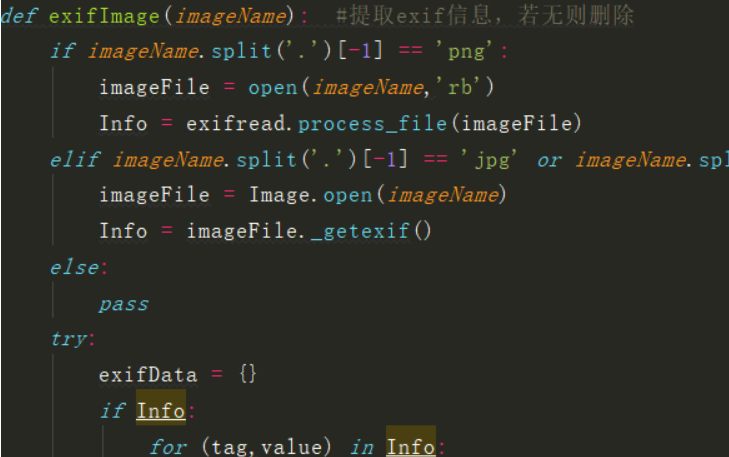
def exifImage(imageName): #提取exif信息,若无则删除
if imageName.split('.')[-1] == 'png':
imageFile = open(imageName,'rb')
Info = exifread.process_file(imageFile)
elif imageName.split('.')[-1] == 'jpg' or imageName.split('.')[-1] == 'jpeg':
imageFile = Image.open(imageName)
Info = imageFile._getexif()
else:
pass
try:
exifData = {}
if Info:
for (tag,value) in Info:
TagName = TAGS.get(tag,tag)
exifData[TagName] = value
exifGPS = exifData['GPSInfo']
if exifGPS:
print '[+] GPS: '+str(exifGPS)
else:
print '[-] No GPS information'
delFile(imageName)
else:
print '[-] Can\'t detecated exif'
delFile(imageName)
except Exception, e:
print e
delFile(imageName)
pass
def main():
parser = optparse.OptionParser('-u <target url>')
parser.add_option('-u',dest='url',type='string',help='specify the target url')
(options,args) = parser.parse_args()
url = options.url
if url == None:
print parser.usage
exit(0)
imgTags = findImages(url)
for imgTag in imgTags:
imgFile = downloadImage(imgTag)
exifImage(imgFile)
if __name__ == '__main__':
main()