SparkSqlハイブの統合
ハイブ必要メタデータ、Mysqlのレーンに保存されているハイブメタデータは、sparkSqlは糸を交換し、糸を起動していない、我々はHDFSを起動する必要があります
まず、高可用性のHadoop飼育係、だけでなく、DFS(Hadoopの中)があるように持っていたならば、あなたは、火花を持っている必要があり、ハイブを持っている必要があります
私は3つのノードを持っているnode01、node02で、node03の
PS:DATEDIFF(A、B)の差分セットを行います
node01
のハイブ-site.xmlの設定火花への最初のコピーハイブ
CPハイブ-site.xmlの/export/servers/hive-1.1.0-cdh5.14.0/conf/hive-site.xml /export/servers/spark-2.0.2/conf/
そして、他のノードSCPにconfigディレクトリをスパーク
SCP hive- のsite.xmlとnode02:$ PWD
SCPハイブ -site.xml node03の:$ PWD

CP /export/servers/hive-1.1.0-cdh5.14.0/lib/mysql-connector-java-5.1.38.jar /export/servers/spark-2.0.2/jars/
他のノードのスパークディレクトリにドライブのMySQLのコピー
まずスパーク/瓶ディレクトリに
CDの/export/servers/spark-2.0.2/jars/
コピー(私は自由にログインして閉じ、そしてホスト名マッピングのIP)
SCP mysqlのコネクタ-javaの-5.1.38.jarとnode02:$ PWD
SCPのMySQLコネクタ - Javaベース5.1.38.jarのnode03の:$ PWD

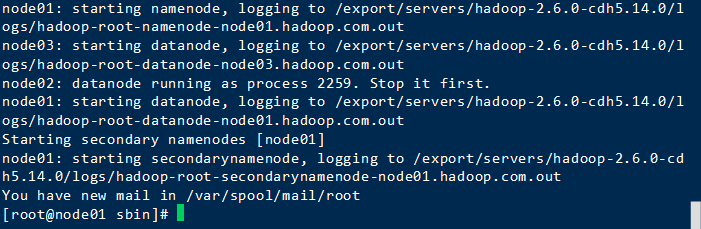
質問はHDFSファイルにテストされますので、あなたは、DFSを開始する必要があるため、糸を起動していません
Hadoopの/ sbinディレクトリを入力した後、スタート
./start-dfs.sh
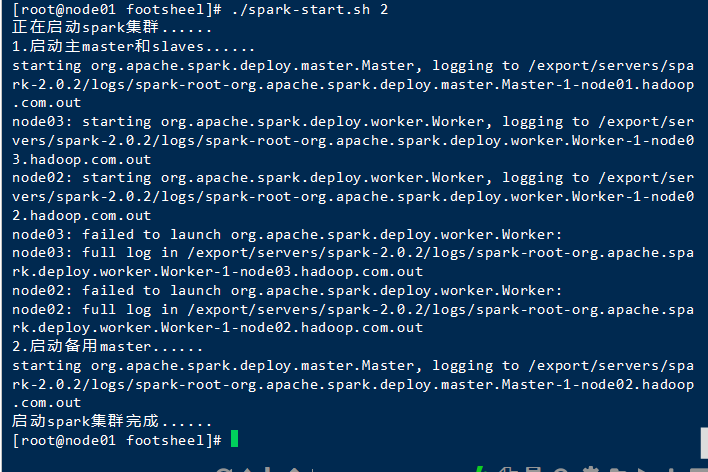
(私はパッケージスクリプト=>に入れてスパーククラスタを起動し、私は保留をダウンロード]をクリックし、必要に応じて)
スクリプトを起動
./spark-start.sh 2
テスト
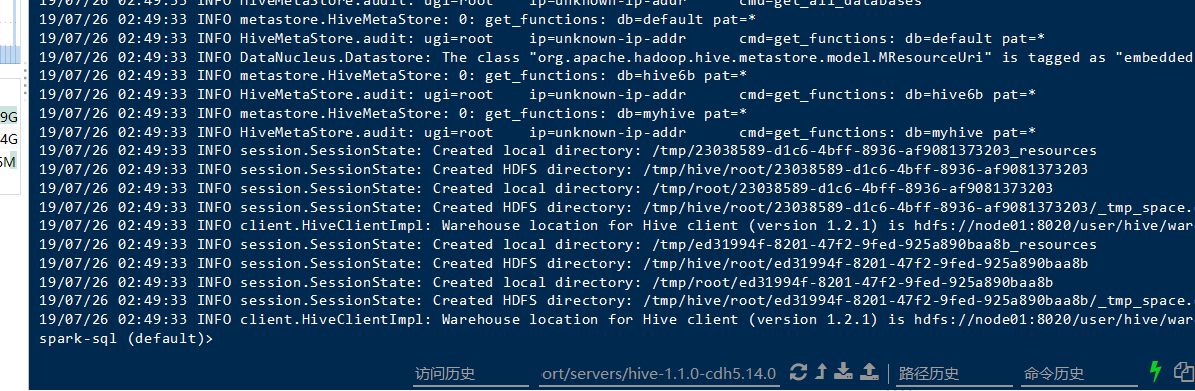
火花防止型のSQL \ :スパーク--master // \ 7077:node01 --executor- \メモリ1グラム --total-エグゼキュータ・コア2 \ --conf spark.sql.warehouse.dir = HDFS:// node01:8020 /ユーザー/ハイブ/倉庫/ myhive.db
失敗しました。
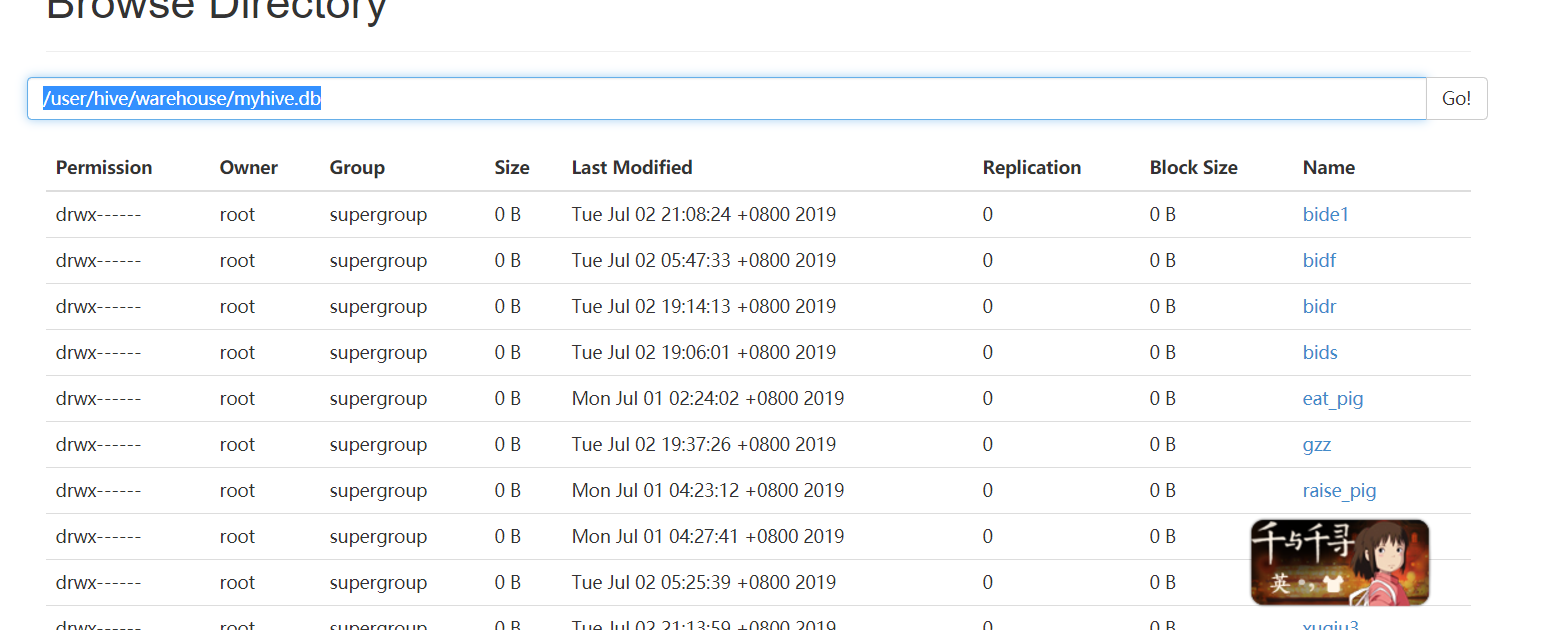

