最長の上昇シーケンス(LIS)
LIS(最長増やすサブシーケンスが)最も長いシーケンスのバラ
B1 <B2 <... <BS時間、我々は呼んでこのシーケンスが上昇しているとき、シーケンスに双方向の数を。
所定の配列について(A1、A2、...、AN)は、我々はいくつかの逆シーケンス(AI1、AI2、...、AIK)を取得することができ、
1 <= I1 <I2 <... <IK <= N.
例えば、のようないくつかの配列を、上昇系列(1、7、3、5、9、4、8)、(1、7)、(3、4、8)などが挙げられます。
最長シーケンスの長さは、このようなシーケンス(1、3、5、8)のように、4である。
あなたの仕事は、与えられた配列、最長立ち上がり決定された配列の長さです。
2つのアルゴリズム:
1:O(N ^ 2):
状態設計:DP [I]についての代表的な[I] LIS長の終了時に
状態遷移:DP [I] = MAX( DP [I]、DP [J] +1)(0 <= jの<I、[ J] <[i])と
境界処理:DP [I] = 1( 0 <= J <N)
コード:
1 INT LIS() 2 { 3 int型 ANS = 1 。 4 のための(int型 i = 1 ; iが<= N iが++ ) 5 { 6 DP [I] = 1 。 7 のための(INT J = 1 <; J I J ++ ) 8 { 9 もし([I]> [J]) 10 DP [I] = MAX(DP [I]、DP [J] + 1 )。 11 } 12 } 13 のために(INTi = 1 ; iは= <N; iは++ ) 14の ANS = MAX(ANS、DP [I])。 15の リターンANS; 16 }
2:ピギー半分+
[i]はi番目のデータです。
DP [i]は要素I + 1のLIS端によって表される最小の長さを表します。
上昇シーケンスのための貪欲アイデアは、そのようなLIS自然長より長く、新しい要素を追加するためのより良い、より小さなの現在の最後の要素は明らかです。
したがって、我々は、その一つ一つ最小値を保証するために、LISの最小の長さを表し、DPアレイは、素子I + 1の終わりで維持する必要があります
この方法では、配列の長さDP LIS長です。
特定の保守手順のDP配列はまた、より明確に説明するための例です。
同じシーケンス(1、7、3、 5、9、4、8)、 DP変更処理は以下の通りであります:
- DP [0] [0] = 1、LIS要素の端部の最小長さは、自然を選択する必要はありませんでした=最初の数です。(DP = {1})
- [1] 7、[1]> DP [0] =、したがって直接DPの末尾に追加するために、DP [1] [1] =。(DP = {1,7})
- [2] = 3、DPのために[0] <[2] <DP [1]ので、[2]あるいはDP [1]、DPなる[1] = [2]、2の長さはLIS、要素の終わりはあまりそれは、新しい要素を追加するには良いのフォローアップがあるので、3 7あまりにも自然に良いです。(DP = {1,3})
- [3] = 5、[3]> DP [1]、このように直接DPの最後に追加、DP [2] [3] =。(DP = {1、3、5})
- [4] = 9、[4]> DP [2]、従ってまたDPの端部に直接添加するために、DP [3] [9] =。(DP = {1、3、5、9})
- [5] 4 =ため、DP [1] <[5] <DP [2]、そう[5] DP 5の代わりに値[2]、従ってLIS 3、4の長さは、要素を終了します5よりも良い、小さいより良いもの。(DP = {1、3、4、9})
- [6] = 8、DP [2] <[6] <DP [3]は、同様に[6]あるいは値DP 9 [3]、あなたが知っている理由。(DP = {1、3、5、8})
完全なDPを維持するために、このようなサブアレイ、DPは、アレイLIS 4の必要な長さの長さです。
上記を解くことにより、アレイは、DPが単調増加、したがって各あるか否かを見出すことができる[i]は、直接配列DPの端部に挿入されるように決定されます
すなわち、最後の、すなわち、アレイとDP比較の最大値が、そうでない場合には、以上最初のDPの位置を見出す[I]及び[I]で置き換えました。
