ディレクトリ
オリジナル:http://blog.gqylpy.com/gqy/258
「@
*
すべて== Webアプリケーションは、基本的にソケットサーバー==で、ユーザーのブラウザはソケット==顧客サービス== **終わりです:私たちは、この方法でそれを解釈することができます。
私たちは、独自のWebフレームワークを実装することが可能に:
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(9000)
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 响应状态行
conn.send(b'Hello,world!')
conn.close()これは、Webサービス拡張にこのコードは、自分の父親である、コードベースのこのダースラインのうち、本質的にあると言うことができます。
ユーザーのブラウザは、URLを入力すると、サーバーは、ブラウザがどのようなデータを送信します、そのデータを送信しますか?どのように髪?誰がこれを固定しましたか?あなたのウェブサイトは、彼がその条項、インターネットはそれを再生することができたという彼のWebサイトによると、この条項のですか?
我々だけではなく、書くこと、メッセージを送信する形式の根拠がある場合に、メッセージを受け取ることができるように、そのため、均一なルールが存在しなければなりません。
このルールは、HTTPプロトコルであり、ブラウザがイェジンハオ後に要求メッセージを送信し、サーバは言及する価値が応答情報を返信、この規則に従ってください。
クライアントとサーバ間のHTTPプロトコルの通信フォーマットの主な条項、メッセージ形式がそれを規定する方法であるHTTPプロトコル?
私たちがしているサービス終了で受信したメッセージ何を最初に印刷してみましょう:
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(9000)
print(data) # 将浏览器发来的消息打印出来
conn.send(b'HTTP/1.1 200 OK\r\n\r\n')
conn.send(b'Hello,world!')
conn.close()次のように出力されます。
b'GET / HTTP / 1.1 \ rを\ nHost:127.0.0.1:8080\r\nConnection:キープアライブ\ rを\ nPragma:キャッシュなし\ rを\のnCache-コントロール:キャッシュなし\ rを\ nUpgrade-Insecure-要求:1 \ rを\ nユーザーエージェント:Mozillaの/ 5.0(Macintosh版、インテルのMac OS X 10_13_6)のAppleWebKit / 537.36(KHTML、ヤモリなど)クローム/ 68.0.3440.106サファリ/ 537.36 \ rを\ nAccept:text / htmlで、アプリケーション/ XHTML + xmlの、アプリケーション/ XML、Q = 0.9、画像/ WEBP、画像/ APNG、/ ; Q = 0.8 \ R \ nAcceptエンコーディング:gzipで、収縮、BR \ R \ nAccept言語:ZH-CN、ZH。 