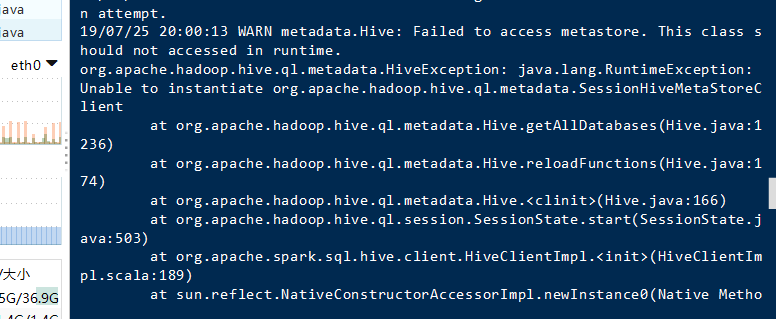
前に私が統合し、インパラしなければならなかったので、理由コードのこの行は、間違っているが、私はインパラを開始しませんでした。
ソリューション
node01入力してください
ハイブ/ confにハイブ-site.xmlのを開きます。
注記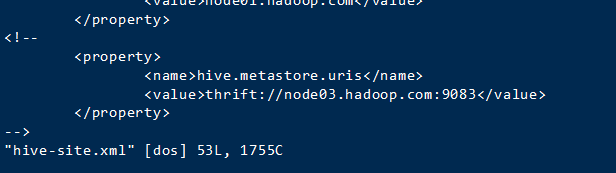
再起動
火花防止型のSQL \ :スパーク--master // \ 7077:node01 --executor- \メモリ1グラム --total-エグゼキュータ・コア2 \ --conf spark.sql.warehouse.dir = HDFS:// node01:8020 /ユーザー/ハイブ/倉庫/ myhive.db
成功