インターネットへのデータの量が増加すると、データ量の単一のテーブルに多くの何百万人もの既に何百、あるいはそれ以上、この単一のデータテーブルは、ボトルネックのクエリに達している、我々はデータベースを分割する必要があります。
どのように効果的な、それはデータベースを分割され、インターネット企業は、データベース処理のためにシャットダウンビジネスのボリュームの影響ので、非常に現実的ではありません。その後、我々は解決するためのより良い方法が必要です。
まず、最初にテーブル構造は同じデータベースを設定され、準備ができてデータベースを取得する必要があります。古いデータベースのCRUD操作は、操作の後、新しいデータの追加および削除を倍増するサービスを通じて引き続き続けています。データベース内の看板に記録され、その後、古いデータベーステーブルからデータを同期するツールを書き込むことにより、古いデータベースのフラグの前にデータを新しいデータベースに同期されます。示すように、結果:
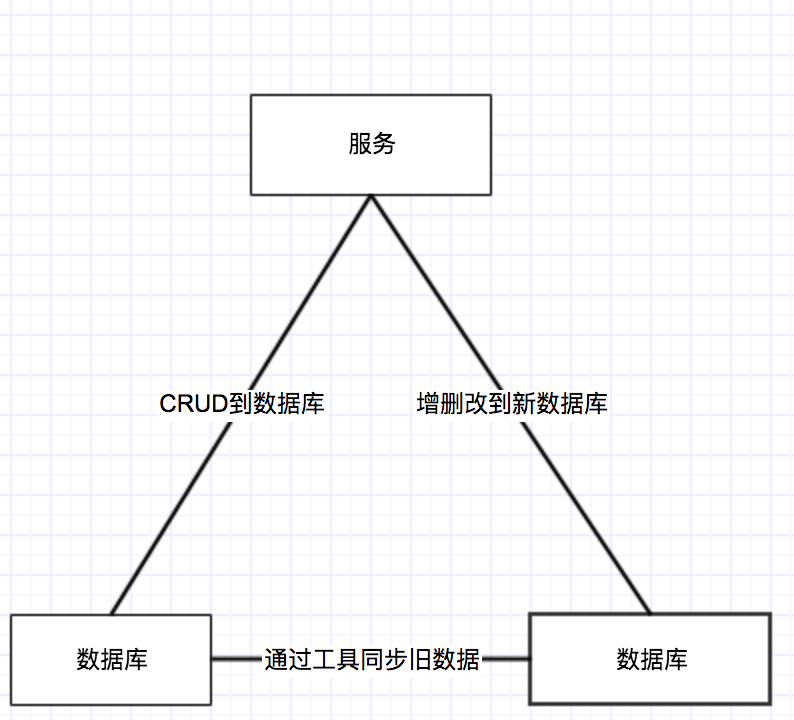
古いデータベースからのデータは時間的に同期されている間、そのような新しく生成されたデータは、新しいライブラリに書き込まれます。
データの同期化は、次の2台のマシンにリンクされた2人の仮想IPまたはドメイン名を適用し、あれば、問題はありません、すべてのデータが終了した後にさらに検討が必要です。
そのようなデータベースは、データベースは、2つになり、ハッシュテーブル内の2つのデータベースフィールドは、ハッシュ結果が0の最初のデータベースに到達するために、データベースのハッシュ結果が来ます。結果は以下の通りであります:
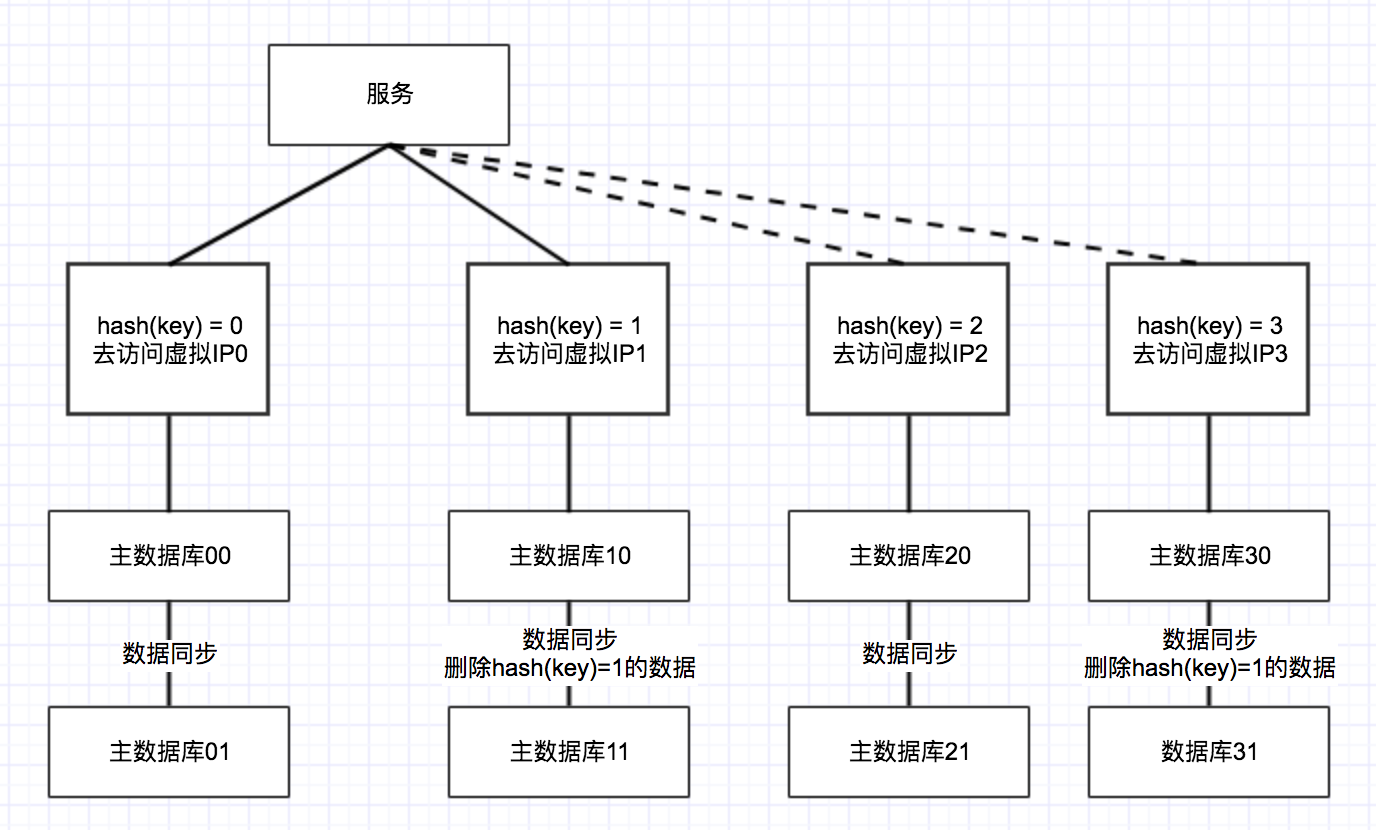