Q = 0.9、EN; Q = 0.8 \ R \のn個の\ r \ n」
その後、我々は、応答に関する情報は、ネットワークブラウザタブデバッグウィンドウで見ることができ、私たちが受けているもののブログ公式Webブラウザへのアクセス情報に応答が表示されます。
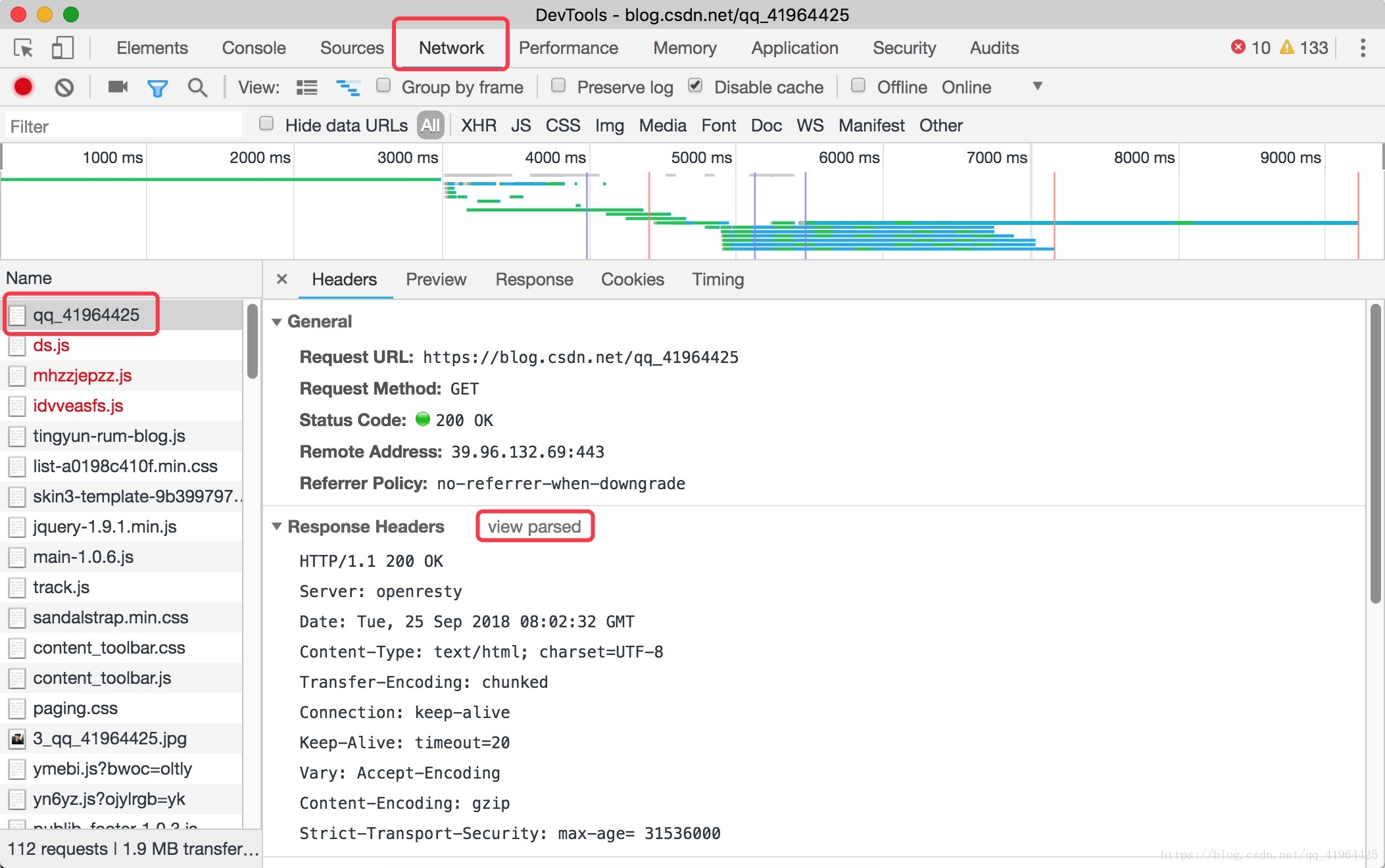
私たちは、特定のフォーマットに従って送信され、受信したメッセージを見つける必要があり、ここでは、HTTPプロトコルを知ることが必要です。
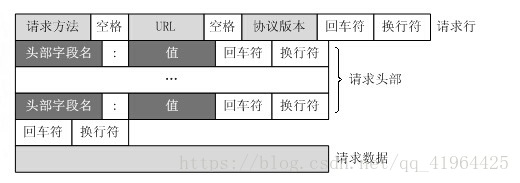
ボディはオプションである各HTTP要求と応答は、2つの部分を含む同じフォーマット、HTTPヘッダとボディをたどります。ヘッダーHTTP応答は、応答の==のContent-Typeの==ショーのコンテンツフォーマットを持っています。== text / htmlのよう== HTMLページを表しています。
HTTP GETリクエストのフォーマット:
HTTPレスポンス形式:
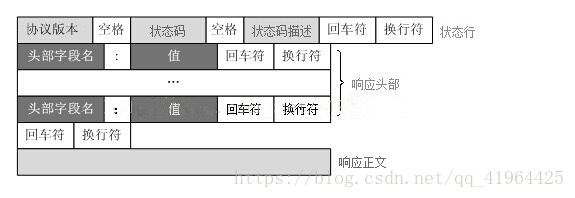
****
パスに応じて異なるコンテンツを返します。
版
==アイデア:要求データ、そこから経路要求URLを取得し、==パスを取る判断をします。
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(8096)
# 把收到的字节类型的数据转换成字符串
data_str = str(data, encoding='UTF-8')
first_line = data_str.split('\r\n')[0] # 按\r\n分隔
url = first_line.split()[1] # 在按空格切割
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 响应状态行
if url == '/index':
response = 'index'
elif url == '/home':
response = 'home'
else:
response = '404 not found!'
conn.send(bytes(response, encoding='UTF-8'))
conn.close()上面的代码解决了对于不同URL路径返回不同内容的需求。
但是问题又来了,如果有很多的路径要判断怎么办呢?难道要挨个写if判断?
