転載:https://www.cnblogs.com/huamingao/p/5809936.html
コアのヒント:
不変タイプ対変数の型
変数の型(可変):リスト、辞書
不変タイプ(unmutable):数値、文字列、タプル
内容(値)の部分をメモリに変更することができるかどうかを指し、可変不変本明細書
コード:
NAME1 = ' wupeiqi ' NAME2 = NAME1 プリント(" NAME1:%sの\ nname2:%sの"%(NAME1、NAME2)) NAME1 = ' アレックス' プリント("私は何が起こるか見さんをnew_name.LetするNAME1の名前を変更しました!" )
印刷(" NAME1:%sの\ nname2:%sの" %(NAME1、NAME2))
結果:
C:/パーソナル/ OldboyPython / day01 / test.py NAME1:wupeiqi 名2:wupeiqi 私はnew_name.LetにNAME1の名前を変更した" の何が起こるかを参照してください! NAME1:アレックス 名2:wupeiqi
質問:なぜ値が一緒に、name1とアレックスなっNAME2ていないのですか?ここでは、まだ答えが、チャートを見て、後で説明します。
以下はhttp://www.cnblogs.com/wupeiqi/articles/5433925.htmlから引用されています
変数の代入
#!は/ usr / binに/のenv pythonの #- * -コーディング:UTF-8 - * - NAME1 = " wupeiqi " NAME2 = " アレックス"
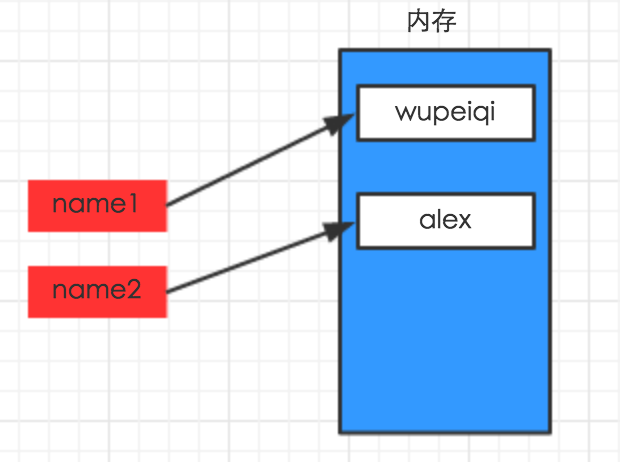
#!は/ usr / binに/ envをPythonの #- * -コーディング:UTF-8 - * - NAME1 = " wupeiqi " NAME2 = NAME1 #、同じオブジェクトに割り当てられた名前2とNAME1ポイントを作るだけで、元のメモリを指す変数を作成住所、
1.参照カウントの減少
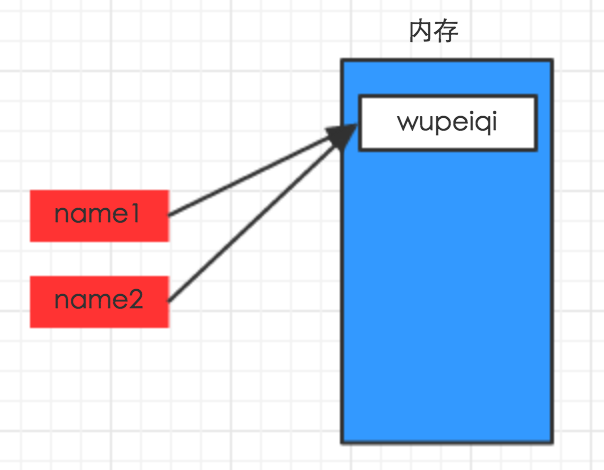
オブジェクトwupeiqi(図wupeiqiメモリブロック内の青)が最初に作成されたとき、および(その参照)変数NAME1に割り当てられた場合、オブジェクトwupeiqiの参照カウントは1に設定されています。
オブジェクトアレックス(図アレックス・メモリ・ブロック内の青)が最初に作成され、(その参照)変数NAME2に割り当てられている場合、オブジェクトアレックスの参照カウントは1に設定されています。
可変NAME2(NAME2 = NAME1)に割り当てられた変数NAME1は、実際NAME2に割り当てられたターゲットwupeiqiである場合、ゼロに減少従ってオブジェクトwupeiqi参照自動的に1だけインクリメント数、及びオブジェクトアレックスの参照カウントをデクリメント、すなわち、トリガガベージコレクションメカニズム。
不変タイプ対2変数タイプ
変数の型(可変):リスト、辞書
不変タイプ(unmutable):数値、文字列、タプル
変数不変本明細書では、コンテンツ(値)の部分をメモリに変更することができるかどうかを指します。それはオブジェクト自体の動作時に、不変である場合は、(旧エリアの##不変ので)、メモリ内の新しいエリアを申請しなければなりません。それはオブジェクト操作時の変数の型である場合、このオブジェクト(+/-)の連続適用が可能ちょうど後ろ、つまり、そのアドレスは同じままになりますが、エリアは意志、メモリ内の他の場所で適用する必要はありません長いか短いです。
あなたは、変更前と変更は、2つの割り当てで発生した後のオブジェクトの身元を確認するために、組み込み関数のIDを()を使用することができます。例を見ることがhttp://blog.chinaunix.net/uid-26249349-id-3080279.html
*不可变类型有什么好处?如果数据是不可变类型,当我们把数据传给一个不了解的API时,可以确保我们的数据不会被修改。如果我们要操作一个从函数返回的元组,可以通过内建函数list()把它转换成一个列表。(当被问到列表和元组的区别时,可以说这一点!)