検索時間の複雑さは、O(logN個)となるように合計時間複雑度は、O(N * logN個)であるように、このプロセスは、二分探索を利用することができます
1 INT LIS() 2 { 3 のmemset(DP、INF、はsizeof (DP))。 4つの int型の POS = 0 。 5 DP [ 0 ] = [ 0 ]。 6 のために(int型 i = 1 ; iは<; N = iは++ ) 7 { 8が あれば([I]> DP [POS]) 9 DP [++ posは] = [I]。 10 他 11 DP [LOWER_BOUND(DP、DP + POS + 1、[I]) - DP = [i]は、 12 } 13 返す POS + 1を、 14 }
II。最長共通部分列(LCS)
二つの文字列では、同じ文字のいくつかは、形成することもできる配列が同じであってもよく、したがって、2つの間の最長の共通部分列の最も長い単語列の長さが同じで、動的プログラミングを使用できるの長さを見つけるために。
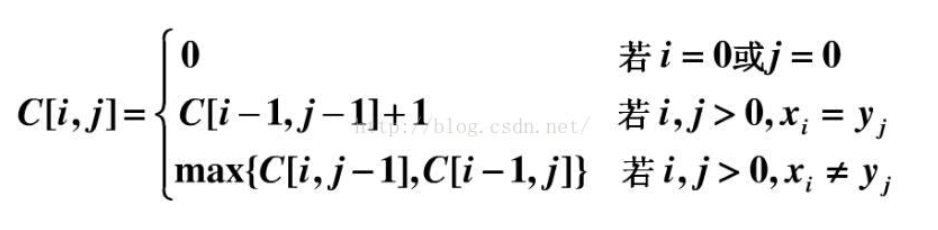
1 INT LCS() 2 { 3 のmemset(DP、0、はsizeof (DP))。 4 のための(int型 i = 1 ; iが<= N iが++ ) 5 { 6 のための(INT J = 1 ; J <= N; J ++ ) 7 { 8 た場合([I- 1 ] == B [J- 1 ]) 9 DP [I] [J] = MAX(DP [I]、[J]、DP [I- 1 ] [J- 1 ] + 1 )。 10 他 11 DP [I] [J] = MAX(DP [I- 1 ] [j]は、DP [I]、[J- 1 ])。 12 } 13 } 14 リターンDP [n]は[N]。 15 }
III。最長共通サブ上昇(LCISです)
1:O(N ^ 3)
;分析[I] [J]が最後にB [j]のように表現F、共通サブシーケンスの最大文字列長は、[i]は前増加
F [I] [J]:明らか > = F [I-1]を[ J] ;;
再帰:[i]は= bの[Jの場合 :[i] [j]はfは= F [I-1 [J]!];
[i]を== B [Jの場合 ]:F [ I] [J] = MAX( F [k]は[J])+ 1(1 <= K <= J-1 && B [J]> B [K])
1 INT LCIS() 2 { 3 int型 ANS = 0 。 4 のための(int型 i = 1 ; iが<= N iが++ ) 5 { 6 ため(INT J = 1 ; J <= N; J ++ ) 7 { 8 であれば(![I] = B [J])DP [ I] [j]はDP [I-を= 1 ] [J]。 9 他の 10 { 11 INT MAXX = 0 。 12 のための(int型 K = 1 K <J; kは++) 13 { 14 であれば(B [J]> B [K]) 15 MAXX = MAX(MAXX、DPは[I- 1 ] [K])。 16 } 17 DP [I] [j]はMAXX + = 1 。 18の ANS = MAX(DP [I]、[J]、ANS)。 19 } 20 } 21 } 22の リターンANS。 23 }
2:O(N ^ 2)
最適化:この配列のミリメートルを記録することによって記録しながら最大の上昇を一致させるプロセスの[i]とB [1-M]、側面を更新する、減少次元について
1 空隙LCIS() 2 { 3 のための(int型 i = 1 ; iがn = <; iは++ ) 4 { 5 INT MAXX = 0 。 6 用(INT J = 1 ; J <= N; J ++ ) 7 { 8 DP [I] [J] = DP [I- 1 ] [J]。 9 もし([I]> [J] B) 10 MAXX = MAX(MAXX、DP [I- 1 ] [J])。 11 であれば([I] == B [J]) 12 DP [i] [j]はMAXX + = 1 。 13 } 14 } 15 INT ANS = 0 。 16 のためには、(int型 i = 1 ; iが<= N; iが++ ) 17の ANS = MAX(ANS、DP [n]を[I])。 18の リターンANS; 19 }