答案是否定的,我们有更聪明的办法:
函数版
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
# 将返回不同的内容部分封装成函数
def index(url):
s = "这是%s页面!" % url
return bytes(s, encoding='UTF-8')
def home(url):
s = "这是%s页面!" % url
return bytes(s, encoding='UTF-8')
while True:
conn, addr = sk.accept()
data = conn.recv(8096)
# 把收到的字节类型的数据转换成字符串
data_str = str(data, encoding='UTF-8')
first_line = data_str.split('\r\n')[0] # 按\r\n分隔
url = first_line.split()[1] # 在按空格切割
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 响应状态行
if url == '/index':
response = index(url)
elif url == '/home':
response = home(url)
else:
response = b'404 not found!'
conn.send(response)
conn.close()
看起来上面的代码还是要挨个写if判断,怎么办?
只要思想不滑坡,方法总比问题多,走着!
函数进阶版
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
# 将返回不同的内容部分封装成函数
def index(url):
s = "这是%s页面!" % url
return bytes(s, encoding='UTF-8')
def home(url):
s = "这是%s页面!" % url
return bytes(s, encoding='UTF-8')
# 定义一个url和实际要执行的函数的对应关系
url_list = [
('/index', index),
('/home', home)
]
while True:
conn, addr = sk.accept()
data = conn.recv(8096)
# 把收到的字节类型的数据转换成字符串
data_str = ?tr(data, encoding='UTF-8')
first_line = data_str.split('\r\n')[0] # 按\r\n分隔
url = first_line.split()[1] # 在按空格切割
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 响应状态行
# -------关键就在于这一坨代码-------
func = None
for i in url_list:
if url == i[0]:
func = i[1]
break
response = func(url) if func else b'404 not found!'
conn.send(response)
conn.close()完美解决了不同URL返回不同内容的问题。
但是我们不仅仅是想返回几个字符串,我们想给浏览器返回完整的HTML内容,这又该怎么办呢?接着走!
***
返回具体的HTML文件
首先我们要知道:==不管是什么内容,最后都是转换成字节数据发送出去的.==
那么,我们可以以二进制形式打开HTML文件,读取文件的数据,然后再发送给浏览器.
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
# 将返回不同的内容部分封装成函数
def index(url):
with open('index.html', 'rb') as f: return f.read()
def home(url):
with open('home.html', 'rb') as f: return f.read()
# 定义一个url和实际要执行的函数的对应关系
url_list = [
('/index', index),
('/home', home)
]
while True:
# ------------ 建立连接 接收消息 ------------
conn, addr = sk.accept()
data = conn.recv(8096)
# ------------ 对客服端发来的消息做处理 ------------
# 把收到的字节类型的数据转换成字符串
data_str = str(data, encoding='UTF-8')
first_line = data_str.split('\r\n')[0] # 按\r\n分隔
url = first_line.split()[1] # 在按空格切割
# ------------ 业务逻辑处理部分 ------------
func = None
for i in url_list:
if url == i[0]:
func = i[1]
break
response = func(url) if func else b'404 not found!'
# ----------- 回复响应消息 -----------
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 响应状态行
conn.send(response)
conn.close()没错,还有问题!
这网页是能够显示出来了,但都是静态的啊,页面的内容不会变化,我们想要的是动态网站!