3. 深拷贝 Vs 浅拷贝
copy.copy() 浅拷贝
copy.deepcopy() 深拷贝
浅拷贝是新创建了一个跟原对象一样的类型,但是其内容是对原对象元素的引用。这个拷贝的对象本身是新的,但内容不是。拷贝序列类型对象(列表\元组)时,默认是浅拷贝。
以下引用自http://www.cnblogs.com/wupeiqi/articles/5433925.html
赋值,只是创建一个变量,该变量指向原来内存地址,如下例:
n4 = n3 = n2 = n1 = "123/'Wu'"

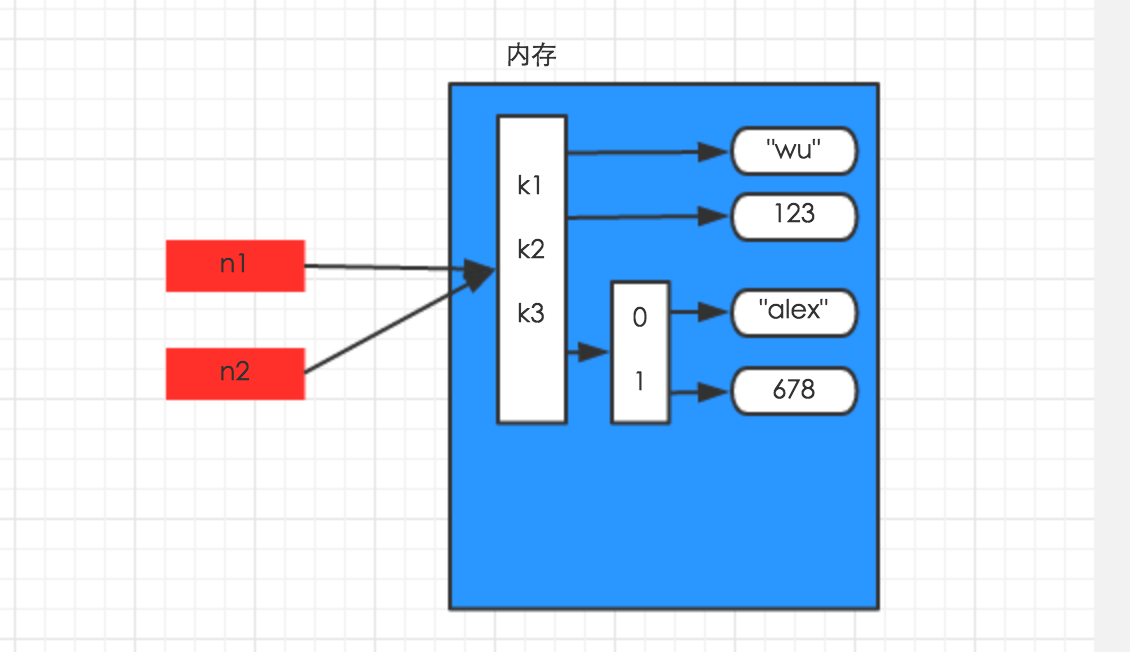
关于赋值,再看一个字典的例子:
n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 678]}
n2 = n1
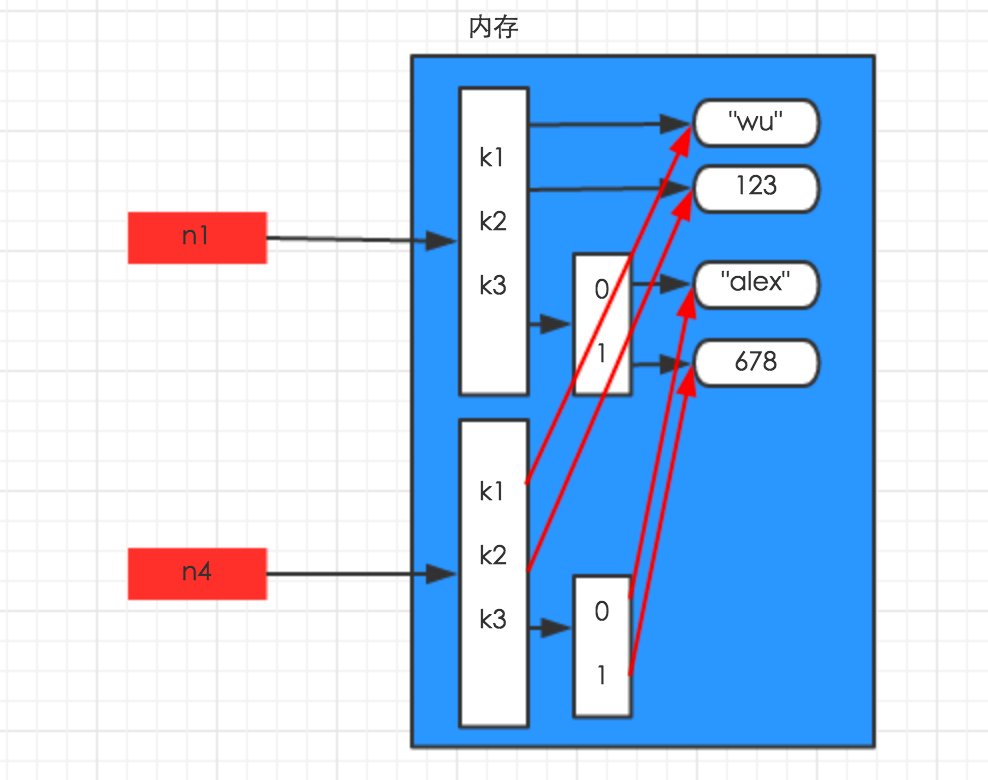
浅拷贝,在内存中只额外创建第一层数据,如下图

深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化),如下图:
import copy n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]} n4 = copy.deepcopy(n1)