ハンドオーバー時には、データベースは、このように直接ZKの構成に切り替える必要があります。2つのデータベースは古いデータベースに切り替えることが時宜を得て、新たなライブラリデータの問題の出現を防ぐために、二重の書き込み、読み続けることができますが、この時点では、一週間程度を観察する必要があります。
何の問題が一週間後に存在しない場合は、データの分離を達成するために、削除さ倍増されます。
データベースが完全に分離されていないこの時間は、データベース内の(キー)= 0を有し、依然としてデータのハッシュ(キー)= 1、次いでアウトそのようなデータを削除する必要があります。このように、2つのプール、および2つのデータベースそれぞれ5000万のそれぞれへのデータの何百万、数百。
別々のデータベースの後だけでなく、変化に対応する後続の統計の結果は、メモリに結果を計算する必要があり、その後まとめると、得られた結果と統計的分析に計算した結果。
行ってサービスを切り替え、ダウンタイムなしのデータベースのこの基本的な実現。
データベースの問題がある場合、我々はまた、直接、その後、タスクの同期、仮想IPアクセス時間を介して2つのデータライブラリとの間の主な図書館、メイン図書館、高可用性を実現するために、上の図ということに注意してください彼は別のデータベースを受けました。
未来的话,需要再需要继续扩容的话,还需要以2*n的库进行扩容,这样has(key) = 0 和 hash(key) = 2数据保持一致, hash(key) = 1 和 hash(key) = 3数据一致。当数据同步完成之后0,2就可以按照上述的方法进行拆分,然后拆为两个虚拟IP,同时将hash(key)=2的数据从数据库 hash(key)= 0的数据库删除掉,1、3相同的原理,这样数据库就实现了同步。
同学们有没有更好的方法?可以和我一起讨论。当然咱们还有一些分库分表比较成熟的工具比如ShardingSphere和MyCAT,这些工具都是比较好的分库分表解决方案,当然在使用之前一定要做好功课,避免使用的时候采坑。
有问题欢迎来拍~