***
让网页动态起来
==思路:使用字符串替换功能来实现这个需求.==
这里我们是使用当前时间来模拟动态的数据
login函数对应文件:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta http-equiv="content-Type" charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>login</title>
</head>
<body>
<h1>登录页面</h1>
<h1>This is login page!</h1>
<a href="https://blog.csdn.net/qq_41964425/article/category/8083068" target="_blank">CSDN</a>
<p>时间:@@xx@@</p> <!--提前定义好特殊符号-->
</body>
</html>Python代码:
from time import strftime
from socket import *
sk = socket(AF_INET, SOCK_STREAM)
sk.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
sk.bind(('127.0.0.1', 8080))
sk.listen()
# 将返回不同的内容部分封装成函数
def index(url):
with open('index.html', 'rb') as f: return f.read()
def home(url):
with open('home.html', 'rb') as f: return f.read()
# 实现动态网页
def login(url):
now_time = str(strftime('%F %T'))
with open('login.html', 'r', encoding='UTF-8') as f:
s = f.read()
# 在网页中定义好特殊符号,用动态的数据去替换定义好的特殊符号
s = s.replace('@@xx@@', now_time)
return bytes(s, encoding='UTF-8')
# 定义一个url和实际要执行的函数的对应关系
url_list = [
('/index', index),
('/home', home),
('/login', login),
]
while True:
# ------------ 建立连接 接收消息 ------------
conn, addr = sk.accept()
data = conn.recv(8096)
# ------------ 对客服端发来的消息做处理 ------------
# 把收到的字节类型的数据转换成字符串
data_str = str(data, encoding='UTF-8')
first_line = data_str.split('\r\n')[0] # 按\r\n分隔
url = first_line.split()[1] # 在按空格切割
# ------------ 业务逻辑处理部分 ------------
func = None
for i in url_list:
if url == i[0]:
func = i[1]
break
response = func(url) if func else b'404 not found!'
# ----------- 回复响应消息 -----------
conn.send(b'HTTP/1.1 200 OK\r\n\r\n') # 响应状态行
conn.send(response)
conn.close()服务器和应用程序
对于开发中的python web程序来说,一般会分为两部分:==服务器程序和应用程序.==
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理;应用程序则负责具体的逻辑处理.
为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py等。不同的框架有不同的开发方式,但是无论如何,开发出来的应用程序都要和服务器程序配合,才能为用户提供服务。
如此,服务器程序就需要为不同的框架提供不同的支持。这样混乱的局面无论是对于服务器还是框架,都是不好的。
このとき、標準化が特に重要になり、私たちは、限り、サーバーがこの標準をサポートしているように、フレームワークはまた、彼らは一緒に使用することができ、この標準をサポートして、標準を設定することができます。標準が決定されると、当事者のそれぞれが実現しています。
WSGI(Webサーバゲートウェイインターフェース)は、仕様です。これは、WebアプリケーションとWebサーバプログラム間のデカップリング、PythonのWebアプリケーションとWebサーバプログラムで記述されたフォーマット間のインタフェースを定義します。
一般的に使用されるWSGIサーバはGunicorn、uwsgiています。wsgirefと呼ばれるWSGIサーバの独立したPythonの標準ライブラリには、== Djangoの開発環境は、サーバーを行うには、このモジュールを使用することである。==
wsgirefモジュール
wsgirefモジュールを使用して私たち自身のWebフレームワークのソケットサーバーの一部を書き置き換えます。
ログイン機能は、ファイルに対応しています。
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta http-equiv="content-Type" charset="UTF-8">
<meta http-equiv="x-ua-compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>login</title>
</head>
<body>
<h1>登录页面</h1>
<h1>This is login page!</h1>
<a href="https://blog.csdn.net/qq_41964425/article/category/8083068" target="_blank">CSDN</a>
<p>时间:@@xx@@</p> <!--提前定义好特殊符号-->
</body>
</html>Pythonコード:
from time import strftime
from wsgiref.simple_server import make_server
# 将返回不同的内容部分封装成函数
def index(url):
with open('index.html', 'rb') as f: return f.read()
def home(url):
with open('home.html', 'rb') as f: return f.read()
def login(url):
"""实现动态网页"""
now_time = str(strftime('%F %T')) # 获取当前格式化时间
with open('login.html', 'r', encoding='UTF-8') as f:
s = f.read()
# 在网页中定义好特殊符号,用动态的数据去替换定义好的特殊符号
s = s.replace('@@xx@@', now_time)
return bytes(s, encoding='UTF-8')
# 定义一个url和实际要执行的函数的对应关系
url_list = [
('/index', index),
('/home', home),
('/login', login),
]
def run_server(environ, start_response):
# 设置HTTP响应的状态码和头消息
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ])
url = environ['PATH_INFO'] # 取到用户输入的url
func = None
for i in url_list:
if url == i[0]:
func = i[1]
break
response = func(url) if func else b'404 not found!'
return [response, ]
if __name__ == '__main__':
httpd = make_server('127.0.0.1', 8080, run_server)
print('Wsgiref has started...')
httpd.serve_forever()
"